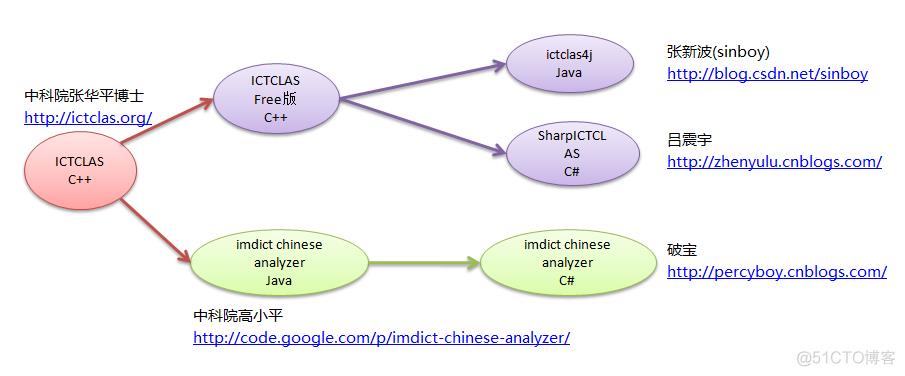
中文切词领域,中科院开发的 ICTCLAS 占有重要一席,号称是世界上最好的中文分词系统。ICTCLAS 初期曾发布过一个免费版本(C++),采用“自然语言处理开放资源许可证”公开。后来走向商业开发道路,最新版本是 ICTCLAS 2010,提供有 C++, Java, C# 等多种版本可供购买。
从 ICTCLAS Free 版有一些衍生版本:ictclas4j 是张新波(sinboy)移植的 Java 版本,SharpICTCLAS 是吕震宇移植的 C# 版本。这两个版本也采用“自然语言处理开放资源许可证”。
2009年中科院高先生针对 Lucene 用 Java 重写了 ICTCLAS 代码,采用 Apache Licence 2.0 协议公开了源码和词库数据,目前已并入了 Lucene contrib 代码树中。我花了些时间将这个版本转写为 C# 版。
下图表示了这些版本间的关系:(红色为商业软件,紫色为“自然语言处理开放资源许可证”,绿色为“Apache Licence 2.0”)
目前讨论较多的切词器,如庖丁解牛、盘古分词等,多采用查词典的方式切分,词典质量决定切分效果。
ICTCLAS 切词基于概率统计的语料库(高先生称之为“智能词典”),算法基于“层叠式隐含马尔可夫模型”(Hierarchical Hidden Markov Model, HHMM)。仅就算法而言,应该说这是一种较为先进的方法,Google 研究员也说“统计语言模型比任何已知的借助某种规则的解决方法都有效”(数学之美系列)。
但是高先生贡献的版本(包括我转写的版本),从 ICTCLAS 中去除了一些功能,如:词性标注、人名识别、日期识别等等,特别是后两项,切分结果在这方面不是很理想。另外,“智能词典”里存储的是各种词汇出现的概率,是通过机器训练得到的,难以采用人工方式维护,这也是一个不方便之处。