前言
- 内存函数的使用广泛度大于常用字符串函数的使用广泛度,因为字符串函数只适用于与字符相关的,而内存函数适用于各个类型,因为他是从内存出发,对内存进行修改,因此,学会内存函数,可谓收获满满呀。
- 这些内存函数的头文件是
<string.h>
memcpy
- 该函数的功能是内存拷贝,相当于字符串函数
strncpy的功能,只不过memcpy的运用范围更宽。- 该函数是在内存中一对字节一对字节的拷贝。
该函数的函数参数:


- 可以看到,对于重叠的拷贝,
memcpy是做不到的(也就是一个数组arr[] = {1,2,3,4,5,6,7,8,9,10},1,2,3,4,5要拷贝到3,4,5,6,7上去,这样是不行的),此时应该用memmove,但是vs的memcpy超额完成了任务,也可以进行重叠拷贝。
memcpy函数的使用
#include <stdio.h>
#include <string.h>
int main()
{
int arr1[] = { 1,2,3,4,5,6,7,8,9,10 };
int arr2[] = { 9,9,9,9,9 };
memcpy(arr1, arr2, sizeof(int) * (sizeof(arr2) / sizeof(arr2[0])));
// sizeof(int) * (sizeof(arr2) / sizeof(arr2[0])) arr2的总字节个数;
for (int i = 0; i < sizeof(arr1) / sizeof(arr1[0]); i++)
{
printf("%d ", arr1[i]);
}
return 0;
}
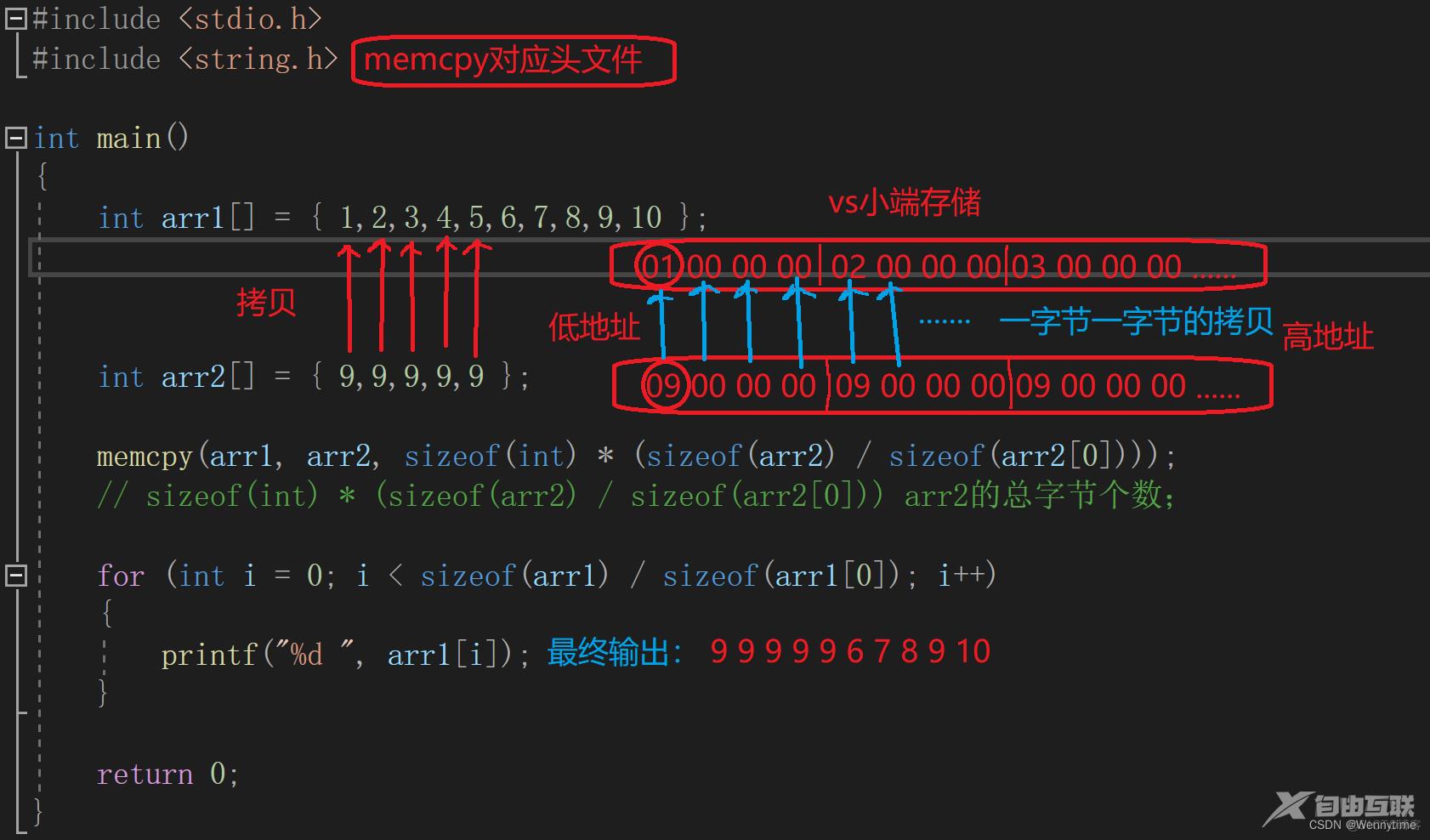
运行结果:
9 9 9 9 9 6 7 8 9 10
memcpy对字符串也是一样:
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = "xxxxxxxxxx";
char arr2[] = "abcdef";
// 这里拷贝6个字节,注意最好拷贝的时候不要把\0弄没了,不然打印会出错
printf("%s\n", (char*)memcpy(arr1, arr2, 6));
// 因为返回的是 void* 所以最好强转一下
return 0;
}
运行结果:
abcdefxxxx
memcpy函数的自我实现
代码实现的核心在于,如何一个字节一个字节的拷贝,如何拷贝完一个字节找到后一个字节。
#include <stdio.h>
#include <assert.h>
void* my_memcpy(void* dest, const void* src, size_t num)
{
assert(dest && src);
// 先保存目的地的开头地址,以便于返回
void* ret = dest;
while (num--) // 当num为0拷贝字节数已够,拷贝结束
{
// 强转成char*的指针,因为这样,才是一个字节一个字节的拷贝
*(char*)dest = *(char*)src;
// 强转成char*指针++向后走跳过一个字节,为下一次的字节拷贝做准备;
++(char*)dest;
++(char*)src;
}
return ret;
}
int main()
{
int a1[] = { 1,2,3,4,5,6,7,8,9,10 };
int a2[] = { 9,9,9,9,9 };
my_memcpy(a1, a2, 20);
// 20:a2的总字节数
for (int i = 0; i < sizeof(a1) / sizeof(a1[0]); ++i)
{
printf("%d ", a1[i]);
}
return 0;
}
运行结果为:
9 9 9 9 9 6 7 8 9 10
如果我们用自我实现得功能来进行重叠拷贝:

运行结果为:

- 为什么会这样呢?
1和2拷贝过去,此时arr原有的第三个和第四个元素(3和4所在位置)也被改为了1和2,当拷贝第三个元素时,是将1拷贝过去而不是原先的3了。- 但如果是
memmove就不会有这样的情况.
memmove
该函数的功能也相当于是
“内存拷贝”,它包含了memcpy的功能,同时比memcpy函数更为的强大,它可以对重叠的内容进行拷贝,也就是一个数组arr[] = {1,2,3,4,5,6,7,8,9,10},1,2,3,4,5要拷贝到3,4,5,6,7上去,最终数组内容变为1,2,1,2,3,4,5,8,9,10。


memmove函数的使用
#include <stdio.h>
#include <string.h>
int main()
{
int a1[] = { 1,2,3,4,5,6,7,8,9 };
int a2[] = { 6,6,6,6,6 };
memmove(a1, a2, 20);
for (int i = 0; i < sizeof(a1) / sizeof(a1[0]); ++i)
{
printf("%d ", a1[i]);
}
return 0;
}
运行结果为:
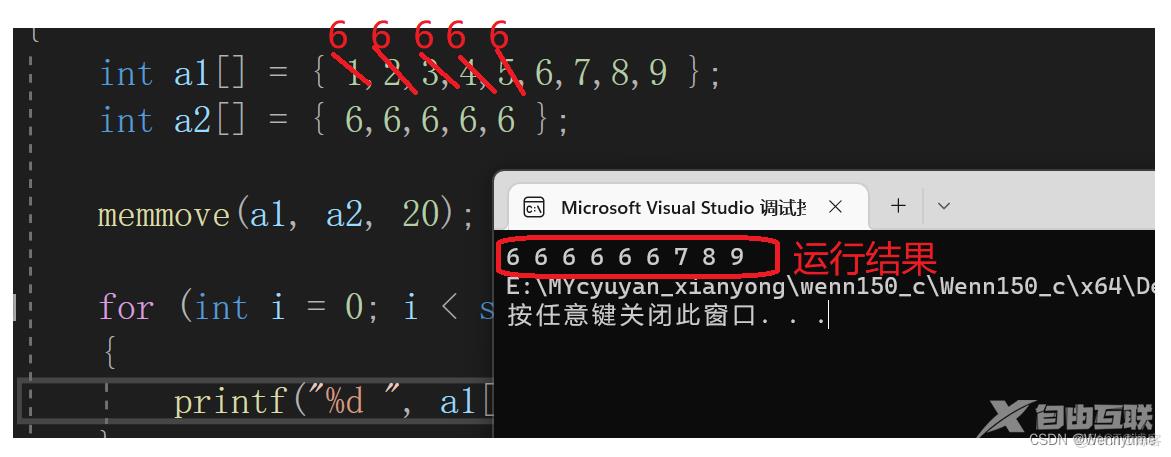
- 可以看到,这种拷贝的功能与memcpy是一样的,接下来进行不一样的重叠拷贝:
#include <stdio.h>
#include <string.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
memmove(arr + 2, arr, 20);
// 将 1 2 3 4 5 拷贝到 3 4 5 6 7 上面去
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
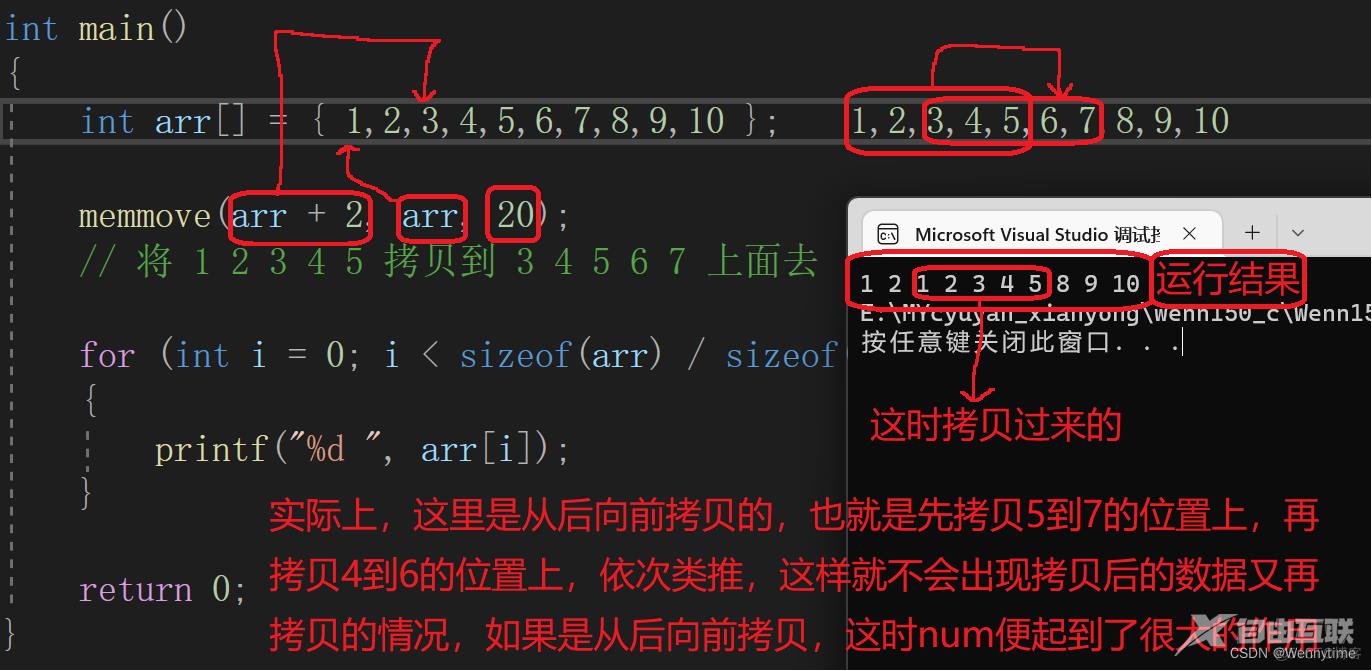
-
把
arr + 2当作dest,arr当作src,也就是说此时src要小于dest,即得出当src < dest时由后往前拷贝; -
这里是
memmove(arr + 2, arr, 20),如果是memmove(arr, arr + 2, 20)(将3,4,5,6,7拷贝到1,2,3,4,5上面去)呢?此时arr + 2为src,arr为dest,这时候就需要从前向后拷贝了,也就是src > dest的情况,即得出当src > dest时由前向后拷贝。 -
还有一种情况:
memmove(arr, arr + 5, 20)是把6,7,8,9,10拷贝到1,2,3,4,5上去,这时虽然src大于dest,但是src与dest的字节差值大于等于了num,也就是说无论是从前向后拷贝还是从后向前拷贝都是一样的,此时的功能就可以理解为是memcpy的功能了。
memmove函数的自我实现
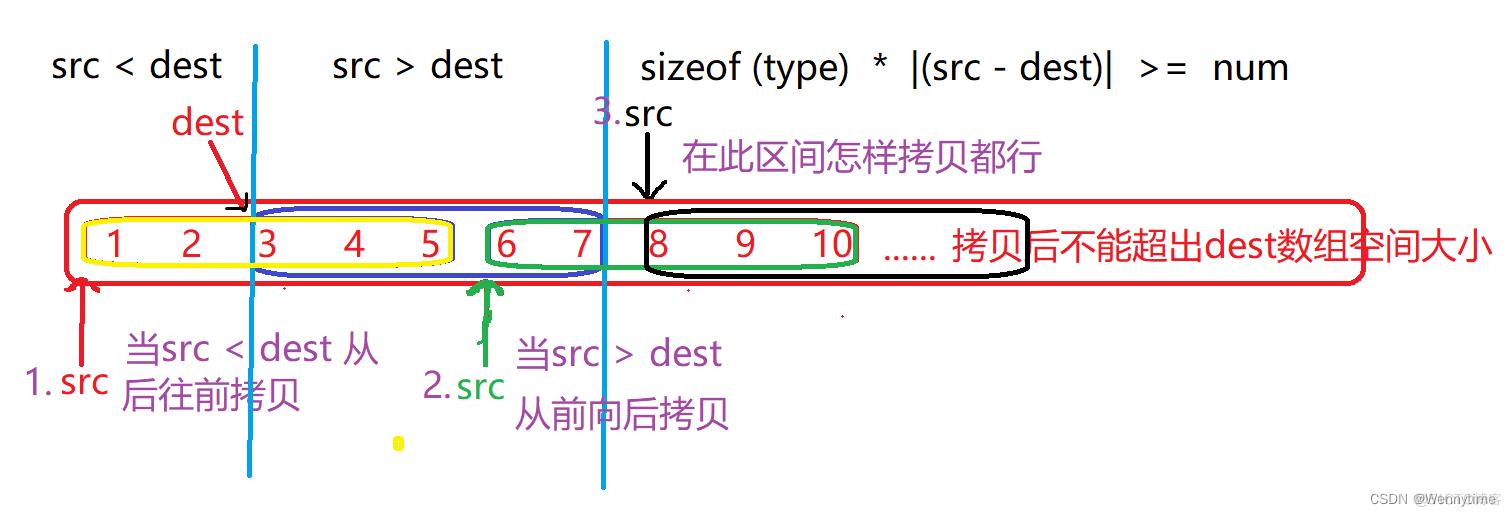
- 通过上面的使用和分析,有三种情况都是要考虑到: 1.从前向后拷贝
src > dest; 2.从后向前拷贝src < dest; 3.从后向前还是从前向后都是可以的sizeof(type) * |(src - dest)| >= num。
代码实现:
#include <stdio.h>
#include <assert.h>
void* my_memmove(void* dest, const void* src, size_t num)
{
assert(dest && src);
void* ret = dest;
// 落在第三区间总会进一种拷贝方式
if (src < dest)
{
// 从后往前
while (num--) // 因为判断后 num-- 一次,第一次进来如果num开始为20,
{ // 进来后等于19找到最后一个字节拷贝
// 随着num--,拷贝的字节从后往前依次跳一个字节
*((char*)dest + num) = *((char*)src + num);
}
}
else
{
// 从前往后
while (num--)
{
// 这里跟上面的memcpy的自我实现差不多,但是memcpy也可以以从后往前的方式实现
*(char*)dest = *(char*)src;
++(char*)dest;
++(char*)src;
}
}
return ret;
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
my_memmove(arr + 2, arr, 20);
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); ++i)
{
printf("%d ", arr[i]);
}
return 0;
}
运行结果为:
1 2 1 2 3 4 5 8 9 10
实现了重叠拷贝,当然其它案例也行,这里大家自行测试了。
memcmp
- 该函数是比较函数,与strncmp的功能相同,只不过memcmp的对比类型不单只是字符类型了。
- memcmp是一个字节一个字节的对比。
函数参数如下:



函数的返回值:如果前num个字节ptr1与ptr2都相等,则返回0,如果找到第一个不相等的字节,返回ptr1的这个字节减去ptr2的这个字节的差值。
memcmp函数的使用
1.
#include <stdio.h>
#include <string.h>
int main()
{
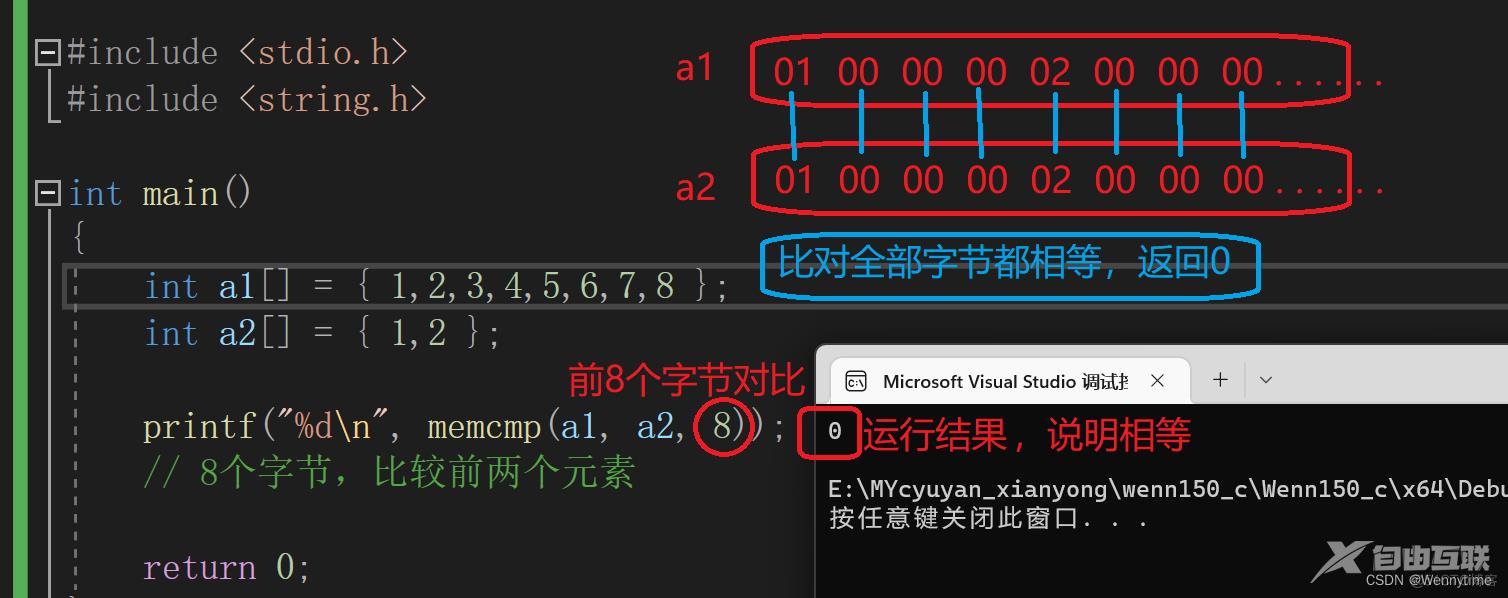
int a1[] = { 1,2,3,4,5,6,7,8 };
int a2[] = { 1,2 };
printf("%d\n", memcmp(a1, a2, 8));
// 8个字节,比较前两个元素
return 0;
}
 2.
2.
#include <stdio.h>
#include <string.h>
int main()
{
int a1[] = { 1,2,3,4,5,6,7,8 };
int a2[] = { 1,2,5 };
printf("%d\n", memcmp(a1, a2, 12));
// 12个字节,比较前三个元素
return 0;
}
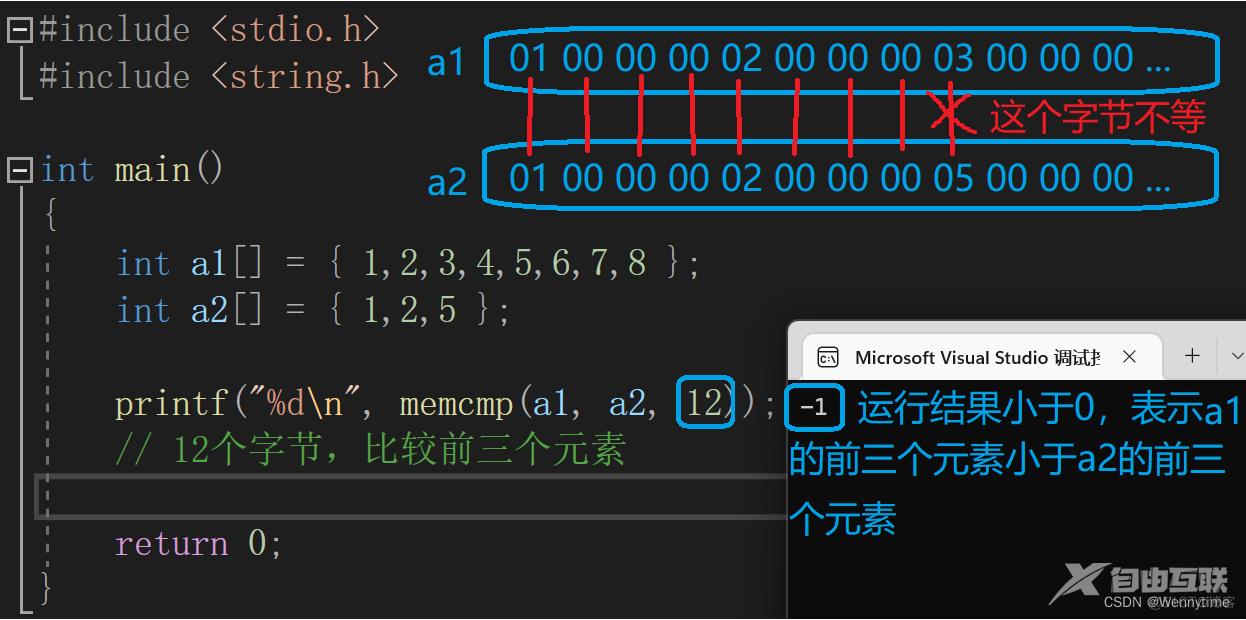
由于
vs的memcmp标准是小于就返回-1,大于就返回1,所以这里的结果为-1。
memcmp函数的自我实现
经过上面的介绍,我们大概知道了这个函数的功能,接下来自我实现这个函数。
#include <stdio.h>
#include <assert.h>
int my_memcmp(const void* ptr1, const void* ptr2, size_t num)
{
assert(ptr1 && ptr2);
// 比对次数--
while (num--)
{
// 如果有不相同的字节,这里为真,进去返回差值
if (*(char*)ptr1 - *(char*)ptr2)
return *(char*)ptr1 - *(char*)ptr2;
++(char*)ptr1;
++(char*)ptr2;
}
// 比对完了没有找到不相同的字节说明都相同,返回0;
return 0;
}
int main()
{
int a1[] = { 1,2,3,4,5,6,7,8 };
int a2[] = { 1,2,5 };
printf("%d\n", my_memcmp(a1, a2, 8));
// 12个字节,比较前三个元素
return 0;
}
运行结果为:
-2
memset
该函数的功能是填充内存块,也就是将一个数组里面你指定的内容以修改字节的形式修改成你想要的数据。

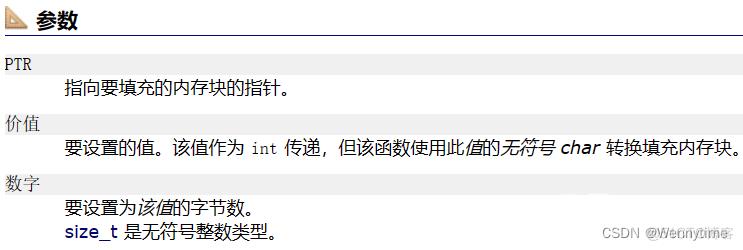
这里的value虽然是int,但是字符也可以修改,因为字符类型本身就是整型家族,字符可以通过ASCLL码值来进行转换。
memset函数的使用
#include <stdio.h>
#include <string.h>
int main()
{
char arr[] = "xxxxxxxxxx";
printf("%s\n", (char*)memset(arr, 'y', 5));
return 0;
}
 2.
2.
#include <stdio.h>
#include <string.h>
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%s\n", (char*)memset(arr, 1, 40));
// 40表示整个arr的字节个数
return 0;
}
运行结果为:
16843009 16843009 16843009 16843009 16843009 16843009 16843009 16843009 16843009 16843009
为什么运行结果会是这样子呢?
- 我们将数组
arr40个字节都改为1,一个整型有4个字节,如果每一个字节上面都是1,在内存当中每个整型的存放是这样的:01 01 01 01,所以当我们从内存中将这个数据读取出来的时候,那将会是一个很大的数,就如上面的运行结果一样的。- 所以对于整型数组我们一定要避免出现这样的情况,要牢记这是一个字节一个字节的修改。
memset函数的自我实现
通过上面的认识,下面自我实现memset函数:
#include <stdio.h>
#include <assert.h>
void* my_memset(void* ptr, int value, size_t num)
{
assert(ptr);
void* ret = ptr;
while (num--)
{
*(char*)ptr = value;
++(char*)ptr;
}
return ret;
}
int main()
{
char a[] = "abcdefgh";
printf("%s\n", (char*)my_memset(a, '@', 5));
return 0;
}
运行结果为:
@@@@@fgh
写在最后
在C语言中,熟练的使用内存函数可以说对内存的理解也是很不错的,能够以内存的视角观察代码,说明你的水平已经很不错了。
感谢阅读本小白的博客,错误的地方请严厉指出噢!