标题:基于知识的视觉问答的多模态知识提取与积累
一、问题提出来源:CVPR 2022https://arxiv.org/abs/2203.09138
代码:https://github.com/AndersonStra/MuKEA
一般的基于知识的视觉问答(KB-VQA) 要求具有关联外部知识的能力,以实现开放式跨模态场景理解。
现有的研究主要集中在从结构化知识图中获取相关知识,如ConceptNet和DBpedia,或从非结构化/半结构化知识中获取相关知识,如Wikipedia和Visual Genome。虽然这些知识库通过大规模的人工标注提供了高质量的知识,但一个局限性是,它们从纯文本的知识库中获取相关知识,这些知识库仅包含由一阶谓词或语言描述表示的事实,因此这种知识库很难表示高阶谓词和多模态知识,而这些知识是回答复杂问题所必需的,所以现有的模型无法很好的进行视觉理解。
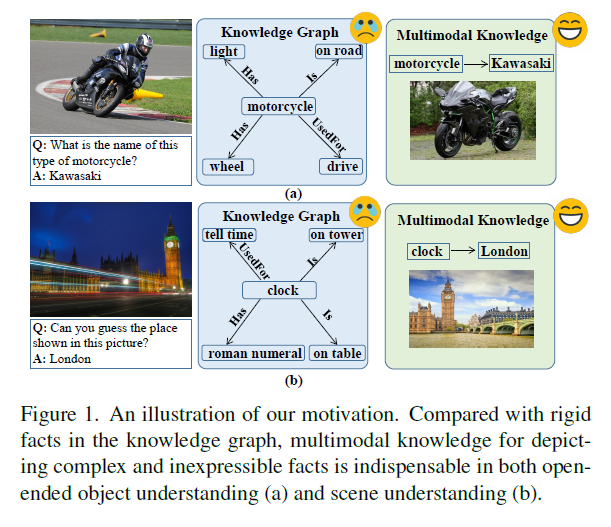
如何为VQA场景构建与视觉相关且可解释的多模态知识的研究较少。
目标:不使用外部文本为主的知识库,通过VQA数据集学习包含着图片以及问题、回答等多模态信息的综合知识表示。
二、主要模型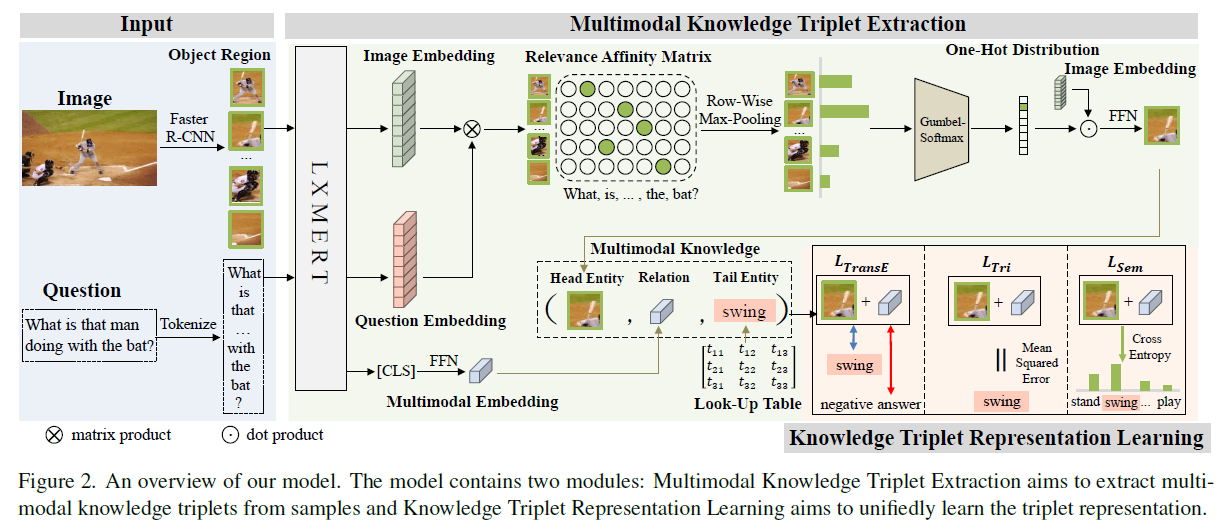
本文提出了一种针对KB-VQA任务的多模态知识提取与积累框架(MuKEA)。核心是独立于已有的知识库,通过对VQA样本的观察,积累关系复杂的多模态知识,并基于自积累的知识进行可解释推理。
做法:
(1)提出了一种用显式三元组表示多模态知识单元的模式。
头部实体:问题所指的视觉对象embedding
尾部实体:事实答案的embedding
关系:图像和问题之间的隐性
(2)提出了三个损失函数,从粗到细学习三元组的表示。
(3)在此基础上,提出了一种基于预训练和微调的学习策略,从域外(VQA 2.0)和域内的VQA样本中逐步积累多模态知识,用于可解释推理。
2.1 多模态知识三元组抽取:(h, r, t):h包含由问题聚焦的图像中的视觉内容,t是给定问题-图像对的答案的表示,r描述了包含多模态信息的h和t之间的隐式关系
图像与问题编码:由于预训练的视觉语言模型对模态内隐式关联和跨模态隐式关联的建模能力较强,故利用预训练的LXMERT模型对问题和图像进行编码,在此基础上进一步提取多模态知识三元组。
步骤:
Step1:针对图像,应用Faster R-CNN抽取图像\(i\)中的一组对象\(O=\left\{o_i\right\}_{i=1}^K\left(K=36\right)\),并通过视觉特征向量\(f_i\)(维度为2048维)和空间特征向量\(b_i\)(维度为4维)来表示每个对象。
Step2:针对问题,使用WordPiece对问题Q进行建模,获得D 个token序列。
Step3:视觉特征\(f_i\)和\(b_i\)输入预训练的LXMERT,得到对象O的视觉embedding,记为\(V\in R^{K\times d_v}\left(d_v=768\right)\);同样的,得到token序列的embedding,记为= 768) \(Q\in R^{D\times d_v}\)。
头部实体提取:图像中的上下文中与问题最相关的部分。
Step1:求出图像中每个对象与问题中每个token的相似度,得到对象-问题相似度矩阵A:
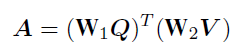
Step2:使用注意力获取到最相关的视觉内容。利用A上的行向最大值来计算每个对象与问题的相关性:
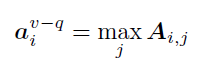
然后利用注意力来根据\(a_i^{v-q}\)选取最相关的对象作为头部实体。此处使用Gumbel-Softmax来获得近似的one-hot类别分布。对象\(o_i\)的注意力权重计算如下:
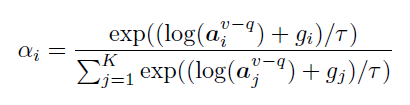
其中,\({g_i}_{i=1}^K\)为独立同分布的标准Gumbel分布的随机变量,τ为温度参数。
最后得到头部实体表示h:
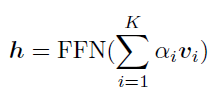
其中,V为对象O的视觉embedding,,FFN表示包含两个全连接层的前馈网络。
【参考:https://www.cnblogs.com/initial-h/p/9468974.html
Softmax倾向于获取到最有可能的类别,损失了概率的信息;
Gumbel-Softmax: 对于n维概率向量π,对π对应的离散随机变量\(\pi_i\)添加Gumbel噪声,再取样:
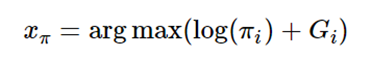
其中,\({g_i}_{i=1}^K\)是独立同分布的标准Gumbel分布的随机变量,标准Gumbel分布的CDF为:
\[F\left(x\right)=e^{-e^{-x}} \]这是Gumbel-Max trick。可以看到由于这中间有一个argmax操作,这是不可导的,所以用softmax函数代替,也就是Gumbel-Softmax Trick。

用Gumbel分布做Re-parameterization使得整个图计算可导,同时样本点最接近真实分布的样本。】
关系抽取:多模态知识图中的关系定义为观察到的实例化对象与回答之间的复杂隐含关系。从[CLS]令牌中提取多模态表示,并送入FFN层以获得关系嵌入,记为r。
尾部实体提取:尾部实体定义为(图像-问题-答案)中的答案。在训练阶段,将ground truth answer设置为尾部实体,学习其表示t。在推理阶段,将KB-VQA任务定义为一个多模态知识图补全问题,预测最优尾部实体作为答案。
2.2 三元组表示学习Triplet TransE Loss:给定一个图像-问题对,设A+和A−表示其集合为正确和不正确的答案。设h和r表示提取的对应头部实体表示和关系表示。希望\(h+r\)与每个t∈A+之间的距离比\(h + r\)与每个 t∈A-之间的距离小一定幅度γ:
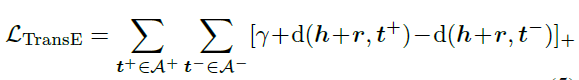
Triplet Consistency Loss:Triplet TransE Loss存在问题:当训练过程中正负对之间的距离小于γ时,模型将停止从三元组学习。为了进一步推动t的embedding学习满足严格拓扑关系,我们采用均方误差(MSE loss)学习正样本:
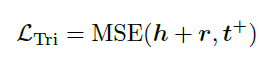
Semantic Consistency Loss:为了缩小尾部节点embedding和头部节点以及关系之间的语义异构差距,使用softmax进行分类,并优化负对数似然损失:
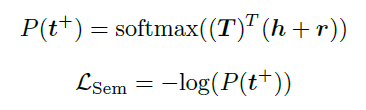
最终的损失函数:
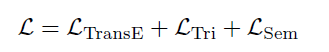
采用两阶段训练策略,逐步积累多模态知识:
(1)在VQA 2.0数据集上进行预训练,积累基本的知识; VQA 2.0中Other类的问题作为事实知识,用于预训练任务。
(2)对下游KB-VQA任务的训练数据进行调优,积累更复杂的特定领域的多模态知识。
2.4预测:把答案预测看作一个多模态知识图补全问题。给出一个图像和一个问题,将它们输入到网络中,得到了头部实体\(h_{inf}\)和关系\(r_{inf}\)的embedding。计算\(h_{inf}+r_{inf}\)与查找表T中每个尾部实体\(t_i\)之间的距离,选取距离最小的尾实体为预测答案:
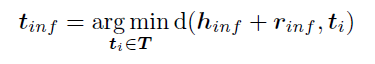
OK-VQA、KRVQA
KRVQA:基于常识的无偏视觉问答数据集,包括知识无关的推理和知识有关的推理,还有基于外部知识的多步推理。
3.2 实验对比:OK-VQA:
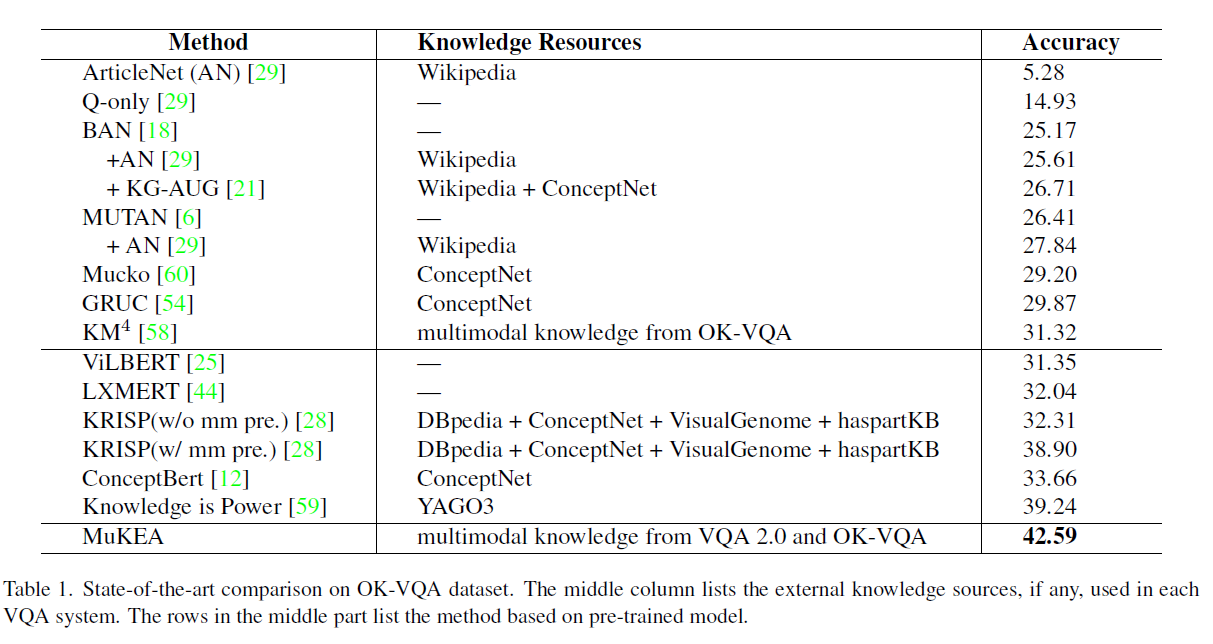
最优
KRVQA:
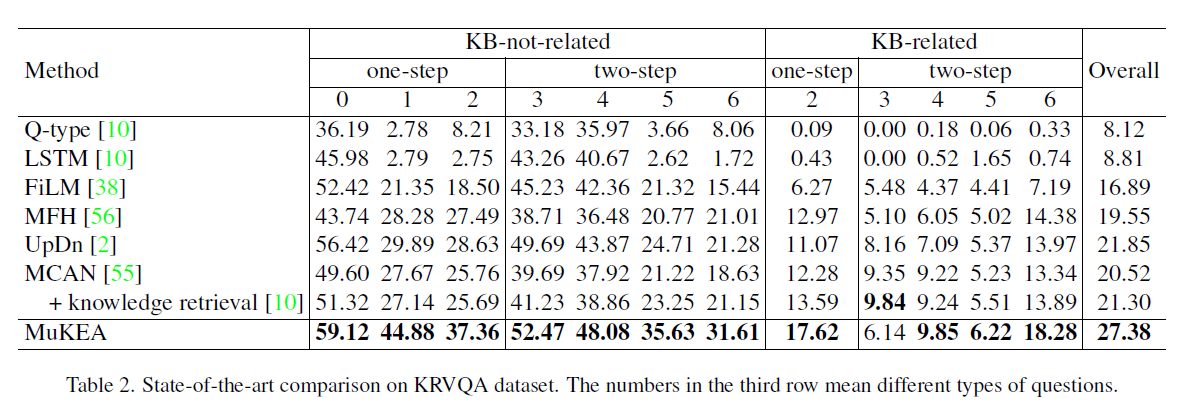
MuKEA在“知识无关”问题上比其他模型准确率有大幅提升,表明即使是传统的视觉问题也需要多模态常识来学习低级视觉内容和高级语义。
在两步推理的第3类问题上,MuKEA不如一些模型,因为这些问题的答案多为关系,而MuKEA的预测的尾部实体多为事实实体。(这也是一种未来的改进方向)
3.3 消融实验: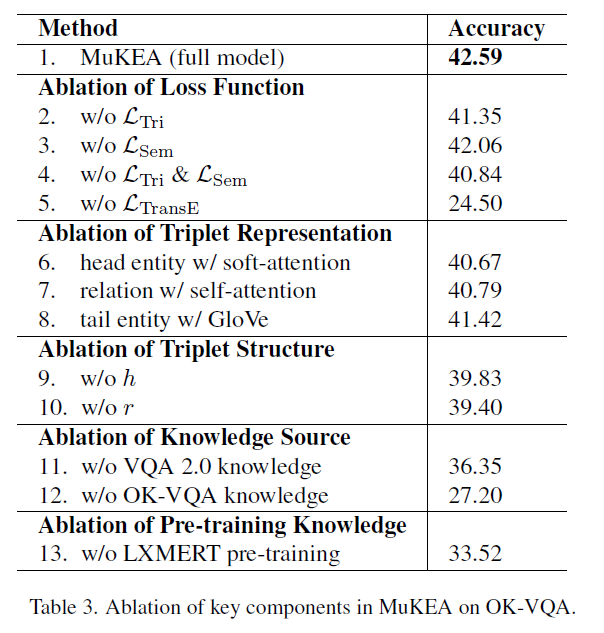
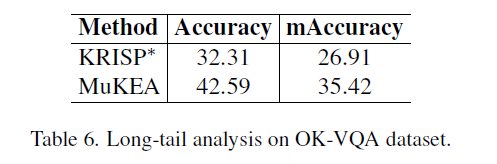
证明多模态知识对长尾知识具有较强的泛化能力。
3.5 模型可解释性:

图1:尼龙 (√) 帆布(×)
图2:科威特航空公司(√) 联合包裹服务(×)
(1)数据集训练场景有限,模型缺乏足够的多模态知识。
(2)未能提取出一些三元组。由于头部实体及其关系是在无监督模式(LXMERT)下提取的,视觉相似的内容会导致注意力的偏差。
五、Tips本文提出了一种新的基于知识的视觉问答框架,该框架注重多模态知识的提取和积累,而不是使用外部知识库。采用预训练和微调策略,逐步积累多模态知识。
后续可以考虑如何将MuKEA学习到的多模态知识与知识库有效结合。