海量数据中找到中位数,内存肯定是无法一次性放下这么多数据的
中位数定义:数字排序之后,位于中间的那个数。比如将 100 亿个数字进行排序,排序之后,位于第 50 亿个位置的那个数就是中位数。
桶排序
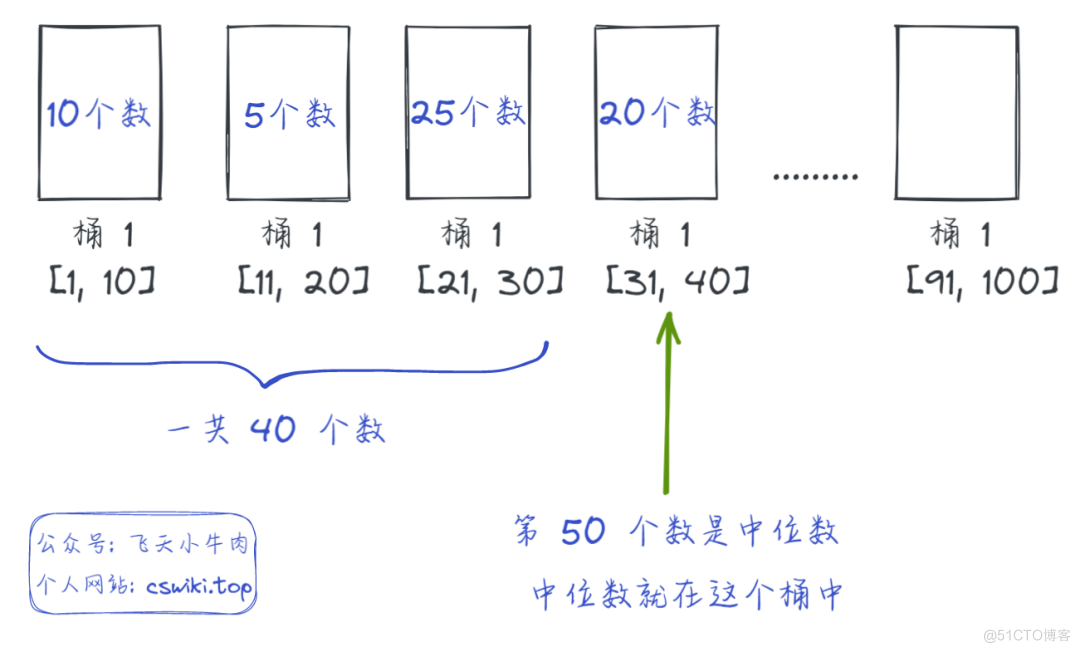
1)创建多个小文件桶,设定每个桶的取值范围,然后把海量数据元素根据数值分配到对应的桶中,并记录桶中元素的个数
2)根据桶中元素的个数,计算出中位数所在的桶(比如 100 亿个数据,第 1 个桶到第 18 个桶一共有 49 亿个数据,第 19 个桶有 2 亿数据,那么中位数一定在第 19 个桶中),然后针对该桶进行排序,就可以求出海量数据中位数的值(如果内存还是不够,可以继续对这个桶进行拆分;或者直接用 BitMap 来排序)
简单用 100 个数据画个图直观理解下:
分治法 + 基于二进制比较
假设这 100 亿数据都是 int 类型,4 字节(32 位)的有符号整数,存在一个超大文件中。
将每个数字用二进制表示,比较二进制的【最高位】 (第 32 位),如果数字的最高位为 0,则将这个数字写入 file_0 文件中;如果最高位为 1,则将该数字写入 file_1文件中。
最高位为符号位,也就是说 file_1 中的数都是负数,而 file_0 中的数都是正数。
通过这样的操作,这 100 亿个数字分成了两个文件,假设 file_0 文件中有 60 亿个数字,而 file_1 文件中有 40 亿个数字。
这样划分后,思考一下:所求的中位数在哪个文件中?
100 亿个数字的中位数是 100 亿个数排序之后的第 50 亿个数,现在 file_0 有 60 亿个正数,file_1 有 40 亿个负数,file_0 中的数都比 file_1 中的数要大,排序之后的第 50 亿个数是中位数,那么这个中位数一定位于 file_0 中,并且是 file_0 文件中所有数字排序之后的第 10 亿个数字。
现在,我们只需要处理 file_0 文件了(不需要再考虑 file_1 文件)。
而对于 file_0 文件,可以同样地采取上面的措施处理:将 file_0 文件依次读一部分到内存,将每个数字用二进制表示,比较二进制的【次高位】(第 31 位),如果数字的次高位为 0,写入 file_0_0 文件中;如果次高位为 1 ,写入 file_0_1 文件中。
现假设 file_0_0 文件中有 30 亿个数字,file_0_1 中也有 30 亿个数字,则中位数就是:file_0_1 文件中的数字从小到大排序之后的第 10 亿个数字。
抛弃 file_0_0 文件,继续对 file_0_1 文件 根据【次次高位】(第 30 位) 划分,如此反复下去