对样本的分布情况进行研究是最基本的数据分析技能,研究方法可以分为以下两大类
1. 参数估计,根据经验假设数据符合某种特定的分布,然后通过抽样的样本来估计总体对应的参数,比如假设高斯分布,通过样本来估计对应的均值和方差
2. 非参数估计,不同于参数估计,该策略对于总体分布没有任何事先的假设,完全从抽样的样本出来来研究数据分布的特征。核密度估计就是属于该策略,全称为Kernel Density Estimation,缩写为KDE
对于数据分布,最简单的做法就是绘制直方图了,示例如下
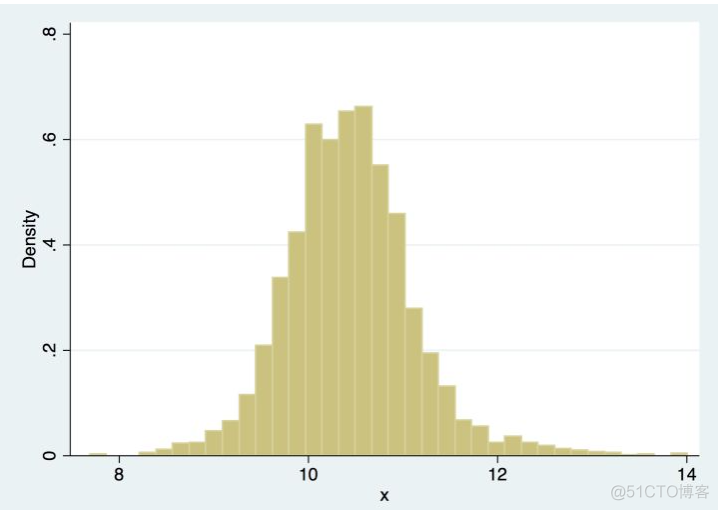
通过直方图上的形态来判断样本分布,但是直方图有着诸多的限制。首先就是直方图非常的离散,不够光滑,仅能反映几个特定区间内的样本分布。其次,该方法对区间大小非常敏感,不同取值会呈现不同的效果,示例如下
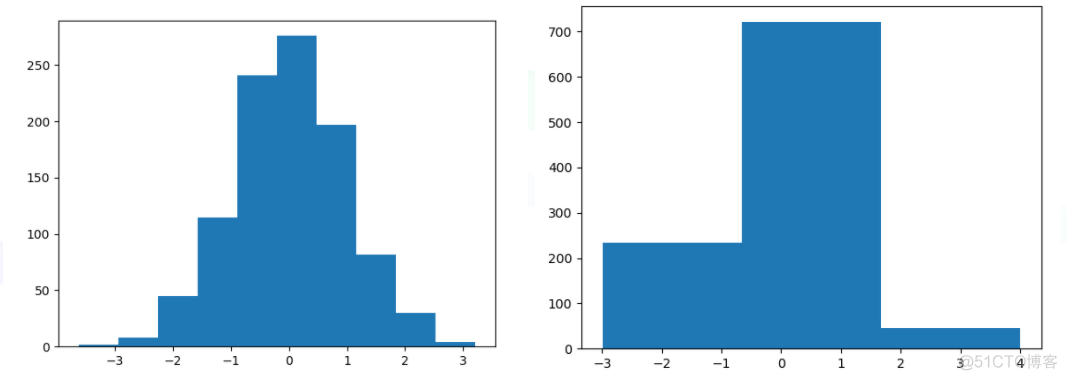
最后直方图的可视化方式也仅仅适用于一维或者二维的数据,对于高维数据,无法适用。
相比直方图,核密度估计通过离散样本点来的线性加和来构建一个连续的概率密度函数,从而得到一个平滑的样本分布,以一维数据为例,核密度估计的公式如下
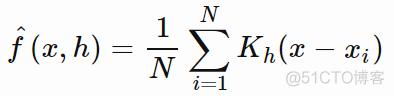
f表示总体的概率密度函数,h是一个超参数,称之为带宽,或者窗口,N表示样本总数,K表示核函数。和SVM中的核函数一样,核函数可以有多种具体形式,以最常用的高斯核函数为例,公式如下
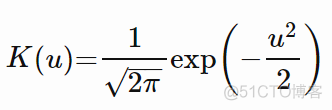
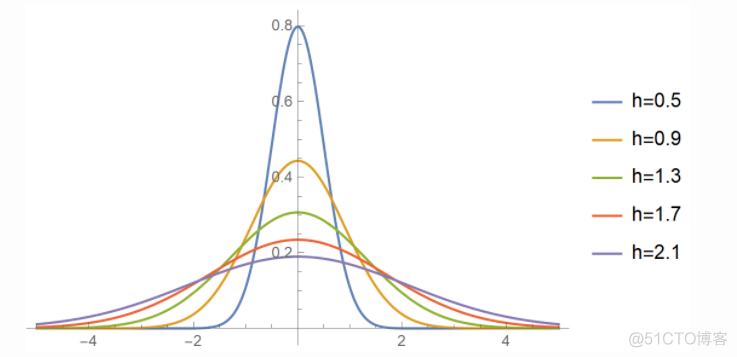
h参数通过影响核函数中自变量的取值来控制每个样本的相对权重,公式如下
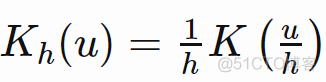
以一个6个样本的一维数据为例,具体取值分别为1,2,3,4,7,9,使用高斯核函数,带宽h设置为1,则KDE对应的概率密度函数如下
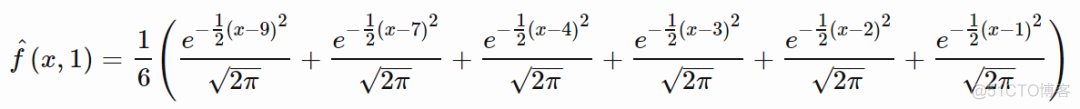
通过图表可以更进一步看到,抽样的6个离散值与总体分布的关系
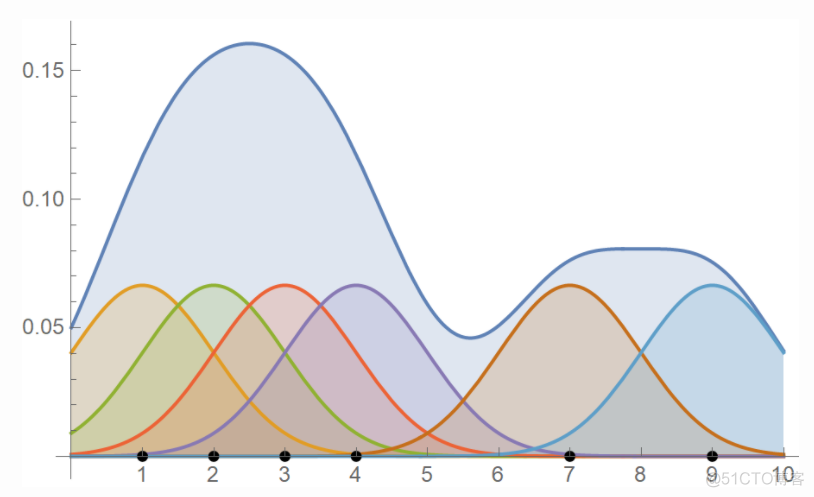
对于KDE方法而言,h参数的选择对结果的影响较大,以高斯核函数为例,不同的h对应的形状如下
带入到概率密度函数中,不同样本对应的系数值就会不一样,所以说h控制了样本的权重。在sickit-learn中, 提供了多种核函数来进行核密度估计,图示如下
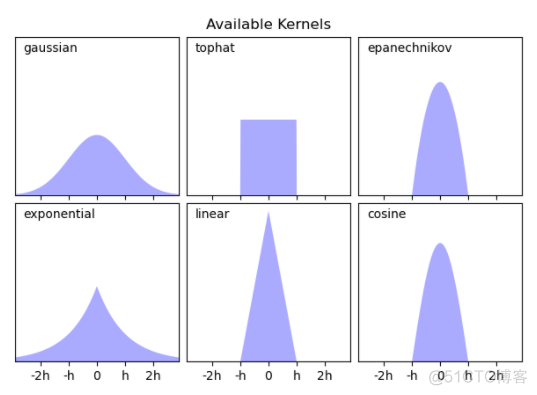
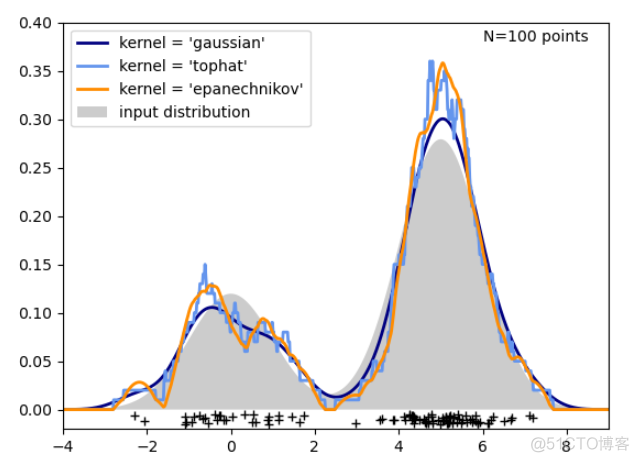
对于不同的核函数而言,虽然会有一定的影响,但是效果没有h参数的影响大,示例如下
以高斯核函数为例,具体用法如下
>>> from sklearn.neighbors import KernelDensity>>> import numpy as np
>>> X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
>>> kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(X)
>>> kde.score_samples(X)
array([-0.41075698, -0.41075698, -0.41076071, -0.41075698, -0.41075698,
-0.41076071])
>>> np.exp(kde.score_samples(X))
array([0.66314807, 0.66314807, 0.6631456 , 0.66314807, 0.66314807,
0.6631456 ])
作为研究样本分布的一种非参数方法,KDE可以得到更加平滑的连续型概率密度分布,而且可以处理高维数据,非常的好用。
·end·

一个只分享干货的
生信公众号