用户代理对应的英文名称为User-Agent,简称UA.其具体内容为一行字符串,用来表征操作系统,浏览器版本等信息,以谷歌浏览器为例,通过快捷键F12的调试模式,可以看到浏览器在发送H
用户代理对应的英文名称为User-Agent, 简称UA. 其具体内容为一行字符串,用来表征操作系统,浏览器版本等信息,以谷歌浏览器为例,通过快捷键F12的调试模式,可以看到浏览器在发送HTTP请求时的头文件,截图如下
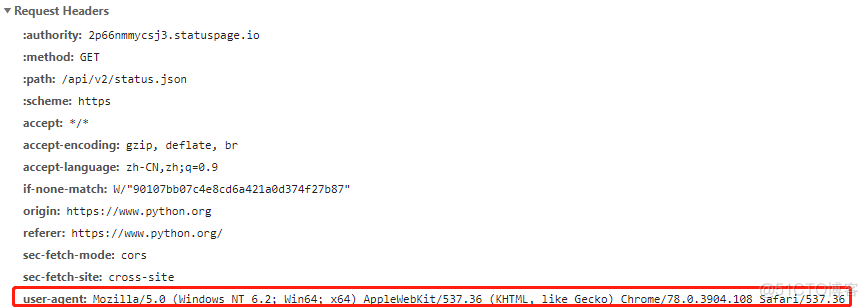
其中,红框表示的部分就是用户代理的信息,服务器就是用户代理的信息来识别浏览器的。换言之,不同的浏览器拥有不同的user-agent信息,通过修改http请求中的user-agent信息,可以将普通的爬虫程序伪装成一个浏览器的请求,从而绕过服务器反爬虫机制中对user-agent的限制。
在urllib模块中,可以在header中指定user-agent的值,实现用户代理,用法如下
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
request = urllib.request.Request('https://www.python.org/', headers = headers)
response = urllib.request.urlopen(request)
response.read().decode('utf-8')
部分网站禁止爬虫程序来获取其资源,如果识别到一个不是浏览器的请求,会进行拦截,比如糗事百科
>>> a = urllib.request.urlopen('https://www.qiushibaike.com/').read().decode('utf-8')Traceback (most recent call last):
File "C:\Program Files (x86)\Python38-32\lib\http\client.py", line 272, in _read_status
raise RemoteDisconnected("Remote end closed connection without"
http.client.RemoteDisconnected: Remote end closed connection without response
当然有些网站的报错信息会不一样,比如同花顺网站
>>> response = urllib.request.urlopen('http://www.10jqka.com.cn/').read().decode('utf-8')Traceback (most recent call last):
File "C:\Program Files (x86)\Python38-32\lib\urllib\request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
但是本质上都是服务器拒绝了我们的请求,当我们能够在浏览器中访问到对应的页面,通过简单的爬取却访问不到时,可以判断,服务器对user-agent进行了限制。
当我们添加了用户代理之后,就可以访问到页面的内容了
>>> headers = {... 'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
... }
>>> request = urllib.request.Request('https://www.qiushibaike.com/', headers = headers)
>>> response = urllib.request.urlopen(request).read().decode('utf-8')
通过在header中添加用户代理,可以突破服务器对于爬虫的第一重封锁,是编写爬虫的第一个基础技巧。不同操作系统,不同浏览器具有不同的user-agent, 大家可以在自己的浏览器中打开对应的网页,然后通过调试工具来查看具体的user-agent信息。
·end·

一个只分享干货的
生信公众号