先看一下官网给我们提供的全部的参数配置项
官网地址
官方文档链接:注意版本是8.1Configuring Elasticsearch | Elasticsearch Guide [8.1] | Elastic编辑https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html




重要(基本)参数
Important Elasticsearch configuration
关于分片和路由的配置
Cluster-level shard allocation and routing settings
分片的配置,用于集群重启时候的分片恢复、副本分配问题、分片平衡问题、以及删除节点的时候触发生效。
master节点负责分片分配的相关问题:包括了分片去哪个节点,以及节点之间的分片平衡(当一个节点上的数据过多,与其它节点分配不均匀的时候,master节点负责重新平衡)。
分片分配相关参数
参数:cluster.routing.allocation.enable
cluster.routing.allocation.enable
用来限制不同的分片能否在某个节点上分配:all- (默认)允许分配所有类型的分片。primaries- 只允许分配主分片。new_primaries- 仅允许新索引的主分片分配。none- 不允许对任何索引进行任何类型的分片分配。该设置不影响重启节点时本地主分片的恢复。具有未分配主分片副本的重新启动节点将立即恢复该主分片,假设其分配 id 与集群状态中的活动分配 id 之一匹配。
这里的优化点,我们可以靠谱的机器分配主分片。可能有问题的机器,可以限制主分片的分配。
cluster.routing.allocation.node_concurrent_incoming_recoveries
副本在当前节点分配的并发数。比方说,你的索引只有主分片,没有副本。你想要添加副本,则你就要在别的机器上去分配副本。
默认值为:2
增大该配置,可以提升添加副本的速度。但是它意味着花费更多的资源。假如你不考虑集群当前服务能力,就想快速添加副本,则可以增大该配置。具体的可以增加到多大。需要做压力测试。根据不同的机器资源,有不同的效果。
cluster.routing.allocation.node_concurrent_outgoing_recoveries
最大允许同时多少个分片去别的机器上恢复。
默认值为:2
增大该配置,可以提升添加副本的速度。但是它意味着花费更多的资源。假如你不考虑集群当前服务能力,就想快速添加副本,则可以增大该配置。具体的可以增加到多大。需要做压力测试。根据不同的机器资源,有不同的效果。
cluster.routing.allocation.node_concurrent_recoveries
该参数合并了cluster.routing.allocation.node_concurrent_incoming_recoveries和cluster.routing.allocation.node_concurrent_outgoing_recoveries这两个参数。意思是只配置当前这个参数,以上两个参数都会生效。cluster.routing.allocation.node_initial_primaries_recoveries
当节点重启后,或者说集群重启后,主分片恢复的并发数。假如一个节点上有20个主分片。那么,如果默认4个并发,则需要分五次,才能把这个主分片全部恢复起来。或者说同时只能有四个主分片一起恢复。
默认值为:4
这个参数可以用来提升集群故障重启后的集群恢复速度。我们可以适当增大它。能够增大多少,也是需要具体的压力测试。根据机器资源不同,可增大就不同。
目前我认为这个参数是和CPU能力挂钩的。
另外我认为:集群恢复,我能可以调大它。不用考虑此时集群服务能力。说白了,主分片如果都没回复全,肯定对外提供查询,它是有问题的。
注意一点,所谓的参数调优,每个参数都不是孤立的,它要和其它参数一起配合来使用。
cluster.routing.allocation.same_shard.host
这个参数只会在一台物理机器上多个节点的时候才会有用。
默认配置:falsecluster.routing.allocation.same_shard.host: true 禁止把副本分配到同一台物理机器上(相同ip地址认为是同一台机器)cluster.routing.allocation.same_shard.host: false 可以把副本分配到同一台物理机器上。如果一台物理机器只有一个节点,默认为false也没什么问题,因为副本不会分配到同一个机器上。但是一台机器上有多个节点,就失去数据容灾的能力了,也不能将请求均分到其它机器上去。
分片平衡配置
分片平衡问题,对于es集群来说,它其实是希望数据能按大小均匀分不到不同的节点上的。当发生数据倾斜的时候,集群会有一个自动的平衡机制,帮你把分片挪到别的节点上。
这里有一个点,就是我们在组建集群的时候,最好能够将每台机器,或者说每个节点,能用的磁盘空间对齐。避免节外生枝。
cluster.routing.rebalance.enable
设置哪些分片能够重新平衡:
all- (默认)允许对所有类型的分片进行分片平衡。primaries- 仅允许对主分片进行分片平衡。replicas- 仅允许对副本分片进行分片平衡。none- 任何索引都不允许任何类型的分片平衡。
cluster.routing.allocation.allow_rebalance
指定何时允许分片重新平衡:
always- 始终允许重新平衡。indices_primaries_active- 仅当分配了集群中的所有主节点时。indices_all_active- (默认)仅当集群中的所有分片(主分片和副本)都已分配时。这个阶段显然是最安全的。不要掺和太多事,等集群稳定的时候去平衡。
cluster.routing.allocation.cluster_concurrent_rebalance
设置集群中,执行分片重新平衡的并发数。默认值为2的情况下,一个集群中最多能有2个分片同时去执行重新平衡。
默认值:2
分片平衡规则设置
上边只提到了。集群会自动平衡节点中的分片。那策策略是什么呢?或者说规则是什么呢?
cluster.routing.allocation.balance.shard
(动态)定义节点上分配的分片总数的权重因子(浮点数)。默认为0.45f. 提高这一点会增加集群中所有节点上的分片数量相等的趋势。
从这里我们可以知道,es只能保证分片数量平衡。
那么再提出来一个问题:假如分片的大小并不平衡呢?
cluster.routing.allocation.balance.index
(动态)定义分配在特定节点(浮点数)上的每个索引的分片数的权重因子。默认为0.55f. 提高这一点会增加集群中所有节点上每个索引的分片数量相等的趋势。
cluster.routing.allocation.balance.threshold
(动态)应该执行的操作的最小优化值(非负浮点)。默认为1.0f. 提高此值将导致集群在优化分片平衡方面不那么积极。
与磁盘相关的分片设置
关于磁盘的保护。我们很容易就可以理解,我们的磁盘总不能写满吧?es集群给我们增加了这个控制。特地设置了三个水位线,一个最低水位线,一个控制水位线,一个最高水位线。看下图三条线。这个水位线是说磁盘使用量占比。
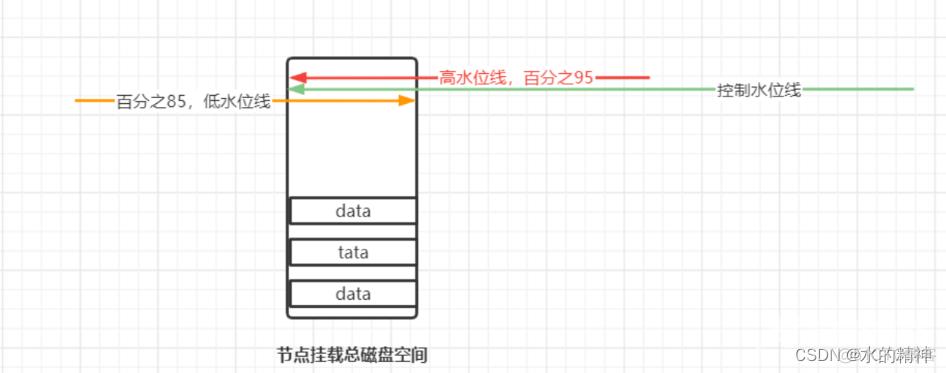
当磁盘空间倾斜的时候,es需要自动调整。假如我们物理节点的磁盘大小不一致。节点A分配1T磁盘,节点B分配10T磁盘,如果同样是每个上边分配相同的分片。同样都写入数据,显然A节点先到达最低水位线。
所以磁盘有一个限制。当写入磁盘到达橙色低水位线的时候,副本将无法再在这个节点上分配。
当到达控制水位线,就会进入一个挪分片阶段。这个阶段会把分片挪到别的节点上去,以达到磁盘平衡的目的。
当所有的节点都达到了控制水位线的时候,就不能再挪分片了,分片也没有地方去了。此时还能继续写入数据,当写入直到最高水位线的时候,不行了,集群不再接受写入请求了!此时能读,能删除。
这里有一个集群规划-磁盘规划方面的优化点。
我们知道这个挪分片的过程,数据不会自己从一个磁盘飞到另外的磁盘。它是要花资源的,占用CPU,占用磁盘IO,占用网络IO。
所以我们要尽可能的分配均匀的磁盘给每个节点。尽可能的避免这个挪的过程,从而避免资源占用。
另外如何磁盘大小不一样。我们通过上边的参数知道,它是按比例来算的。也就是有可能在极端情况下:假如三个节点,磁盘分别是 1T,10T,10T。假如数据都装85%,这意味着,一次搜索,一个节点处理850G数据,另外两个节点每个处理8.5T。这相当于只有两个节点在工作。从而失去了集群的意义。
可以使用以下设置来控制基于磁盘的分配:
cluster.routing.allocation.disk.threshold_enabled
(动态)默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.watermark.low
(动态)控制磁盘使用的低水位线。默认为85%,这意味着 Elasticsearch 不会将分片分配给磁盘使用率超过 85% 的节点。它也可以设置为绝对字节值(如500mb),以防止 Elasticsearch 在可用空间少于指定数量时分配分片。此设置对新创建索引的主分片没有影响,但会阻止分配它们的副本。
cluster.routing.allocation.disk.watermark.high
(动态)控制水位线。它默认为90%,这意味着 Elasticsearch 将尝试将分片从磁盘使用率高于 90% 的节点,开始挪分片去其他节点。
cluster.routing.allocation.disk.watermark.flood_stage
(动态)高水位线,默认为 95%。index.blocks.read_only_allow_deleteElasticsearch对在节点上分配了一个或多个分片并且至少有一个磁盘超过洪水阶段的每个索引强制执行只读索引块 ( )。此设置是防止节点耗尽磁盘空间的最后手段。当磁盘利用率低于高水位线时,索引块会自动释放。
注意以上配置需要对齐,要么都用百分比,要么都指定具体大小。
cluster.info.update.interval
(动态)Elasticsearch 应该多久检查一次集群中每个节点的磁盘使用情况。默认为30s.
以下两个参数没看懂:等看懂了再来补。
cluster.routing.allocation.disk.watermark.flood_stage.frozen(Dynamic) Controls the flood stage watermark for dedicated frozen nodes, which defaults to 95%.
cluster.routing.allocation.disk.watermark.flood_stage.frozen.max_headroom(Dynamic) Controls the max headroom for the flood stage watermark for dedicated frozen nodes. Defaults to 20GB when
cluster.routing.allocation.disk.watermark.flood_stage.frozenis not explicitly set. This caps the amount of free space required on dedicated frozen nodes.
search相关设置
限制搜索条件包含的搜索子句
参数: indices.query.bool.max_clause_count
默认值:4096
这个默认配置是偏大的。这个我们可以调小。用来对集群的保护。
聚类结果数(桶的个数,例如你去 agg terms,获取聚类结果)
参数: search.max_buckets
默认是:65536
这里建议聚类结果,不要一下子返回,通常情况,可以利用 compsit滚动导出聚类结果。
这个不难理解,比方说你一共有100亿数据,让你一下子从集群中拿出20亿。这也不现实,集群做不到这件事,肯定要滚动利用游标的方式导出。
嵌套查询的层数
就是嵌套查询最多有几层
参数: indices.query.bool.max_nested_depth
默认值:20
index相关配置
是否允许自动创建索引
参数: action.auto_create_index
默认值:true
删除索引是否要指定索引名称
参数: action.destructive_requires_name
默认值:false,如果设置为true,则不能通过通配符来删除索引。
是否允许关闭索引
参数: cluster.indices.close.enable
默认值:true。如果设置为false,则不能关闭索引。
关闭索引,会释放内存空间,但是不会释放磁盘空间。
跨集群数据同步白名单
由 ip:port字符串数组组成
参数: reindex.remote.whitelist
例如: reindex.remote.whitelist : ["10.10.10.10:9200", "10.10.10.11.9200:*"]
是否启用内置索引和组件模板
参数:stack.templates.enabled
默认为true,如果为false,则es不会自动为你创建以下这些索引。
此设置影响以下内置索引模板:
logs-*-*metrics-*-*synthetics-*-*
此设置还会影响以下内置组件模板:
logs-mappingslogs-settingsmetrics-mappingsmetrics-settingssynthetics-mappingsynthetics-settings
控制集群是否能写入数据
控制集群只读: cluster.blocks.read_only
控制集群可读可以删除: cluster.blocks.read_only_allow_delete
集群分片数设置
限制单个节点最大的分片数:cluster.max_shards_per_node
默认值:1000
所以集群的总的主分片和副本分片总数为 cluster.max_shards_per_node * 数据节点的个数
如果索引被关闭,则其分片数不计数。
这个很多人给的建议是:每1G堆内存,对应20个分片。假如你给堆分配30G堆内存,则该节点分片数最好不要超过600个。这个默认是每个节点1000个,调优的时候通常是降低这个默认值,而不是增大它。
限制单个节点上存在冻结的分片: cluster.max_shards_per_node.frozen
向理解以下什么冻结的分片,换句话说,就是关闭的分片。比如一个,索引有十个分片,一共两个节点,假如每个节点5个分片,将索引close掉,那么这5个分片就算是冻结分片。如果还不懂,看下边这篇文章。
关于什么是冻结索引?
ES冻结索引_51CTO博客_es冻结索引 占多少内存
Field data cache 设置
参数: indices.fielddata.cache.size
取值:可以是百分比,例如: 20% 。也可以制定是 5GB。
注意熔断器中也有参数限制Field data cache 的大小。并且默认值是 40%。所以如何设置这个参数的时候要比40%小。
关于Field data cache,请看下边的这篇文章:
elasticsearch中 fieldData_elasticsearch fielddata_水的精神的博客
永远不要尝试打开它。它是性能的杀手。我们不要对text类型的字段排序,聚类!如果真的需要,就同时给它设置一个keyword类型,利用doc values,而不是构造Field data!
index buffer cache
用作写缓存。分配的是堆空间。
indices.memory.index_buffer_size
接受百分比或字节大小值。它默认为10%,这意味着10%分配给节点的总堆将用作所有分片共享的索引缓冲区大小。
indices.memory.min_index_buffer_size
如果index_buffer_size指定为百分比,则此设置可用于指定绝对最小值。默认为48mb.
indices.memory.max_index_buffer_size
如果index_buffer_size指定为百分比,则此设置可用于指定绝对最大值。默认为无界。
Node query cache
节点级别的缓存。
es节点可以缓存查询的结果。
参数: index.queries.cache.enabled 是否开启节点请求结果缓存。
默认值:true。代表节点默认是会缓存查询数据的。
默认情况下,缓存最多可容纳 10000 个查询 。段合并会导致缓存失效!
参数: indices.queries.cache.size 节点分配个查询缓存的堆大小。
默认值:10%。 也就是说有百分之十的堆空间,用于节点的请求缓存。
它是LRU的策略来进行替换的。但是不会被GC回收掉!
Shard requests cache
分片级别的缓存。
通常情况下缓存 查询结果为0的数据。例如: aggregations, andsuggestions.
为了保证搜索的实时性和搜索结果的最终一致性。分片级别的缓存,会在执行 refreshe 的时候失效。
所以说,分片级别的缓存生效的时间,取决于 refreshe的时间间隔。缓存和实时性,是不可兼得的一件事请!
参数:index.requests.cache.enable 是否开启分片级别的缓存。
默认值:true。开启
另外我们可以在一次请求的时候指定是否缓存本次结果在分片上。
GET /my-index-000001/_search?request_cache=true{ "size": 0, "aggs": { "popular_colors": { "terms": { "field": "colors" } } } }
参数:indices.requests.cache.size 分片缓存占用堆内存的大小
默认值:1%
快照与恢复配置
快照操作的最大并发数。操作包括快照创建,删除和复制。
参数: snapshot.max_concurrent_operations
默认值:1000
快照生命周期管理配置
是否把记录快照历史操作
参数: slm.history_index_enabled
默认值:true
快照的执行周期
参数: slm.retention_schedule
可以是 cron表达式: 0 30 1 * * ?
多长时间删除快照
参数: slm.retention_duration
默认值:1小时
允许用来快照恢复的url
参数:repositories.url.allowed_urls
线程池相关设置
通常情况下,我们对es集群下发的命令,例如search、index、agg、suggest,段合并,等等。都交由不同的线程池来完成执行。这个其实不难理解,线程是任务调度的最小单元。对es来说也是。
先来聊一聊物理机器的CPU
一个物理节点对应一个es节点,是理想情况。es会自动检测CPU的个数,这并不难。但是如果一台机器有多个节点,就有问题了。因为es没有那么智能,它会傻傻的以为,当前的CPU都是给自己一个节点用的。这种情况下,会很大程度上降低es的性能。
假如一台机器上有多个节点,请告诉node,它该分几个核心!
以下参数可以设置CPU核心数。假如一台机器,总的核心数是32,假如你的机器上分配了两个节点,你可以设置为16,此时每个节点正好分配16个核心。 16核心是一个节点的理想核心数!
node.processors: 2
再聊一下线程池!如果熟悉线程池原理,应该知道,线程池可以有固定线程数的线程池,也有弹性的线程池。提交的任务会优先给线程处理,如果处理不过来,自然要把这些任务放在任务队列里。如果任务队列还满的话,那自然要触发拒绝策略了。
在看es 线程池相关的配置参数的时候,我们主要关注,线程池的功能,线程池是否是固定线程数,以及其任务队列的大小。
generic线程池
参数:generic
用于集群运行的幕后工作者,例如:用于节点的发现。
用于search的线程池
参数:search
例如: count、search、suggest
固定线程数:(CPU核心数 * 3 / 2 + 1)
任务队列:1000
下边这个我不太懂
search_throttled
For count/search/suggest/get operations on search_throttled indices. Thread pool type is fixed with a size of 1, and queue_size of 100.
search_coordination
For lightweight search-related coordination operations. Thread pool type is fixed with a size of a max of min(5, (# of allocated processors) / 2), and queue_size of 1000.
get
For get operations
固定线程数:CPU核心数
任务队列:1000
analyze
用于获取语句的执行过程。
固定线程数:1个线程
任务队列大小:16
write
写操作:写、删除、更新、批量提交操作
固定线程数:CPU核心数 + 1
任务队列大小:10000
snapshot
For snapshot/restore operations. Thread pool type is scaling with a keep-alive of 5m and a max of min(5, (# of allocated processors) / 2).
生成快照数据。
线程数:min(5, (CPU核心数 + 1) / 2) 也就是,最多5个线程。
snapshot_meta
读取快照数据,用来恢复。
线程数:min(50, (CPU核心数* 3)).
warmer
用于段数据预热
线程数:min(5, (CPU核心数) / 2).
refresh
将数据从JVM堆内存,刷新到文件系统,生成段。
线程数:min(10, (CPU核心数) / 2).
fetch_shard_started
获取分片状态信息.
线程数:最大为 CPU核心数*2
fetch_shard_store
获取分片列表.
线程数:最大为 CPU核心数*2
flush
用于操作文件系统上的段数据(refresh之后的阶段),从文件系统落到磁盘上。
线程数: min(5, (CPU核心数) / 2).
force_merge
段合并的线程数。默认为1个线程。
注意,这个参数不要随意调。比较致命。因为段合并是一个非常花费资源的操作。如果真的要调大,可以在凌晨来段合并。
management
用于集群管理
默认 5 个线程
system_read
系统索引的读.
线程数: min(5, (CPU核心数) / 2).
system_write
系统索引的写
线程数: min(5, (CPU核心数) / 2).
system_critical_read
For critical read operations on system indices.
线程数: min(5, (CPU核心数) / 2).
system_critical_write
For critical write operations on system indices.
线程数: min(5, (CPU核心数) / 2).
watcher
用于集群监控
线程数: min(5 * (CPU核心数), 50)
任务队列:1000
我们可以通过以下配置,来指定线程数。
thread_pool: # 指定线程池类型 write: # 指定线程数 size: 30 # 指定任务队列大小 queue_size: 1000
集群与注册相关配置
es有天然的集群自动组成方式。我们只需要简单的配置,节点就会自动组成集群。做分布式应用,es的集群策略是值得我们学习的!
一起看下和形成集群相关的参数配置
discovery.seed_hosts集群的节点列表(意思是指定哪些节点去进行通信,并形成集群)。
- 配置有两种形式:直接指定ip和端口号,多个用逗号分割。注意是ip:port的形式。如果不指定端口的话,默认是9300。9300是es节点间通信的端口。
- 如果地址是ipv4,举个栗子 ["10.10.10.10:9300", "10.10.10.11:9300"]
- 如果地址是ipv6,需要用中括号括起来。举个栗子 [ "10.10.10.10:9300", "[::1]:9300"]
- 也可以通过配置域名的方式。
举个栗子: seeds.mydomain.com
discovery.seed_hosts: - 192.168.1.10:9300 - 192.168.1.11 - seeds.mydomain.com - [0:0:0:0:0:ffff:c0a8:10c]:9301
discovery.seed_providers
这个参数是用来指定读取集群列表的形式。默认情况下,我们是把地址放在了elasticsearch.yml下,从配置文件中修改。
但是假如我们集群的节点需要动态调整的话,不太方便。所以官方给我们提供了其它的形式。比如放在一个单独的文件,我们可以动态的去修改它。
下边的案例是我们指定配置的节点列表放在文件里。 discovery.seed_providers: file 然后我们在es的config目录下(和elasticsearch.yml同级的目录),创建一个名字为: unicast_hosts.txt 的文件,然后在文件中放入节点的列表: 10.10.10.510.10.10.6:9305 10.10.10.5:10005 # an IPv6 address 注意注释内容用 #开头 [2001:0db8:85a3:0000:0000:8a2e:0370:7334]:9301discovery.type
该参数指定了es节点是集群模式。默认是 multi-node 。也就是集群模式,它允许新的节点进来。
如果按照以下设置,则单个节点为一个集群。 discovery.type: single-nodecluster.initial_master_nodes
该参数指定哪些节点可以作为master节点。注意这里指定的是节点的名称。 cluster.initial_master_nodes: - master-node-a - master-node-b - master-node-c
专家设置编辑
以下配置都是集群相关的配置,官方不建议修改。如果你熟悉它们,也可以修改!
discovery.cluster_formation_warning_timeout
默认值 10s
假如 经过了 10s,节点还没有形成集群,会记录一条warn级别的日志,discovery.cluster_formation_warning_timeout短语开头。master not discovereddiscovery.find_peers_interval
默认为1s.
设置经过多长时间,进行一次集群发现。discovery.probe.connect_timeout
默认为30s.
设置尝试连接到每个地址时的等待时间。discovery.probe.handshake_timeout
默认为30s.
设置尝试通过握手识别远程节点时等待多长时间。discovery.request_peers_timeout
默认为3s.
设置节点在再次询问其对等方之后将等待多长时间,然后才认为请求失败。discovery.find_peers_warning_timeout
默认为3m.
设置节点在开始记录描述连接尝试失败原因的详细消息之前尝试发现其对等点的时间。discovery.seed_resolver.max_concurrent_resolvers
默认为10.
在节点发现时,节点列表中假如配置了域名的方式,进行DNS查询的并发数。discovery.seed_resolver.timeout
默认为5s.
在节点发现时,节点列表中假如配置了域名的方式,每次DNS获取地址的超时时间。cluster.auto_shrink_voting_configuration
该参数指定是否在投票中排除离开的节点。假如一共四个节点,一个节点的机器坏了,我们认为该节点离开了。
该参数默认为 true,代表会自动踢出离开的节点。前提是总的节点数大于等于3.
假如设置为false,则不会踢出离开的节点,需要我们通过api来手动踢出。 voting configuration exclusions API.cluster.election.back_off_time
默认为100ms.
选举失败时,等待的时间。
从默认值更改此设置可能会导致您的集群无法选择主节点。cluster.election.duration
默认为500ms.
设置在选举失败以后每次选举花费多长时间。
从默认值更改此设置可能会导致您的集群无法选择主节点。cluster.election.initial_timeout
这默认为100ms.
该参数指定在第一选举之前,或者选举失败以后,允许多长时间用来做节点的初始化工作。
从默认值更改此设置可能会导致您的集群无法选择主节点。cluster.election.max_timeout
设置节点在尝试第一次选举之前等待多长时间的最大上限,防止因为网络不稳定有太多的节点没有加入进来。这默认为10s. 从默认值更改此设置可能会导致您的集群无法选择主节点。cluster.fault_detection.follower_check.interval
设置主节点检查从节点的等待时间。默认为1s. 从默认值更改此设置可能会导致您的集群变得不稳定。cluster.fault_detection.follower_check.timeout
设置主节点多长时间可以认为从节点不在了。
默认为10s. 从默认值更改此设置可能会导致您的集群变得不稳定。cluster.fault_detection.follower_check.retry_count
主节点检查从节点的次数,在失败多少次以后,可以认为该节点不在了。
默认为3.
从默认值更改此设置可能会导致您的集群变得不稳定。cluster.fault_detection.leader_check.interval
设置每个节点在选举前等待的时间。
默认为1s.
从默认值更改此设置可能会导致您的集群变得不稳定。cluster.fault_detection.leader_check.timeout
设置从节点判定主节点不在的时间.
默认为10s.
从默认值更改此设置可能会导致您的集群变得不稳定。cluster.fault_detection.leader_check.retry_count
设置从节点检查主节点是否存在的失败次数。
默认为3. 超过三次以后则从节点可以认为主节点不在了。
从默认值更改此设置可能会导致您的集群变得不稳定。cluster.follower_lag.timeout
集群状态在从节点更新的时间,默认是90s,如果集群状态在90s以后没有在从节点应用成功,则将该从节点从集群中移除。请参阅 发布集群状态。cluster.max_voting_config_exclusions
这个参数我暂时没明白是什么意思。
(Dynamic) Sets a limit on the number of voting configuration exclusions at any one time. The default value is
10. See Adding and removing nodes.
cluster.publish.info_timeout
默认值为10s。
主节点将集群状态应用在所有节点的时间。假如超过了默认值10s,则会记录一条日志。cluster.publish.timeout
设置主节点等待集群状态完全发布到所有节点的超时时间,除非discovery.type设置为single-node。默认值为30s。请参阅发布集群状态。cluster.no_master_block设置在没有master节点的时候不可以做的操作
此设置具有三个有效值:
all节点上的所有操作(读取和写入操作)都被拒绝。这也适用于 API 集群状态读取或写入操作,例如获取索引设置、更新映射和集群状态 API。write拒绝写操作。metadata_write只有元数据写入操作(例如映射更新、路由表更改)被拒绝,但常规索引操作继续工作。根据最后一个已知的集群配置,读取和写入操作成功。这种情况可能会导致部分读取过时数据,因为该节点可能与集群的其余部分隔离。该cluster.no_master_block设置不适用于基于节点的 API(例如,集群统计、节点信息和节点统计 API)。对这些 API 的请求不会被阻止,并且可以在任何可用节点上运行。要使集群完全运行,它必须有一个活动的主节点。
monitor.fs.health.enabled
如果true,节点运行定期 文件系统健康检查。默认为true.monitor.fs.health.refresh_interval
每次文件系统检查的时间间隔 。默认为2m.monitor.fs.health.slow_path_logging_threshold
检查问阿金系统的时间超过该值,则 Elasticsearch 会记录警告日志。默认为5s.
索引生命周期相关的配置
集群方面配置:
indices.lifecycle.history_index_enabled
默认为: true
是否将 生命周期相关的操作记录到ilm-history-*indices.indices.lifecycle.poll_interval
默认:10m
多久检查一次索引生命周期的策略。我们是可以修改索引的生命周期相关的配置的。
索引层面的配置
index.lifecycle.indexing_complete
是否滚动创建索引。
默认为false.index.lifecycle.name
用于管理索引的策略名称。有关 Elasticsearch 如何应用策略更改的信息,请参阅策略更新。index.lifecyle.origination_date
单位是long类型的时间戳
记录首次创建索引的间。该时间会被用来计算索引的年龄。可以不指定,如果不指定,则需要用下边的参数,并且创建的索引名称为指定格式。index.lifecycle.parse_origination_date
是否自动识别首次创建索引的时间。这个时间用来计算索引的年龄。
默认为true,当设置为true的时候,会自动从索引中通过名字识别首次创建索引的时间。前提是索引的名字为指定格式。索引名称必须与模式匹配^.*-{date_format}-\\d+,其中date_formatisyyyy.MM.dd和尾随数字是可选的。翻转的索引通常会匹配完整格式,例如logs-2016.10.31-000002)。如果索引名称与模式不匹配,则索引创建失败。index.lifecycle.step.wait_time_threshold
在 ILM操作期间等待集群解决分配问题的时间 。必须大于1h(1 小时)。默认为12h(12 小时)。请参阅分片分配 收缩。index.lifecycle.rollover_alias
使用生命周期滚动创建索引要更新的索引别名。
更多
生产经验关于参数优化
看完还是觉得不够过瘾,或者说觉得不够实用。可以看看我这篇文章(这是我在长期运维千亿级别生产集群的生产经验,个人觉得比上边的更实用一些✿✿ヽ(°▽°)ノ✿):几千亿级集群管理,近百个实用优化参数,涵盖集群、索引、客户端
生产经验性能优化
ES性能优化最佳实践- 检索性能提升30倍!
向量检索优化
ES 8.x 向量检索性能测试 & 把向量检索性能提升100倍!