最近一周我、强子、Y哥三人,根据自身如何入门推荐系统,再结合三人分别在腾讯做广告推荐、字节做视频推荐、百度做信息流推荐的经历,整理出了这份万字入门推荐系统。内容十分详细,涵盖了推荐系统基础、进阶、实战的全部知识点,并且每一块都给出了我们自己看过且觉得高质量的参考资料,所以不管你是科班还是非科班,按照这条路线走下去,找到推荐系统相关工作是完全没问题的。因为内容过于全面详细,即便你不从事推荐系统方向,只要是从事程序员,看完这篇文章也能有所收获。不过要先强调一下,如果是没有基础且时间充足的同学,可以按部就班的学,如果有一定基础或时间紧张,那就直接看核心知识。其中『 机器学习、深度学习、推荐算法理论知识、推荐系统实战项目 』这四块是核心知识,像数学、计算机基础可以等到你需要的时候再反过头来学习。在核心知识中也有次重点,要学会有的放矢,哪些知识是次重点,我都会在后面一一说明。
本文框架目录如下:
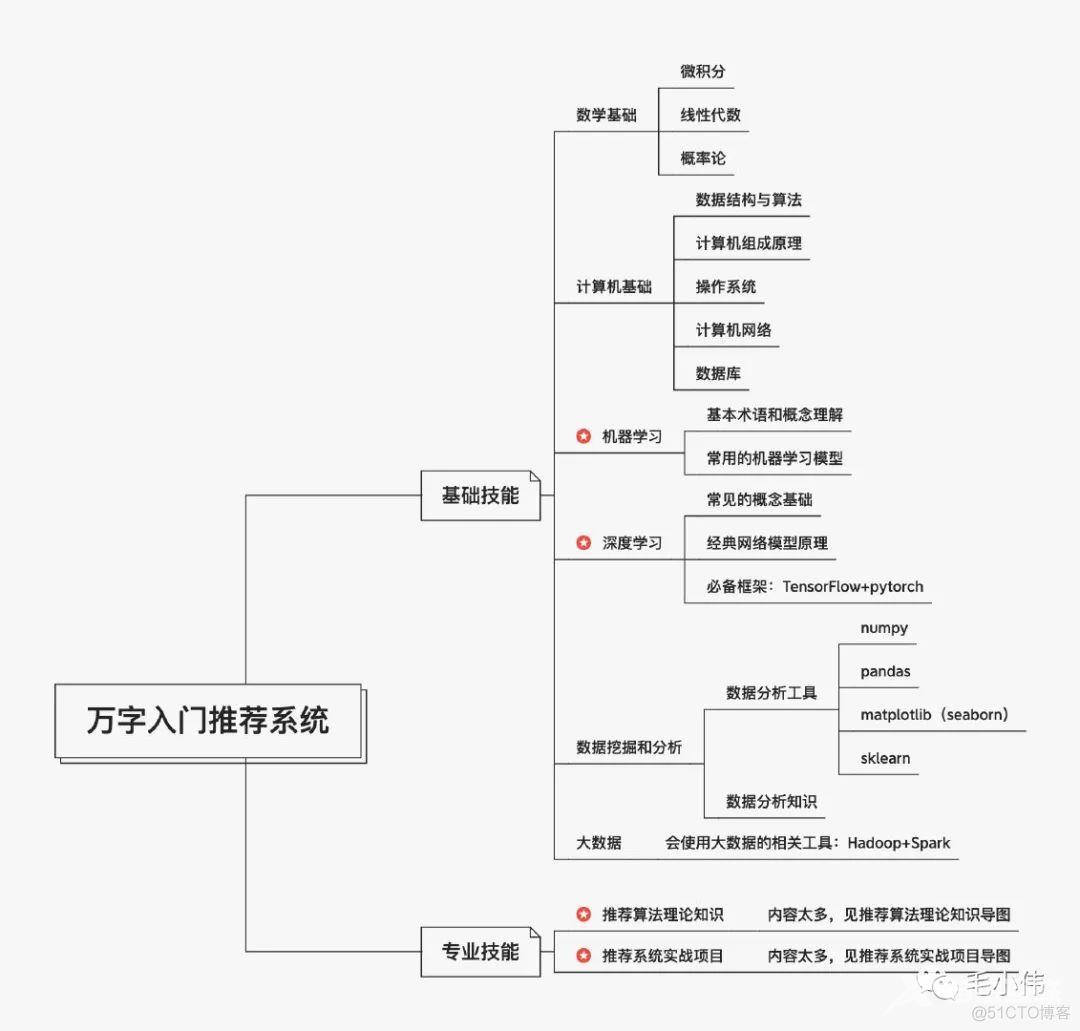
万字入门推荐系统
数学
主要是微积分、线性代数、概率论这三门课。
微积分
通常情况下,机器学习需要得到一个函数(模型,或者说假设)来预测未来的数据。既然是函数,那自然就离不开微积分了。微积分为我们研究函数的性质提供了理论依据,同时它也是学习概率论、最优化方法等后续课程的基础,是整个高等数学的基石。
重点掌握函数的求导法则(特别是链式法则),以及泰勒公式。这对后续的梯度下降法,牛顿法,拟牛顿法等优化算法的推导至关重要!
线性代数
机器学习算法的输入、输出、中间结果通常为向量、矩阵、张量。这些都属于线性代数里的知识。
重点掌握向量、矩阵含义及其数学运算公式。
概率论
对于机器学习来说,概率论是一种重要的工具。如果将机器学习算法的输入、输出看作随机变量/向量,则可以用概率论的观点对问题进行建模。使用概率论的一个好处是可以对不确定性进行建模,这对于某些问题是非常有必要的。另外,它还可以挖掘变量之间的概率依赖关系,实现因果推理。
重点掌握常见概率分布、概率公式。
总结
数学好是入门机器学习的优势,但并非关键。因为数学知识量太庞大了,花太多时间在其上,容易打击学习积极性。另外做算法一般分两种:理论模型和实际应用,前者的行业title是算法研究员,主要发paper、提出新的模型或者优化方法,所以对于数学能力要求很高。后者的行业title是算法工程师,致力于把模型应用于数据上,攫取商业价值,对于数学能力要求并不高。往往大部分人都属于后者,我个人也是后者。熟悉不同算法的应用场景、掌握模型落地工程技术,才是我们更应该投入精力的地方。
参考资料:
- 《DeepLearning》,又名「花书」,被誉为深度学习领域圣经。它前面有必备数学知识的介绍,讲得挺不错的。
- B站搜索微积分、线性代数、概率论关键词,会有很多教学视频,随便选取时长较短的看看即可。
计算机基础
计算机基础包含数据结构与算法、计算机组成原理、操作系统、计算机网络、数据库、五大课程。其中数据结构与算法是面试必考内容,大家都会花时间好好学。但是另外4门课,开发岗面试中一定会问,算法岗却很少会问,再加上很多做算法的人是转行过来,非计算机科班出身,大学期间没有上过此类专业课。所以很多做算法的人计算机基础比较薄弱。但是在我看来计算机基础是很重要的。一是能提高我们计算机素养,二是增加工程代码理解能力。所以后面我会针对这四门课程,出一个面向算法工程师的系列文章,做到让大家对这些课程重点知识有个了解,同时又不会陷入细枝末节。这里先给大家做个大概讲解:
数据结构与算法
数据结构包含:数组、链表、栈、队列、树、散列表、图。数据结构本质是描述数据与数据之间的关系
算法包含:排序、查找、五大经典算法(动态规划、回溯、分支界限、分治、贪心)。计算机解决问题其实没有任何奇技淫巧,它唯一的解决办法就是穷举。算法设计的本质无非就是先思考「如何穷举」,然后再追求「如何聪明地穷举」。「聪明的穷举」分为两部分:「去掉重复的穷举」、「去掉不必要的穷举」。比如,备忘录法,用数组保存求过的结果,用空间换时间,这就是去掉重复的穷举;动态规划根据最优子结构,使当前问题只与某几个子问题有关,从而大大减少问题分解次数,这就是去掉不必要穷举。
参考资料:
- 《剑指offer》,准备过面试的人应该都知道这本书。
- 《大话数据结构》通俗易懂。剩下的就是多刷LeetCode,多看别人的题解。
计算机组成原理
讲解计算机组成结构。主要由CPU(运算器、控制器),存储器(内存、外存),IO设备(输入、输出设备),总线这几部分构成。如果把计算机比作人,那么CPU是人的大脑,负责控制全身和运算;内存是人的记忆,负责临时存储;外存是人的笔记本,负责永久存储;输入设备是耳朵或眼睛或嘴巴,负责接收外部的信息存入内存;输出设备是你的脸部(表情)或者屁股,负责输出处理后的结果;以上所有的设备都通过总线连接,总线相当于人的神经。
操作系统
是应用程序与硬件之间的管家:对下管理计算机硬件资源(CPU、存储器、IO设备)、对上管理应用程序。
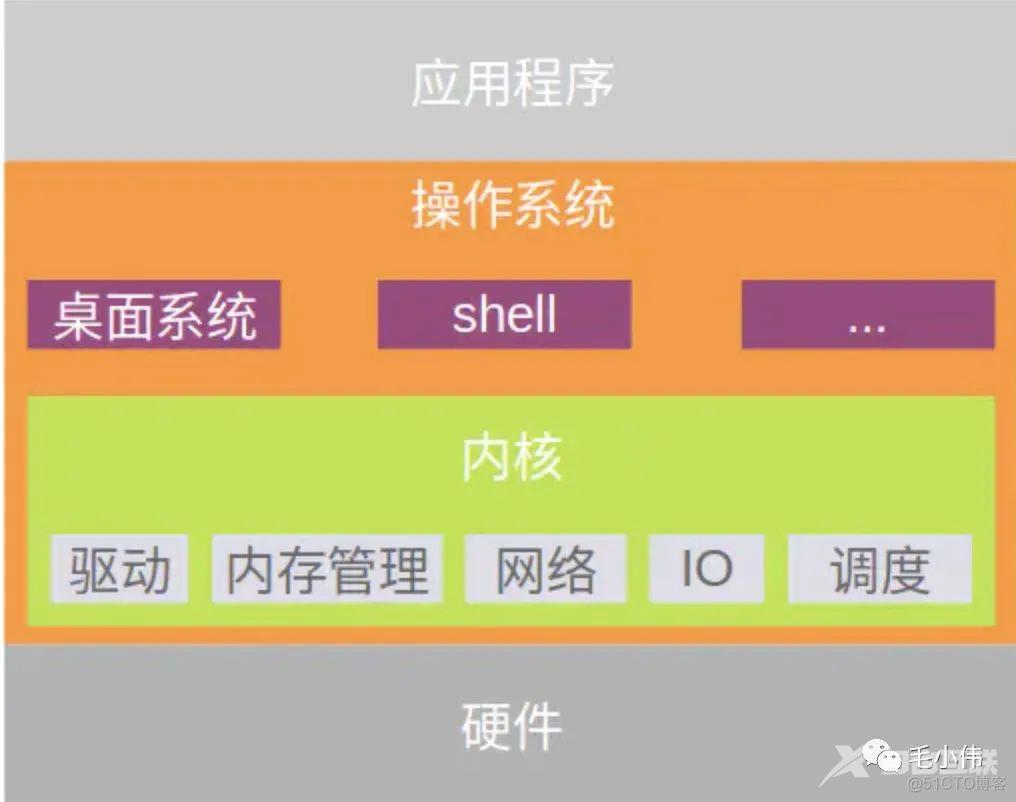
内核(kernel)是直接控制硬件的。比如:内核控制硬件有1000种方式,导致直接调内核去操作硬件很麻烦,于是就封装内核,向外提供了易于调用的接口,比如:桌面系统、shell等。这些接口对非编程人员用户还是不友好,于是编程人员用编程语言再对这些接口在进行封装,就产生了应用程序。本质是封装的思想。
我们学的编程语言到最后都是在调用操作系统内核API。所以这也是为什么所有的语言都有不同操作系统版本,因为每个操作系统的内核API是不同的。
参考资料:
- 《深入理解计算机系统》,配套视频:https://www.bilibili.com/video/BV1cD4y1D7uR
- 《鸟哥的Linux私房菜》,Linux是最常用的服务器系统,也是我们工作中最常接触的。熟悉Linux常用命令很有必要。
计算机网络
很多教材都是从五层模型(物理层、数据链路层、网络层、传输层、应用层)讲解。其实这样讲是比较晦涩难懂的,因为很多东西我们都没接触过,很陌生。好的办法是通过人类的语言系统进行类比。计算机网络是计算机的语言系统,与人类语言系统的本质是一样的。
人类语言系统构成:
- 词汇
- 语法
- 声带+耳朵
- 传播介质:空气
以此类比到计算机网络:
- 数据:计算机之间传输的信息
- 通信协议:决定数据的排列方式
- 网卡:数据发射器与接收器
- 传播介质:光纤、网线、WIFI
此外还有人的身份证相当于Mac地址,家庭地址相当于IP地址等等。计算机网络中的许多概念都可以用生活中人类是如何通信的进行类比。人类通信我们是非常熟悉的,所以非常有助于我们理解。
参考资料:
- 《计算机网络自顶向下方法》这本书相比于其他计算机网络书籍较通俗易懂,学习起来应该不太费劲。这本书重点章节是第2、3、4、5、6章,其他章节可以跳过。配套视频:https://www.bilibili.com/video/BV1mb4y1d7K7
- 谢希仁的《计算机网络》,是国内很有名的教材。
数据库
数据库就是我们存储数据的工具。数据如何存储与读取,直接决定了整个系统的效率。常用的关系型数据库是MySQL,非关系型数据库是Redis
参考资料:
- 《SQL必知必会》,快速掌握常用的SQL语法
- 一天学会 MySQL 数据库
机器学习
人工智能、机器学习、深度学习关系如下:
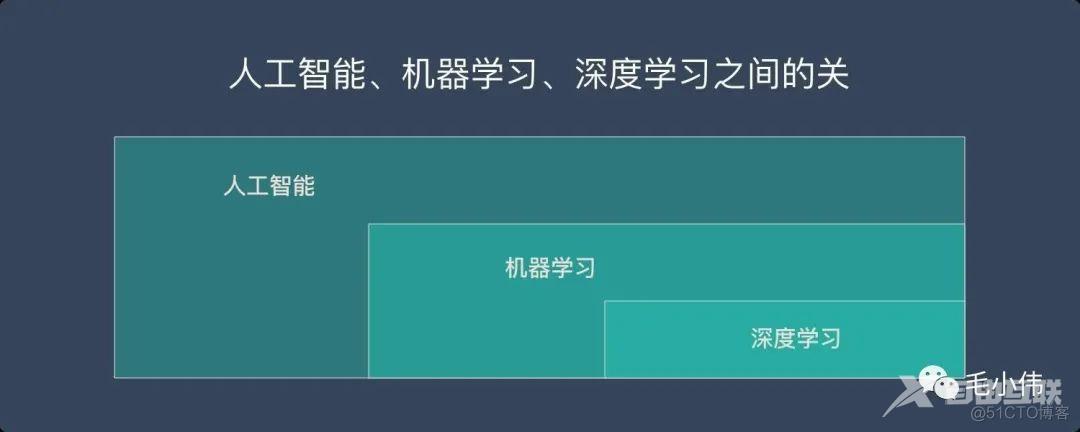
我们一般说机器学习都是指除了深度学习以外的机器学习,也称为传统机器学习。虽然近几年深度学习越来越火,但是很多领域还是在使用机器学习,并且学好机器学习,对于AI算法基础和知识广度都有很大提高。这里可以先给大家罗列一些必备的基础知识:
首先要知道一些基础的术语和概念,比如有监督与无监督,训练集,验证集与测试集,经验误差与泛化误差,方差与偏差,过拟合与欠拟合等,再比如比较重要的一些模型性能度量方法(混淆矩阵,精确率,召回率,auc,roc等), 再比如经典的评估方法(留出,交叉验证,自助等)
其次是经典的模型。机器学习模型非常多,全部掌握不现实,我给大家罗列几个经典,也是面试中常考的模型:逻辑回归、SVM、树模型、集成学习、朴素贝叶斯、K-Means聚类、PCA。(EM、最大熵、概率图这些考的少,能了解是加分项)。
在学习过程中,各个模型是相互联系的,不要孤立去分析单个模型。比如:逻辑回归,我认为是最基础、也最重要的模型:
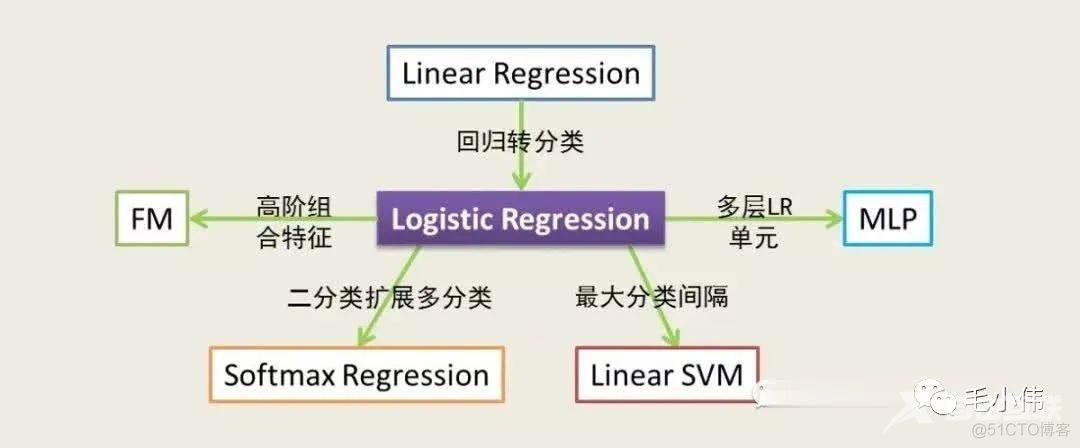
- 逻辑回归=线性回归+sigmoid激活函数,从而将回归问题转换为分类问题
- 逻辑回归+矩阵分解,构成了推荐算法中常用的FM模型
- 逻辑回归+softmax,从而将二分类问题转化为多分类问题
- 逻辑回归还可以看做单层神经网络,相当于最简单的深度学习模型
通过逻辑回归由点及面,就能演化出如此多模型。再比如树模型。我们把以决策树为基础的一系列模型统称为树模型,也是AI比赛中最常用的模型。
- 决策树经历了三次改进,ID3、C4.5、CART,主要区别在于一个根据信息增益划分特征、一个根据信息增益率、一个根据基尼指数。
- 随机森林=决策树+Bagging集成学习
- GBDT=决策树+AdaBoost集成学习
- XGB是陈天奇2014年提出,相当于GBDT的工程改进版,在实用性和准确度上有很大提升。比如:使用泰勒二阶展开近似损失函数,支持处理缺失值、在特性粒度上并行计算等等特性。
- LGB是微软2016年提出,对XGB进行了改进,使用单边梯度采样算法减少不必要的样本;在寻找最优分割点时采用直方图算法使计算代价更小;支持类别特征...
- CGB是Yandex2017年提出,对类别特征进行了更完美的支持。
所以学习模型,要由点及面,层层递进。这样不仅方便理解,也有利于归纳总结,同时还能锻炼搭建知识体系的能力。
关于上面这些知识,整理一个系列帮助大家由点及面打通这块知识,文章已写了五篇,后面会陆续放出来。
实战
我认为最好的实战方式就是参加AI比赛。这个过程中不仅能与高手同台竞技,如果获奖还能拿到不菲的奖金(很多比赛奖金都是10万以上)与荣誉。我之前参加了很多比赛,拿过冠军和多个top 10。对于我个人能力提升与找工作都有很大帮助。这里推荐三个公众号:kaggle竞赛宝典、Coggle数据科学、第一次打比赛。他们会发布新比赛的通知与过往比赛的解决方案,非常值得学习。
再就是书籍:《机器学习算法竞赛实战》这本书是Datawhale成员,top级竞赛选手鱼佬写的。
参考资料:
- 如果是一个机器学习小白,那么推荐两个入门视频, 吴恩达或者李宏毅的ML视频(B站上都有),先快速过一遍,了解机器学习是什么。
- 如果有了一定的机器学习基础,就需要去进阶。建议是看书与高质量文章。推荐两本书:周志华的《机器学习》、李航的《统计学习方法》这两本书,可以好好先研究一本,注意这里是研究,一本通了,另一本也就差不多。如果发现看一遍很难看懂,这是正常现象,随着后面实践经历慢慢变多,再看一遍,会有很多新的感悟。再就是公众号:Datawhale,里面有很多高质量文章。
注意:学习过程中一定要跟着实战,否则知识很难真正理解。
深度学习
前面也提到了,深度学习本属于机器学习,但是鉴于其发展迅速、应用越来越广泛,所以单独拿出来说。深度学习每年新模型、新技术层出不穷,一味追求新技术不可取,要先打好基础。比如:对于一个简单的全连接神经网络,包含训练算法(正向传播、反向传播),激活函数(sigmoid、ReLU、Maxout、softmax等),正则化(L1和L2、Dropout、提前早停等),优化算法(随机梯度下降、Momentum、Adagrad、Adam等)
掌握了基础后,再根据自身领域学习相关的模型。大部分人找工作属于这三个领域:
- 计算机视觉(CV):卷积神经网络(CNN)及其改进。
- 自然语言处理(NLP):循环神经网络(RNN)及其改进,Transformer、Bert等。
- 推荐算法:Embeding、Wide & Deep及其改进。
实战
熟练使用TensorFlow或pytorch去实现训练模型。通过官网的一些demo就可以快速的掌握一个深度学习框架的基本用法,然后在实际的应用中再去了解一些框架的高级用法,这个不需要花太多的时间单独学习,应该边用边学习。
积累模型调参经验,比如学习率,batchsize, 优化器对模型的影响,使用tensorboard可视化训练过程的曲线,通过曲线分析训练过程的相关问题,然后再调参或者调解网络结构,在实践的过程中要有意识的去总结一些经验。
参考资料:
- 李沐《动手学深度学习》https://zh-v2.d2l.ai/
- 邱锡鹏《神经网络与深度学习》https://nndl.github.io/
- 吴恩达《深度学习》https://www.bilibili.com/video/BV1FT4y1E74V
- 《DeepLearning》,又名「花书」,被誉为深度学习领域圣经。
- TensorFlow、pytorch官网是最好的参考资料。如果英语不好,那么可以看看下面的资料:
- Pytorch学习笔记:
- 《30天吃掉那只TensorFlow2》:https://github.com/lyhue1991/eat_tensorflow2_in_30_days
- 《20天吃掉那只Pytorch》:https://github.com/lyhue1991/eat_pytorch_in_20_days
- PyTorch深度学习快速入门教程:https://www.bilibili.com/video/BV1hE411t7RN
数据挖掘与分析
熟练使用相关工具包:numpy、pandas、matplotlib(seabron是matplotlib的简化版)、Scikit-Learn。完成数据的可视化、分析以及特征工程。工具包的学习建议边用边学,可以先看一些中文教程整体了解一下工具包的使用。在具体使用的时候,如果忘记了可以去对应工具包的官网查看详细的文档。
除了熟悉数据分析工具以外,其实更需要的是数据分析的方法,我觉得最好的学习方式就是看开源竞赛的方案,因为在开源方案中,作者会写很多他们分析问题的思路,以及对可视化结果给出的他们认为的正确观点。
参考资料:
英文教程首推官网,中文教程推荐Datawhale的开源项目
- numpy中文教程:https://github.com/datawhalechina/powerful-numpy
- pandas中文教程(这份文档可能比官方文档还适合学习):https://github.com/datawhalechina/joyful-pandas
- matplotlib中文教程:https://github.com/datawhalechina/fantastic-matplotlib
- 《Hands-on-Machine-Learning-with-Scikit-Learn》用sklearn工具实现各种机器学习模型
大数据
在实际工业场景中,我们面临的都是海量数据,也就是所谓的大数据。再用上面提到的MySQL数据库、numpy、pandas等工具是不行的。这个时候就需要专业的大数据处理工具:Hadoop、Spark生态。有的同学想从这些生态的基本原理学起, 如果有时间,知其所以然是好的,但往往我们需要兼顾算法和大数据,时间并不是很充足,所以建议大数据这块可以先掌握到会用的层次,当做工具即可。
常用的:首先是Hive查询,也就是用HQL进行一些表数据的基础查询,这个和SQL有些类似,另外一个,就是sparkSQL以及spark的DataFrame, 这些相关操作常用来做数据分析和处理,处理完毕之后,写回到Hive表里面。其次,遇到复杂的处理逻辑,就需要写原生spark脚本去跑数据了。关于这块知识,后面也会整理一篇文章。
参考资料:
这一块实操性特别强,所以建议先看视频,跟着视频一步步来:
- 尚硅谷大数据Hadoop 3.x
- 尚硅谷大数据Spark教程从入门到精通
- 推荐系统算法基础+综合项目实战:https://www.bilibili.com/video/BV1qK4y1479r
推荐算法理论知识
终于到了核心部分。再次强调一下,上面的知识不要求全掌握,既不需要,也不现实。如果为了快速入门,掌握机器学习、深度学习基础后就可以直接进入这一节了。
在实际的工业推荐系统中,一般会有四个环节:
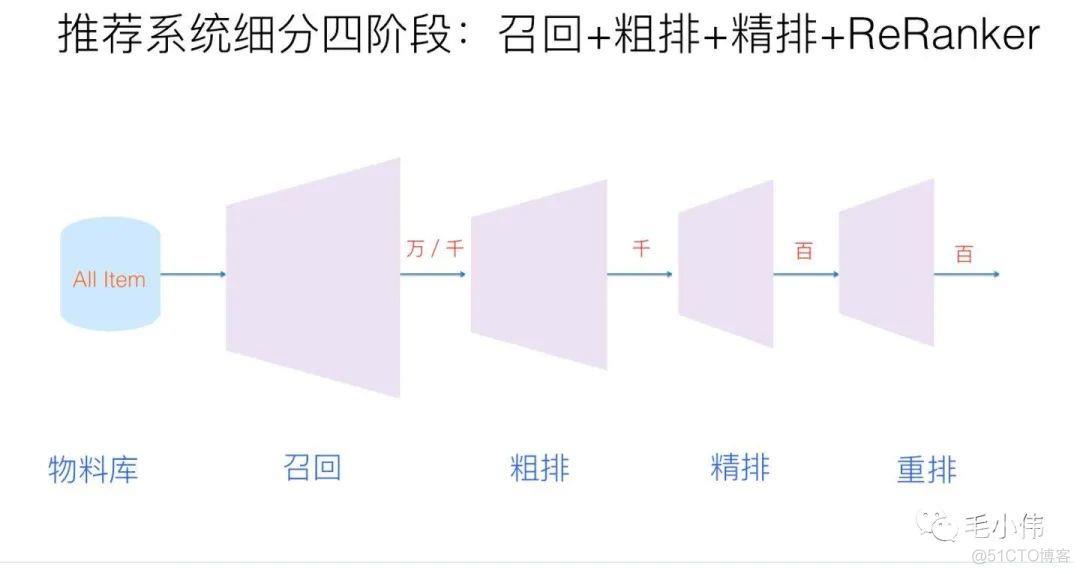
我梳理了这四个环节中用到的主流技术,整理成了如下导图:
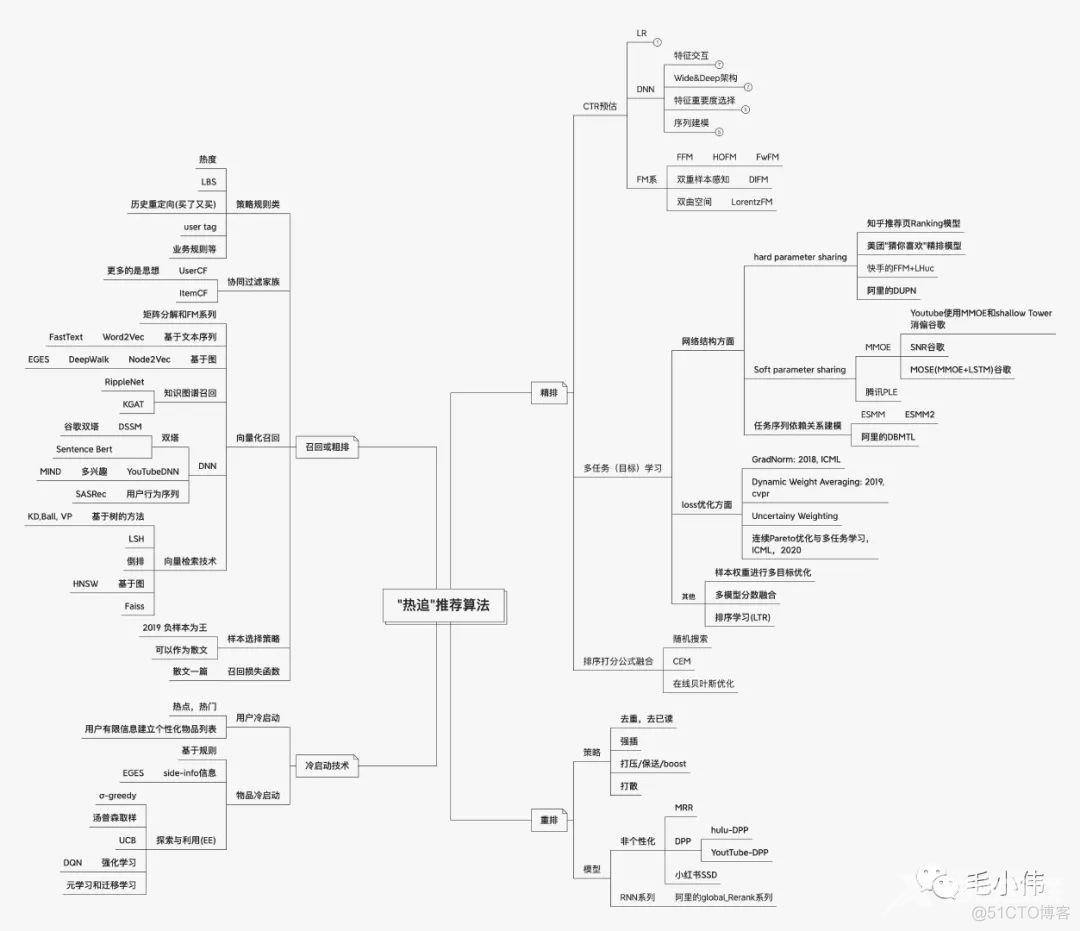
热追推荐算法
上图就是整个推荐算法的核心内容。这里先放出这个导图,一是让大家对推荐算法有个整体框架,二是告诉大家后续文章的内容:打算通过解读论文的形式,结合自身在工作中接触的工业场景,把里面的模型和知识点一一为大家解读。
这个系列我取名:"热追"推荐算法。主要包括以下四个部分:
召回粗排
召回的目的是根据用户部分特征,从海量物品库快速找到小部分用户感兴趣的物品交给精排,重点是强调快。主要有两大类召回方式,一类是策略规则,一类是监督模型+embedding。其中策略规则,往往和业务场景是强相关,不同的场景会有不同的召回方式,对于这种"特异性"较强的知识,会放到后期讲。目前打算先讲解普适的方法,就是模型+embedding。上图梳理出了目前给用户和物品打embedding的主流方法, 比如FM系列(FM,FFM等), 用户行为序列,基于图和知识图谱系列,经典双塔系列等。这些方法看似很多很复杂,其实本质上还是给用户和物品打embedding而已,只不过考虑的角度方式不同。这一块的内容,几乎每个模型都对应着经典paper,所以会采用解读论文的方式给大家分享。在解读的过程中,对于一些重要模型,会进行代码复现,并应用到一些真实的实践任务中。至于粗排,有时候召回环节返回的物品数量还是太多,怕精排速度跟不上,所以可以在召回和精排之间加一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的。因此粗排用到的很多技术与召回重合,所以先暂且归并到召回里,等后面把整体的基础知识都补充完毕了,再看情况要不要展开这块。
精排
精排阶段使用你能想到的任何特征,可以上你能承受速度极限的复杂模型,尽可能精准地对物品进行个性化排序,强调准确性。这一块关键技术主要分为三大块:
- CTR预估:LR、FM家族、自动特征交叉的DNN家族。
- 多任务学习(Multi-Task Learning,也称为多目标学习)。多任务是很常见的,比如视频推荐中,用户喜欢、收藏、评论。而不同的任务可能会互相冲突,互相影响,造成模型学习起来十分困难。所以这一块是重难点,也是很多大公司的研究重点,更是未来的一大发展趋势。但好在这里每个模型或者技术有对应paper,所以和召回一样,这里依然可以利用解读paper的方式,把这些模型和技术娓娓道来。
- 排序打分公式融合。
重排
考虑到上面的两块是核心,这块没有详细的展开整理,并且这块和业务场景策略强相关,很依赖工作经验,目前了解的也不是很多。后续先解读几篇重排模型的经典论文,等学习了相关技术,再来不断完善这块。
冷启动
冷启动问题是指对于新用户和新商品,他们没有历史交互数据,无法分析历史喜好,这个时候我们应该如何做推荐。冷启动技术会穿插到召回或者重排中,有时也会和上面推荐系统做成并行的两路,专门应对冷启动场景。
参考资料:
- 首先当然是后续自己写的文章啦哈哈哈。主要是因为搞算法的人学习模型都是参考论文,这也是为什么我后面分享这一块内容都是以解读论文的形式。
- 一定要推荐一本书籍的话,我选王喆的《深度学习推荐系统》。这本书高屋建瓴的介绍了推荐系统整体架构,发展历史以及未来趋势,还有各种推荐模型的演化之路,很适合前期用来当做科普。但是具体的模型并没有深入讲解,还是得自己去看论文解读。
- 再就是一些我认为很优秀的开源项目:
- 强子整理的 https://github.com/zhongqiangwu960812/AI-RecommenderSystem
- 我的另一个好友潜心整理,star已过千 https://github.com/ZiyaoGeng/Recommender-System-with-TF2.0
推荐系统实战项目
理论一定要与实践结合,否则就是空中楼阁。为此我们打造了一个新闻推荐项目:基于我们之前的开源项目(fun-rec:https://github.com/datawhalechina/fun-rec)做了一个完整升级。实现了从前端、后端、数据库、推荐模型等整个流程。项目规划图如下:
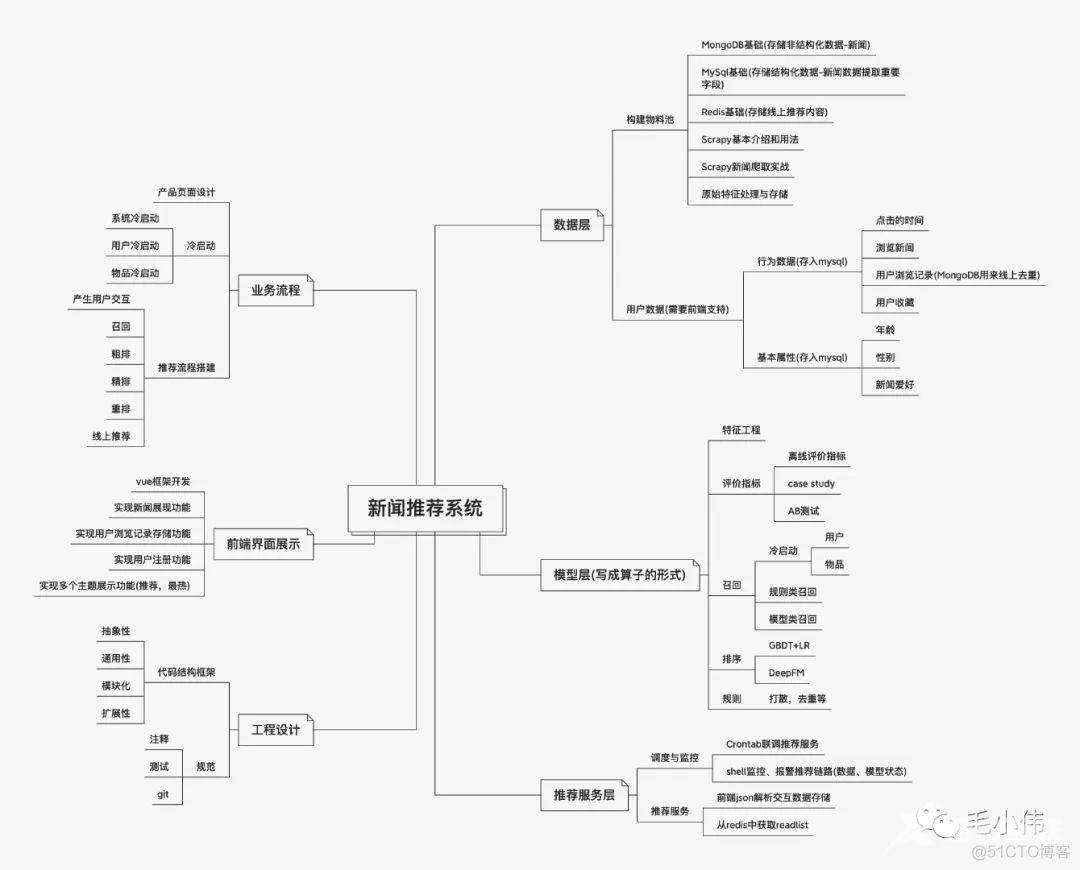
新闻推荐系统
阶段一
物料池的构建:
- Mysql基础及python调用(简介、安装、简单的命令行基础、python如何调用mysql数据(增删改查,排序))
- MongoDB基础及python调用
- Redis基础及python调用
- Scrapy基础及新闻爬取
- 新闻画像构建(存入MongoDB)
前端展示:
- Vue简介及基本使用(对于我们做推荐算法的,了解一些前后端交互之类的就够了)
- 前后端如何交互
- 用户注册界面
- 新闻展示(内容、时间、点赞次数,收藏次数)
- 可以保留用户的行为(user_id, news_id, action(点赞、收藏、阅读),time)
阶段二
有了前端及物料池后,就需要设计简单的冷启动规则来收集用户的行为数据以及用户的基本属性特征。这一部分数据可能需要参加开源学习的同学来一起帮忙完善这个数据集,这样数据才是有意义的。
- 收集数据
- 在服务器上部署数据收集的系统(新闻数据+用户行为数据)
- 冷启动策略
- 冷启动
用户侧
物品侧
系统侧
阶段三
这个阶段就是推荐算法大展身手的地方啦。我们可以把上一节学到的推荐算法,在这里尽情尝试,吹拉弹唱任你挑选。
- 离线评估指标
- 多路召回
- 特征工程
- 规则类
- 模型类
- 召回评估
- 排序
DeepFM
排序评估
规则+重排
阶段四
最后就是一些运营类知识,保证系统的高可用性
- 推荐服务,前后端交互(flask)
- 任务调度
- 系统部署
- 规范类修改
结束语
本文作为推荐系统的开篇,不仅讲解了入门推荐系统所需前置知识、基础、进阶、实战等全部知识点,还为后续推荐算法理论知识与实战项目定下计划。希望大家多多关注交流,我会按时更新后续系列文章。
