1.前言
开源的 ETL工具里面 DataX和 Kettle的人气一直高居不下,datax虽然比较年轻,但这两年发展势头很猛,不时就能听到身边的同事谈起。kettle作为老牌的 etl工具,诞生年限长,功能完善,特别是其开箱即用的数据转换算子,不得不令人叹服。因此,笔者决定对这两款工具进行深入的对比分析,有多深呢,到源码那种。
2.DataX
DataX 是阿里开源的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间高效的数据同步功能。
从 GitHub上可以查到 DataX仓库的创建时间为 2018-01-18T10:09:47Z,是一个比较年轻的项目。
这里以 DataX 3.0为研究对象,从支持的数据源、界面化配置、数据转换能力、扩展性和部署难易程度等方面进行分析介绍。
2.1 数据源支持情况
下面这张表格来自 datax在 github的官方仓库:
类型
数据源
Reader
Writer
备注
RDBMS 关系型数据库
MySQL
√
√
读 、写
Oracle
√
√
读 、写
OceanBase
√
√
读 、写
SQLServer
√
√
读 、写
PostgreSQL
√
√
读 、写
DRDS
√
√
读 、写
Apache Doris
√
写
StarRocks
√
写
通用RDBMS(支持所有关系型数据库)
√
√
读 、写
阿里云数仓数据存储
ODPS
√
√
读 、写
ADS
√
写
OSS
√
√
读 、写
OCS
√
写
NoSQL数据存储
OTS
√
√
读 、写
Hbase0.94
√
√
读 、写
Hbase1.1
√
√
读 、写
Phoenix4.x
√
√
读 、写
Phoenix5.x
√
√
读 、写
MongoDB
√
√
读 、写
Hive
√
√
读 、写
Cassandra
√
√
读 、写
无结构化数据存储
TxtFile
√
√
读 、写
FTP
√
√
读 、写
HDFS
√
√
读 、写
Elasticsearch
√
写
时间序列数据库
OpenTSDB
√
读
TSDB
√
√
读 、写
TDengine
√
√
读 、写
从上面这张表格可以看到,datax对流行的 mysql, oracle, sql server和 pg等关系型数据库的支持较好。另外,对 hdfs, hive, hbase等大数据存储的支持度也不错,但对于全文搜索 elasticsearch的支持度较弱,仅支持写入。
总结下,如果是同步关系型数据库、hadoop生态圈的大数据存储、文本格式(csv,json等)的文件等场景,用 datax都是一个挺好的选择。
2.2 界面化配置
datax官方并没有提供配置数据同步任务的界面(至少在 github上没有),另外有一个流行的界面项目 datax-web(4.2k stars),由 WeiYe-Jing发起,但遗憾的是该项目 master分支已经超过两年没有更新,最近一次更新在 2020年6月。
datax-web界面以网页形式在浏览器中进行使用,支持 hive, mysql, oracle, postgresql, sqlserver, hbase, mongodb, clickhouse等数据同步任务的可视化创建,并集成了任务调度组件,支持分布式部署,功能精炼易用。缺点是支持的数据源比 datax官方少了很多,也没有提供数据转换的配置能力。
2.3 数据转换能力
datax官方提供的 transformer只有五个:
①、dx_substr
获取原字符串指定位置和长度的子字符串
②、dx_pad
统一字符串长度,长度超过阈值进行截断,长度不足则使用指定的字符进行填充
③、dx_replace
对字符串进行部分替换,可用于数据脱敏
④、dx_filter
支持 java的正则表达式,对数据进行过滤
⑤、dx_groovy
支持自定义 groovy脚本,可用于对数据进行复杂的转换操作
五个转换算子中,其实只有四个是可以直接使用的算子,最后一个算是对脚本进行了简单支持,满足了一定的扩展性。因为 datax一个核心设计是插件式开发,所以开发自定义 transformer也比较容易,需要继承基类 Transformer,如下:
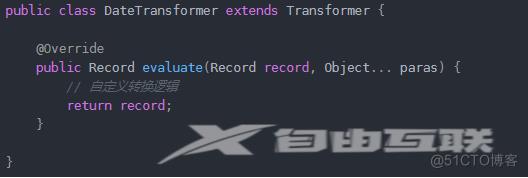
2.4 功能扩展性
这里主要分析核心的 reader, writer, transformer三大核心功能的扩展性。
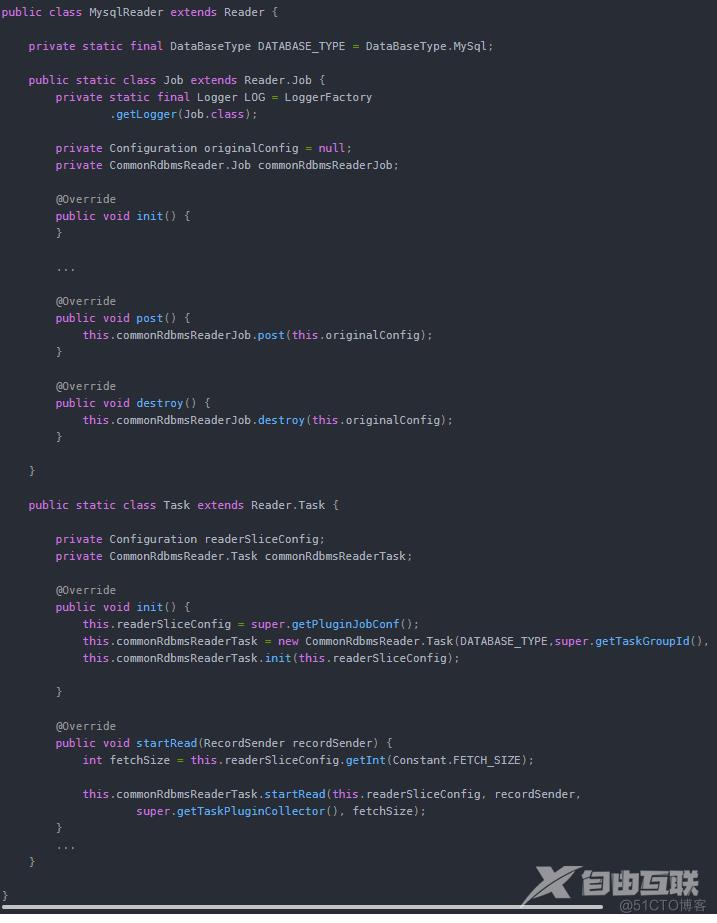
前面已经谈到,datax的开发是插件式思维,对扩展开放。reader插件用于读取数据源,自定义 reader插件需要继承 Reader, Reader.Job, Reader.Task三个类,并实现部分接口。下面是 mysql reader的部分源码:
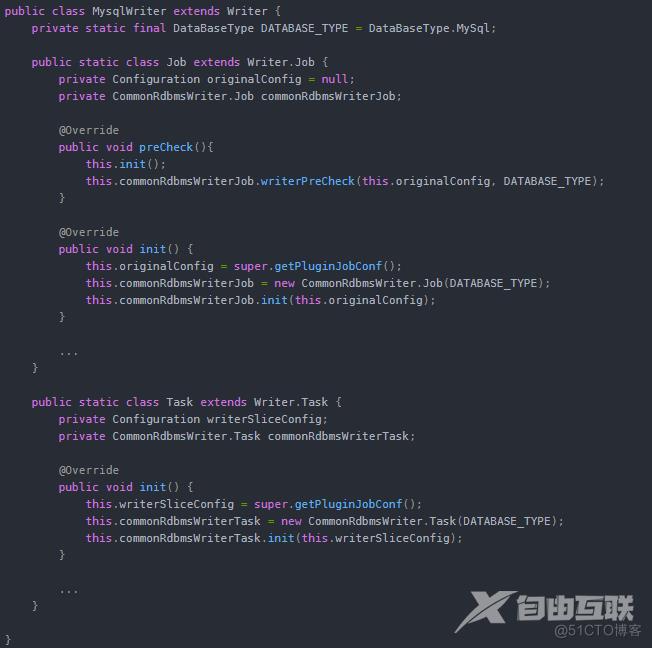
writer则是读取数据源的插件,跟 reader类似,自定义 writer插件也需要继承 Writer, Writer.Job, Writer.Task三个类,并实现部分接口。部分源码如下:
transformer已经在 2.3节进行了介绍,这里就不再介绍了。总的来说,datax扩展性很强,开发自定义插件的难度较小,比较适合根据业务进行二次开发和增强。
2.5 部署复杂度
部署 datax非常简单,预先搭建好 JDK1.8+和 python2.7的环境,然后解压已编译好的 datax安装包即可。
如果是从源码安装,则除了上述要求外还要准备好 Maven 3.x的环境。
3.Kettle
Kettle是开源自 2005年的一款老牌 ETL工具,使用 Java进行编写,核心组件有 spoon, pan, kitchen, carte。如今已被 Pentaho收购,并更名为 Pentaho Data Integration,简称 PDI。
这里以 PDI 9.2为研究对象(9.2以后依赖 JDK11+),同样从支持的数据源、界面化配置、数据转换能力、扩展性和部署难易程度等方面进行分析介绍。
3.1 数据源支持情况
类型
数据源
读
写
RDBMS 关系型数据库
MySQL
√
√
Oracle
√
√
IBM DB2
√
√
SQLServer
√
√
PostgreSQL
√
√
Teradata
√
√
SQLite
√
√
KingbaseES
√
√
Sybase
√
√
Azure SQL DB
√
√
Apache Derby
√
√
LucidDB
√
√
MonetDB
√
√
Microsoft Access
√
√
通用RDBMS(支持所有关系型数据库)
√
√
NoSQL数据存储
HBase
√
√
Hive
√
√
MongoDB
√
√
Cassandra
√
√
Calpont InfiniDB
√
√
Greenplum
√
√
Vertica
√
√
CouchDB
√
SSTable
√
无结构化数据存储
TxtFile(CSV, Json, LDIF, yaml, xml)
√
√
GZIP CSV
√
Excel
√
√
LDAP
√
√
Cube
√
√
Rss
√
√
FTP
√
√
HDFS
√
√
Elasticsearch
√
上面列出的数据源只是 kettle数据源中比较常见的部分,还有一些小众的未列出。可以看到 kettle对关系型数据库的支持相当好,估计是 ETL工具的天花板了,另外对大数据存储组件的支持也比较完善。对于 es的支持则有些差强人意,官方给的支持是只能写 es,也有资料表明可以使用 kettle运行 ssh命令的功能来读取 es。
3.2 界面化配置
前面提到了 kettle有 spoon, pan, kitchen, carte等四个核心组件,其中 spoon就是 kettle的可视化模块,以客户端的形式存在。
spoon提供了很多核心对象,一些常用的如下:
输入:CSV文件输入、JSON input、表输入、Excel输入、LDAP 输入、LDIF 输入、YAML 输入
输出:Access 输出、Excel输出、插入/更新、数据同步、JSON output、LDAP 输出、SQL 文件输出
转换:Add a checksum、Concat fields、值映射、列拆分多行、列转行、去除重复记录、增加常量、字符串替换
脚本:Java 代码、JavaScript代码、Rules executor、公式、执行SQL脚本、正则表达式
Big Data:HBase input/output、Hadoop file input/output、MongoDB input/output、SSTable output
批量加载:Elastic bulk insert、Greenplum load、MySQL 批量加载、Oracle 批量加载
加密:PGP decrypt/encrypt stream、对称加密、生成秘钥
另外,在实际使用过程中,界面偶尔会出现卡死的现象(win7),只能重启程序。
3.3 数据转换能力
kettle提供了相当多的数据转换算子,3.2节只是列出了部分转换算子,整体来看基本能满足日常的数据转换需求,如果不能满足的还可以编写 Java代码或者 JavaScript代码实现。
3.4 功能扩展性
类似 datax,kettle也是支持插件的,比如 kettle官方提供的 es批量写入插件不支持 7.x版本的 es,可以从 github拉取其 es插件源码进行修改并替换。
以编写 kettle数据库插件为例,需要继承 BaseDatabaseMeta类,并实现 DatabaseInterface接口,如下:
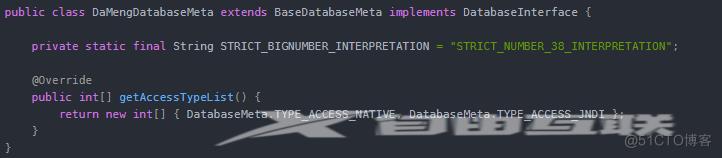
3.5 部署复杂度
部署 kettle同样非常简单,预先搭建好 JDK1.8的环境,然后解压已编译好的 kettle安装包即可。
如果是从源码安装,则除了上述要求外还要准备好 Maven 3.x的环境。
4.对比分析

datax比较年轻,且社区活跃度非常高,扩展性非常好,又属于国产化,但是数据转换算子较少,只能对数据做简单的转换,需要较大的开发量。
kettle胜在发展时间长,功能相对更加完善,特别是它的转换类算子非常多,但是架构老化,扩展性弱一些,且界面是以 客户端的形式提供,而不是浏览器页面。
5.总结
datax和 kettle各有优劣,如果开发资源足够,对性能要求高,推荐使用 datax。反之,如果追求开箱即用,功能完备,就更推荐使用 kettle。