一、扩缩容
水平扩缩容
TiDB水平扩缩容操作是指通过增加或减少pod的数量,来达到集群扩缩容的目的,扩缩容集群时,只需要修改replicas的值就可以对TiDB集群进行扩缩容操作
- 如果要进行扩容操作,可将某个组件的
replicas值调大。扩容操作会按照 Pod 编号由小到大增加组件 Pod,直到 Pod 数量与replicas值相等。 - 如果要进行缩容操作,可将某个组件的
replicas值调小。缩容操作会按照 Pod 编号由大到小删除组件 Pod,直到 Pod 数量与replicas值相等。
水平扩缩容PD、TiKV、TiDB
方法一:按需修改tidb组件的replicas值
[root@k8s-master ~]# kubectl patch -n tidb tc yz --type merge --patch '{"spec":{"pd":{"replicas":3}}}'
tidbcluster.pingcap.com/yz patched方法二:在线修改tc对应的replicas值
[root@k8s-master tidb]# kubectl edit tc yz -ntidb
tidbcluster.pingcap.com/yz edited
方法三:通过修改yaml文件然后应用
[root@k8s-master tidb]# cat tidb-yz.yaml
apiVersion: pingcap.com/v1alpha1
kind: TidbCluster
metadata:
name: yz
namespace: tidb
spec:
version: "v6.1.0"
timezone: Asia/Shanghai
hostNetwork: false
imagePullPolicy: IfNotPresent
enableDynamicConfiguration: true
pd:
baseImage: pingcap/pd
config: |
[dashboard]
internal-proxy = true
replicas: 1
requests:
cpu: "100m"
storage: 12Gi
mountClusterClientSecret: false
storageClassName: "local-storage-monitoring"
tidb:
baseImage: pingcap/tidb
replicas: 2
requests:
cpu: "100m"
config: {}
service:
externalTrafficPolicy: Cluster
type: NodePort
mysqlNodePort: 30032
statusNodePort: 30052
tikv:
baseImage: pingcap/tikv
config: {}
replicas: 1
requests:
cpu: "100m"
storage: 12Gi
mountClusterClientSecret: false
storageClassName: "local-storage-monitoring"
enablePVReclaim: false
pvReclaimPolicy:
[root@k8s-master tidb]# kubectl apply -f tidb-yz.yaml
tidbcluster.pingcap.com/yz configured
水平扩缩容TiFlash
扩容的方法
kubectl patch -n ${namespace} tc ${cluster_name} --type merge --patch '{"spec":{"tiflash":{"replicas":3}}}'
TiFlash也有三种方法进行扩缩容,以下采用第一种方法进行扩容
[root@k8s-master tidb]# kubectl patch -n tidb tc yz --type merge --patch '{"spec":{"tiflash":{"replicas":2}}}'
tidbcluster.pingcap.com/yz patched
[root@k8s-master tidb]# kubectl get pod -ntidb
NAME READY STATUS RESTARTS AGE
lqb-discovery-747b84c59d-r72lt 1/1 Running 2 16d
lqb-pd-0 1/1 Running 0 109m
lqb-pd-1 1/1 Running 2 16d
lqb-pd-2 1/1 Running 1 7d
lqb-tidb-0 2/2 Running 4 16d
lqb-tidb-1 2/2 Running 12 7d4h
lqb-tikv-0 1/1 Running 0 112m
lqb-tikv-1 1/1 Running 2 16d
lqb-tikv-2 1/1 Running 1 7d4h
lqb-tikv-3 1/1 Running 3 16d
monitor-monitor-0 4/4 Running 9 19d
tidbngmonitoring-lqb-ng-monitoring-0 1/1 Running 0 141m
yz-discovery-6c89b45d5d-nkps7 1/1 Running 1 26h
yz-pd-0 1/1 Running 2 26h
yz-tidb-0 2/2 Running 2 26h
yz-tidb-1 2/2 Running 0 7m2s
yz-tiflash-0 4/4 Running 0 31m
yz-tiflash-1 4/4 Running 0 7m2s
yz-tiflash-2 4/4 Running 0 2m54s
yz-tikv-0 1/1 Running 1 26h
yz-tikv-1 1/1 Running 1 6h46m
yz-tikv-2 1/1 Running 0 80m
缩容的方法
- 如果缩容 TiFlash 后,TiFlash 集群剩余 Pod 数大于等于所有数据表的最大副本数 N,则直接进行下面第 6 步。如果缩容 TiFlash 后,TiFlash 集群剩余 Pod 数小于所有数据表的最大副本数 N,则执行以下步骤:
- 参考访问 TiDB 集群的步骤连接到 TiDB 服务。
- 针对所有副本数大于集群剩余 TiFlash Pod 数的表执行如下命令:
alter table <db_name>.<table_name> set tiflash replica ${pod_number};-
${pod_number} 为缩容 TiFlash 后,TiFlash 集群的剩余 Pod 数。
- 等待并确认相关表的 TiFlash 副本数更新。连接到 TiDB 服务,执行如下命令,查询相关表的 TiFlash 副本数:
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = '<db_name>' and TABLE_NAME = '<table_name>';
- 修改
spec.tiflash.replicas对 TiFlash 进行缩容。你可以通过以下命令查看 Kubernetes 集群中对应的 TiDB 集群中的 TiFlash 是否更新到了你的期望定义。检查以下命令输出内容中,spec.tiflash.replicas的值是否符合预期值。
kubectl get tidbcluster ${cluster-name} -n ${namespace} -oyaml水平扩缩容TiCDC
如果集群中部署了 TiCDC,可以通过修改 spec.ticdc.replicas 对 TiCDC 进行扩缩容。例如,执行以下命令可将 TiCDC 的 replicas 值设置为 3:
kubectl patch -n ${namespace} tc ${cluster_name} --type merge --patch '{"spec":{"ticdc":{"replicas":3}}}'查看集群扩缩容状态
当所有的组件的pod数量都达到了预设值,并且都是running状态,表明扩缩容完成。
[root@k8s-master tidb]# kubectl get pod -ntidb -w
NAME READY STATUS RESTARTS AGE
lqb-discovery-747b84c59d-6fcqv 1/1 Running 0 18h
lqb-pd-0 1/1 Running 0 18h
lqb-tidb-0 2/2 Running 0 18h
lqb-tikv-0 1/1 Running 0 18h
tidbmonitor-monitor-0 4/4 Running 0 17h
tidbngmonitoring-yz-ng-monitoring-0 1/1 Running 0 19h
yz-discovery-6c89b45d5d-nkps7 1/1 Running 1 2d20h
yz-pd-0 1/1 Running 2 2d20h
yz-tidb-0 2/2 Running 2 2d20h
yz-tidb-1 2/2 Running 0 41h
yz-tidb-initializer-b8l8f 0/1 Completed 0 19h
yz-tiflash-0 4/4 Running 3 24h
yz-tiflash-1 4/4 Running 0 17h
yz-tikv-0 1/1 Running 1 2d20h
yz-tikv-1 1/1 Running 1 2
注意
- PD、TiKV、TiFlash 组件在扩缩容的过程中不会触发滚动升级操作。
- TiKV 组件在缩容过程中,TiDB Operator 会调用 PD 接口将对应 TiKV 标记为下线,然后将其上数据迁移到其它 TiKV 节点,在数据迁移期间 TiKV Pod 依然是
Running状态,数据迁移完成后对应 Pod 才会被删除,缩容时间与待缩容的 TiKV 上的数据量有关,可以通过kubectl get -n ${namespace} tidbcluster ${cluster_name} -o json | jq '.status.tikv.stores'查看 TiKV 是否处于下线Offline状态。 - 当 TiKV UP 状态的 store 数量 <= PD 配置中
MaxReplicas的参数值时,无法缩容 TiKV 组件。 - TiKV 组件不支持在缩容过程中进行扩容操作,强制执行此操作可能导致集群状态异常。假如异常已经发生,可以参考 TiKV Store 异常进入 Tombstone 状态 进行解决。
- TiFlash 组件缩容处理逻辑和 TiKV 组件相同。
- PD、TiKV、TiFlash 组件在缩容过程中被删除的节点的 PVC 会保留,并且由于 PV 的
Reclaim Policy设置为Retain,即使 PVC 被删除,数据依然可以找回。
垂直扩缩容
垂直扩缩容操作指的是通过增加或减少 Pod 的资源限制,来达到集群扩缩容的目的。垂直扩缩容本质上是 Pod 滚动升级的过程。
PD、TiKV、TiDB、TiFlash、TiCDC 进行垂直扩缩容。
- 如果要对 PD、TiKV、TiDB 进行垂直扩缩容,通过 kubectl 修改集群所对应的
TidbCluster对象的spec.pd.resources、spec.tikv.resources、spec.tidb.resources至期望值。 - 如果要对 TiFlash 进行垂直扩缩容,修改
spec.tiflash.resources至期望值。 - 如果要对 TiCDC 进行垂直扩缩容,修改
spec.ticdc.resources至期望值。
注意
- 如果在垂直扩容时修改了资源的
requests字段,并且 PD、TiKV、TiFlash 使用了Local PV,那升级后 Pod 还会调度回原节点,如果原节点资源不够,则会导致 Pod 一直处于Pending状态而影响服务。 - TiDB 是一个可水平扩展的数据库,推荐通过增加节点个数发挥 TiDB 集群可水平扩展的优势,而不是类似传统数据库升级节点硬件配置来实现垂直扩容。
二、集群管理
重启TiDB集群
在使用TiDB集群的过程中,如果发现某个pod存在内存泄露等问题需要对集群进行重启,本文通过优雅滚动重启TiDB集群内某个组件的所有pod,或优雅重启单个组件的单个pod.
在生产环境中,未经过优雅重启而手动删除某个 TiDB 集群 Pod 节点是一件极其危险的事情,虽然 StatefulSet 控制器会将 Pod 节点再次拉起,但这依旧可能会引起部分访问 TiDB 集群的请求失败。
优雅滚动重启TiDB集群组件所有pod
通过 kubectl edit tc ${name} -n ${namespace} 修改集群配置,为期望优雅滚动重启的 TiDB 集群组件 Spec 添加 annotation tidb.pingcap.com/restartedAt,Value 设置为当前时间。以下示例中,为组件 pd、tikv、tidb 都设置了 annotation,表示将优雅滚动重启以上三个 TiDB 集群组件的所有 Pod。可以根据实际情况,只为某个组件设置 annotation。
下边例子是重启tidb服务组件,其他组件的重启只需要添加
annotations:
tidb.pingcap.com/restartedAt: 2022-12-08T11:58
[root@k8s-master tidb]# kubectl edit tc/yz -ntidb
apiVersion: pingcap.com/v1alpha1
kind: TidbCluster
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"pingcap.com/v1alpha1","kind":"TidbCluster","metadata":{"annotations":{},"name":"yz","namespace":"tidb"},"spec":{"enableDynamicConfiguration":true,"enablePVReclaim":false,"hostNetwork":false,"imagePullPolicy":"IfNotPresent","pd":{"baseImage":"pingcap/pd","config":"[dashboard]\n internal-proxy = true\n","mountClusterClientSecret":false,"replicas":1,"requests":{"cpu":"100m","storage":"12Gi"},"storageClassName":"ssd-storage"},"pvReclaimPolicy":"Retain","tidb":{"baseImage":"pingcap/tidb","config":{},"replicas":2,"requests":{"cpu":"100m"},"service":{"externalTrafficPolicy":"Cluster","mysqlNodePort":30032,"statusNodePort":30052,"type":"NodePort"}},"tiflash":{"baseImage":"pingcap/tiflash","config":"[storage]\n [storage.main]\n dir = [\"/data0/db\"]\n [storage.raft]\n dir = [\"/data0/kvstore\"]\n","maxFailoverCount":0,"replicas":3,"storageClaims":[{"resources":{"requests":{"storage":"50Gi"}},"storageClassName":"local-storage"},{"resources":{"requests":{"storage":"50Gi"}},"storageClassName":"local-storage"}]},"tikv":{"baseImage":"pingcap/tikv","config":{},"mountClusterClientSecret":false,"replicas":1,"requests":{"cpu":"100m","storage":"12Gi"},"storageClassName":"ssd-storage"},"timezone":"Asia/Shanghai","tlsCluster":{},"version":"v6.1.0"}}
creationTimestamp: "2022-12-05T07:18:47Z"
generation: 642
name: yz
namespace: tidb
resourceVersion: "53232514"
selfLink: /apis/pingcap.com/v1alpha1/namespaces/tidb/tidbclusters/yz
uid: 50b1bdbc-629c-424e-9247-e36426ebd23c
spec:
discovery: {}
enableDynamicConfiguration: true
enablePVReclaim: false
hostNetwork: false
imagePullPolicy: IfNotPresent
pd:
baseImage: pingcap/pd
config: |
[dashboard]
internal-proxy = true
maxFailoverCount: 3
mountClusterClientSecret: false
replicas: 1
requests:
cpu: 100m
storage: 12Gi
storageClassName: ssd-storage
pvReclaimPolicy: Retain
tidb:
annotations:
tidb.pingcap.com/restartedAt: 2022-12-09T11:58
baseImage: pingcap/tidb
config: |
[log]
[log.file]
max-backups = 3
maxFailoverCount: 3
replicas: 2
requests:
cpu: 100m
service:
externalTrafficPolicy: Cluster
mysqlNodePort: 30032
statusNodePort: 30052
type: NodePort
[root@k8s-master tidb]# kubectl get pod -ntidb -owide -w |grep yz
tidbngmonitoring-yz-ng-monitoring-0 1/1 Running 0 44h 10.244.3.123 k8s-node6 <none> <none>
yz-discovery-6c89b45d5d-nkps7 1/1 Running 1 3d20h 10.244.2.15 k8s-node2 <none> <none>
yz-pd-0 1/1 Running 2 3d20h 10.244.2.8 k8s-node2 <none> <none>
yz-tidb-0 2/2 Running 0 23h 10.244.2.45 k8s-node2 <none> <none>
yz-tidb-1 1/2 Running 0 11s 10.244.2.52 k8s-node2 <none> <none>
yz-tidb-initializer-b8l8f 0/1 Completed 0 43h 10.244.2.36 k8s-node2 <none> <none>
yz-tiflash-0 4/4 Running 3 2d 10.244.1.58 k8s-node1 <none> <none>
yz-tiflash-1 4/4 Running 0 41h 10.244.3.125 k8s-node6 <none> <none>
yz-tikv-0 1/1 Running 0 23h 10.244.1.70 k8s-node1 <none> <none>
yz-tikv-1 1/1 Running 0 23h 10.244.2.49 k8s-node2 <none> <none>
yz-tikv-2 1/1 Running 0 21h 10.244.2.50 k8s-node2 <none> <none>
yz-tidb-1 2/2 Running 0 20s 10.244.2.52 k8s-node2 <none> <none>
yz-tidb-0 2/2 Terminating 0 23h 10.244.2.45 k8s-node2 <none> <none>
yz-tidb-1 2/2 Running 0 21s 10.244.2.52 k8s-node2 <none> <none>
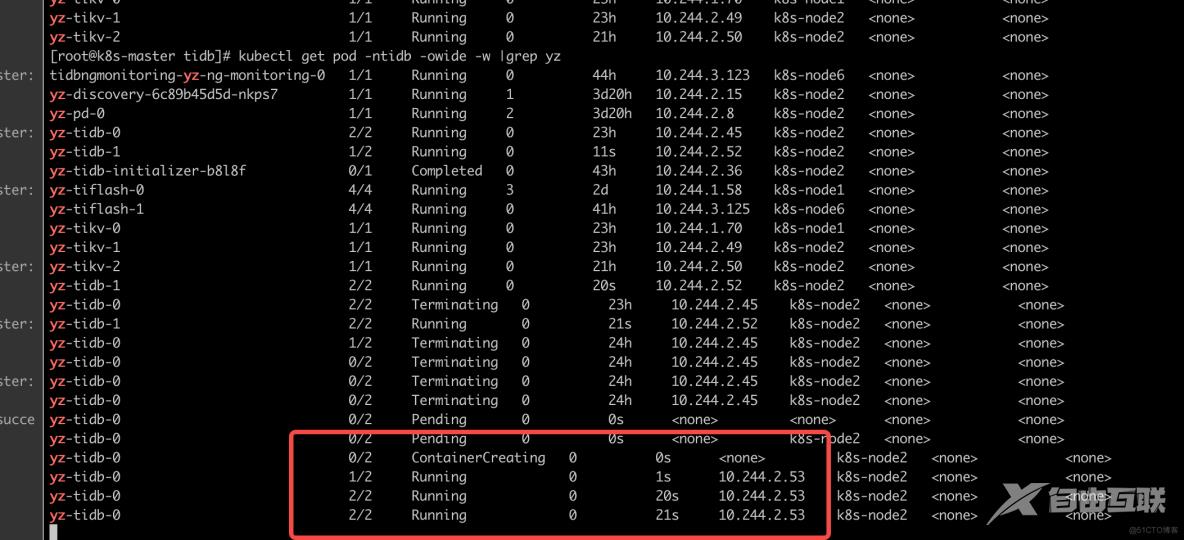
优雅重启TiDB集群单个组件的pod
从 v1.2.5 起,TiDB Operator 支持给 TiKV Pod 添加 annotation 来触发优雅重启单个 TiKV Pod。
添加一个 key 为 tidb.pingcap.com/evict-leader 的 annotation,触发优雅重启:
kubectl -n ${namespace} annotate pod ${tikv_pod_name} tidb.pingcap.com/evict-leader="delete-pod"具体删除单个tivk的例子实例如下:
[root@k8s-master tidb]# kubectl -n tidb annotate pod/yz-tikv-2 tidb.pingcap.com/evict-leader="delete-pod"
pod/yz-tikv-2 annotated
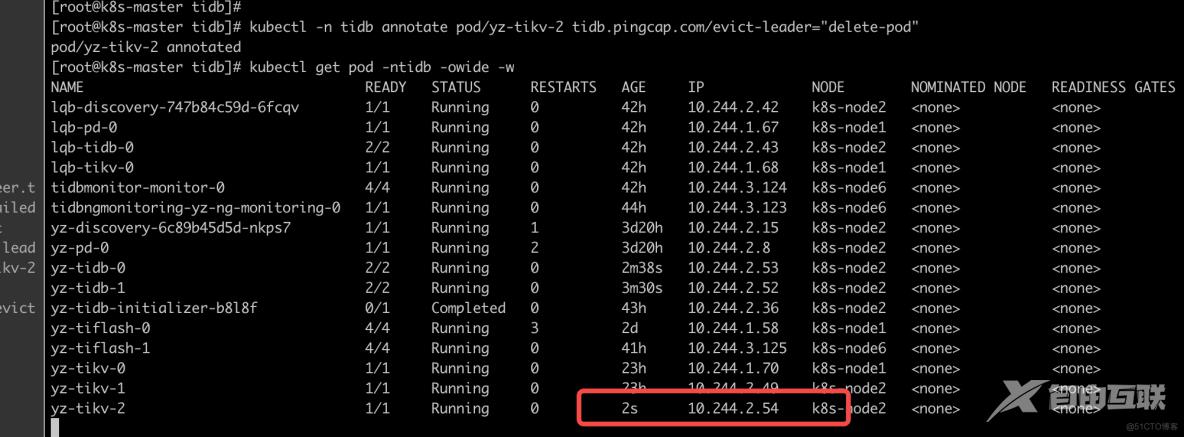
备注:
当 TiKV region leader 数掉到 0 时,根据 annotation 的不同值,TiDB Operator 会采取不同的行为。合法的 annotation 值如下:
-
none: 无对应行为。 delete-pod: 删除 Pod,TiDB Operator 的具体行为如下:
- 调用 PD API,为对应 TiKV store 添加 evict-leader-scheduler。
- 当 TiKV region leader 数掉到 0 时,删除 Pod 并重建 Pod。
- 当新的 Pod Ready 后,调用 PD API 删除对应 TiKV store 的 evict-leader-scheduler。
销毁TiDB集群
销毁使用TidbCluster管理的TiDB集群
要销毁使用 TidbCluster 管理的 TiDB 集群,执行以下命令:
kubectl delete tc ${cluster_name} -n ${namespace}如果集群中通过 TidbMonitor 部署了监控,要删除监控组件,可以执行以下命令:
kubectl delete tidbmonitor ${tidb_monitor_name} -n ${namespace}销毁使用helm管理的集群
helm uninstall ${cluster_name} -n ${namespace}销毁数据
上述销毁集群的命令只是删除运行的 Pod,数据仍然会保留。如果你不再需要那些数据,可以通过下面命令清除数据:
删除pvc和pv
kubectl delete pvc -n ${namespace} -l app.kubernetes.io/instance=${cluster_name},app.kubernetes.io/managed-by=tidb-operator
kubectl get pv -l app.kubernetes.io/namespace=${namespace},app.kubernetes.io/managed-by=tidb-operator,app.kubernetes.io/instance=${cluster_name} -o name | xargs -I {} kubectl patch {} -p '{"spec":{"persistentVolumeReclaimPolicy":"Delete"}}'三、常见报错
1.tiflash在扩容时出现如下报错:
Poco::Exception. Code: 1000, e.code()= 0, e.displayText() = Exception: Cannot set max size of core file to 1073741824, e.what() = Exception
原因:由于超过了系统限制所以报错且无法启动。
解决方法:
- 此时需要在 /etc/systemd/system/docker.service中添加LimitCORE=infinity 并采用ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock。
- 重启docker服务
systemctl daemon-reload
systemctl restart docker.service