今年的收益是否真的与典型年份的预期不同?差异实际上与典型年份的预期不同吗?这些都是容易回答的问题。我们可以使用均值相等或方差相等的测试。
但是下面这个问题呢。
今年的收益概况与一般年份的预期情况是否不同?
这是一个更加普遍和重要的问题,因为它包括所有的时刻和尾部行为。而且它的答案也不那么简单。
我在想一定有一种方法可以检验收益密度之间的差异,而不仅仅是量化、可视化和用眼睛看。确实有这样的方法。这篇文章的目的是展示如何正式检验密度之间的平等。
事实上,至少有两种方法可以检验两个密度或两个分布之间的平等。第一种是比较经典的。这种检验被称为Kolmogorov-Smirnov检验。另一种是比较现代的,使用Permutation Test置换检验(需要模拟)。我们展示这两种方法。让我们先拉出一些价格数据。
1.
2. end<- format(Sy.D, "%Y-%m-%d")
3. l = lenh
4. da0 <- lay
5. Time <- index
6. ret <- as.numeric/as.numeric -1
7. tail(rt)
8. # 得到直到2018年的指数。
9. # 我们随后将2018年与其他年份进行比较
10. tid<- which(index)
11.
12. # 每日收益的平均值和SD(2018年除外)
13.
14. > mean(100*rt[1:pd])

> SD(100*retd[1:tid])
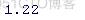
- > # 2008年(到目前为止)每日回报的平均值和SD值
- > mean(100*rtd[-c(1:tpd)])
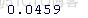
> SD(100*red[-c(1:mid)])
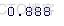
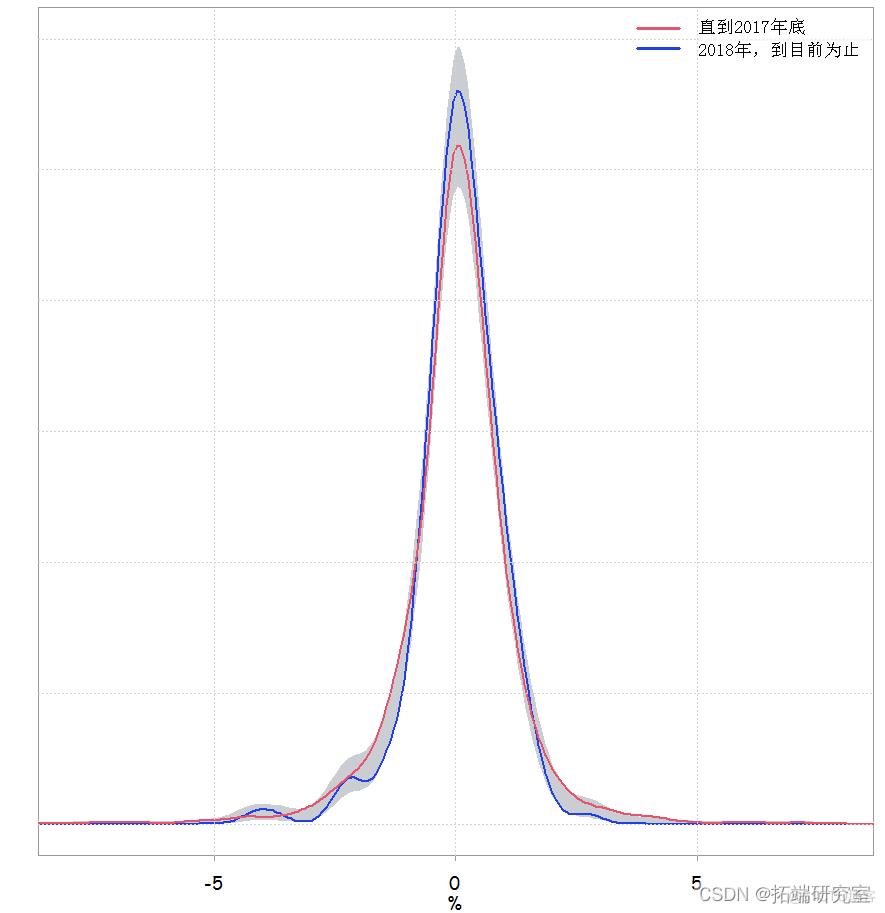
我们可以看到,2018 年每日收益的均值和标准差与其余的均值和标准差略有不同。这是估计密度的样子:
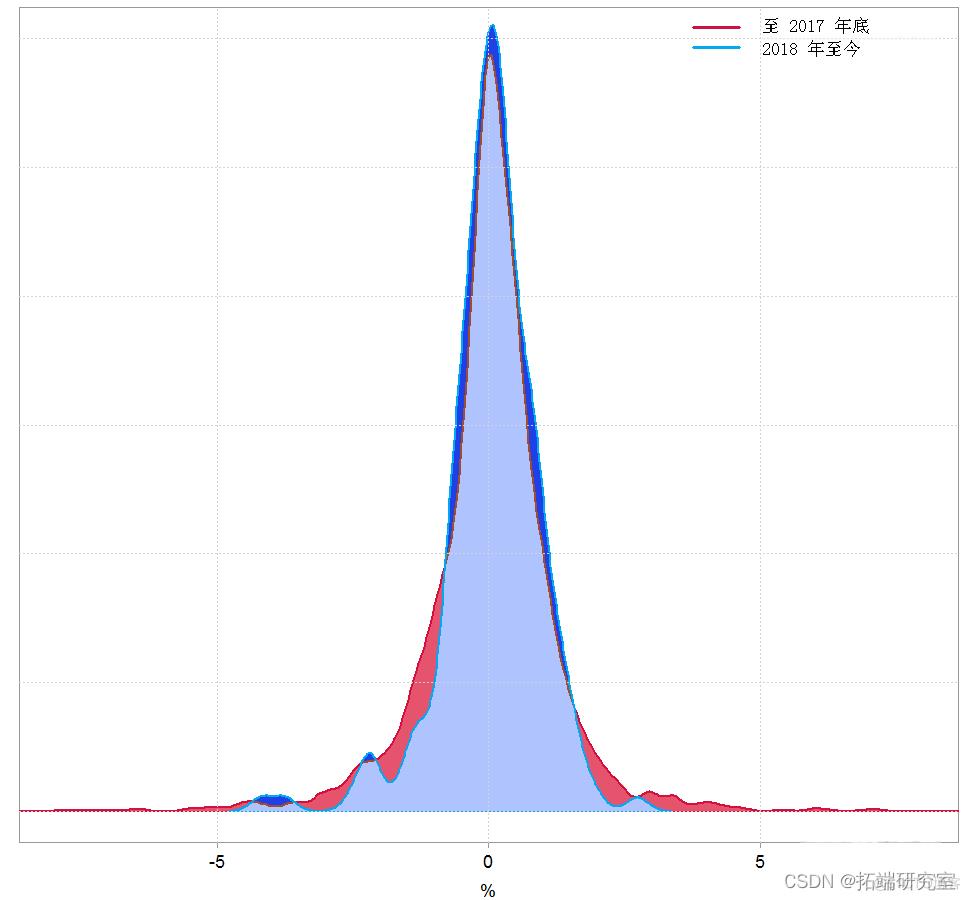
Kolmogorov-Smirnov 检验
我们可以做的是计算每个密度的累积分布函数
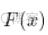
。2018年的那个和不包括2018年的那个。说
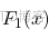
分布是针对2018年的,

分布是针对其他的。我们计算每个X的差异
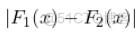
。我们知道这些(绝对)差异的最大值是如何分布的,所以我们可以用这个最大值作为测试统计量,如果它在尾部的分布太远,我们就认为这两个分布是不同的。从形式上看。
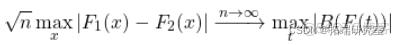
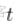 介于 0 和 1 之间(通过构造,因为我们减去两个概率并取绝对值)。
介于 0 和 1 之间(通过构造,因为我们减去两个概率并取绝对值)。
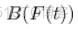
是一个 Brownian bridge. (最大)差异具有已知分布。这是一个极限分布,所以我们需要大量的观测值 n 才能对这个检验有信心。
Kolmogorov-Smirnov 测试 - R 代码
让我们将 2018 年的每日收益与其余收益进行比较,看看基于 Kolmogorov-Smirnov 检验的分布是否相同:
- # Kolmogorov-Smirnov测试 ####
- ks.test

我们看到,最大值是0.067,根据极限分布,P值是0.3891。所以没有证据表明2018年的分布与其他的分布有任何不同。
让我们来看看置换检验。主要原因是,鉴于Kolmogorov-Smirnov 检验是基于极限分布的,为了使其有效,我们需要大量的观察结果。但是现在我们不必像过去那样依赖渐进法,因为我们可以使用计算机。
两个密度相等的置换检验Permutation Test
直观地说,如果密度完全相同,我们可以把它们放在一起,从 "捆绑数据 "中取样。在我们的例子中,因为我们把收益率聚集在一个向量中,对向量进行排列意味着2018年的每日收益率现在分散在向量中,所以像上面的方程那样取一个差值,就像从一个无效假设中进行模拟:2018年每日收益率的分布与其他的完全相同。现在,对于每个x,我们将有一个在原假设下的差异。我们也有每个x的实际差异,来自我们的观察数据。我们现在可以将密度之间的实际差异(每个x)平方(或取绝对值),并将其与我们从 "数据 "生成的模拟结果进行比较。通过观察实际差异落在模拟差异的哪个四分位数,可以估计出p值。如果实际数据远远超出了原假设下的分布范围,那么我们将拒绝分布相同的假设。
密度比较置换检验 - R 代码
我们来执行刚刚描述的操作。两个参数 boot 和grid 是您想要的模拟数量以及您在计算 x 时想要使用的网格点数
")
. 因此 ngrid=100 。
- # 我们需要两组的索引,2018年和其他的。
- id <- substr
- tmnd <- i1 == 2018
- sme
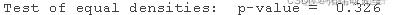
我们可以看到 p 值与我们使用 Kolmogorov-Smirnov 检验得到的值差别不大。这是它的样子:
等密度检验:p 值 = 0.326