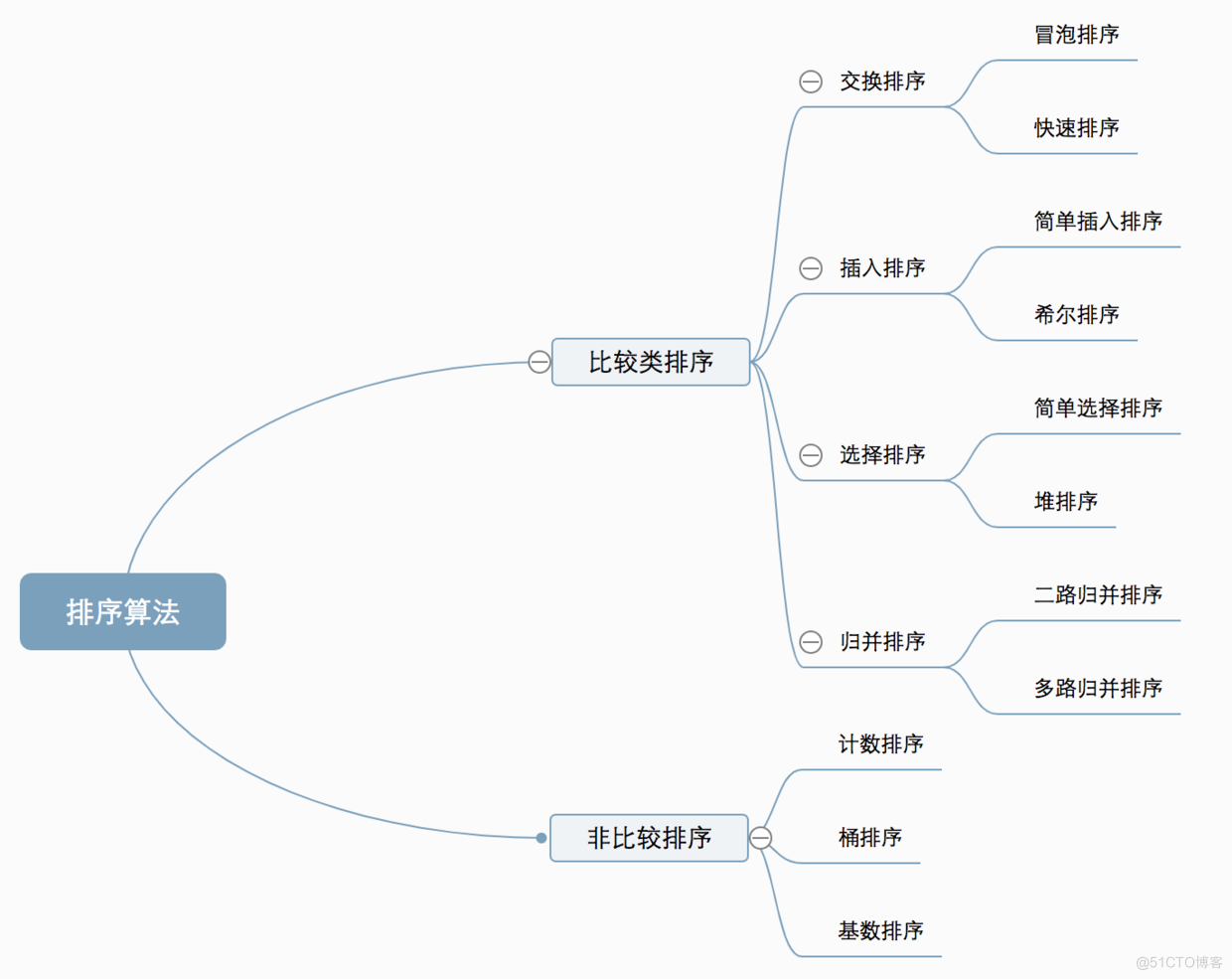
一、算法概述
1.1 算法分类
十种常见排序算法可以分为两大类:
-
比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
-
非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此也称为线性时间非比较类排序。
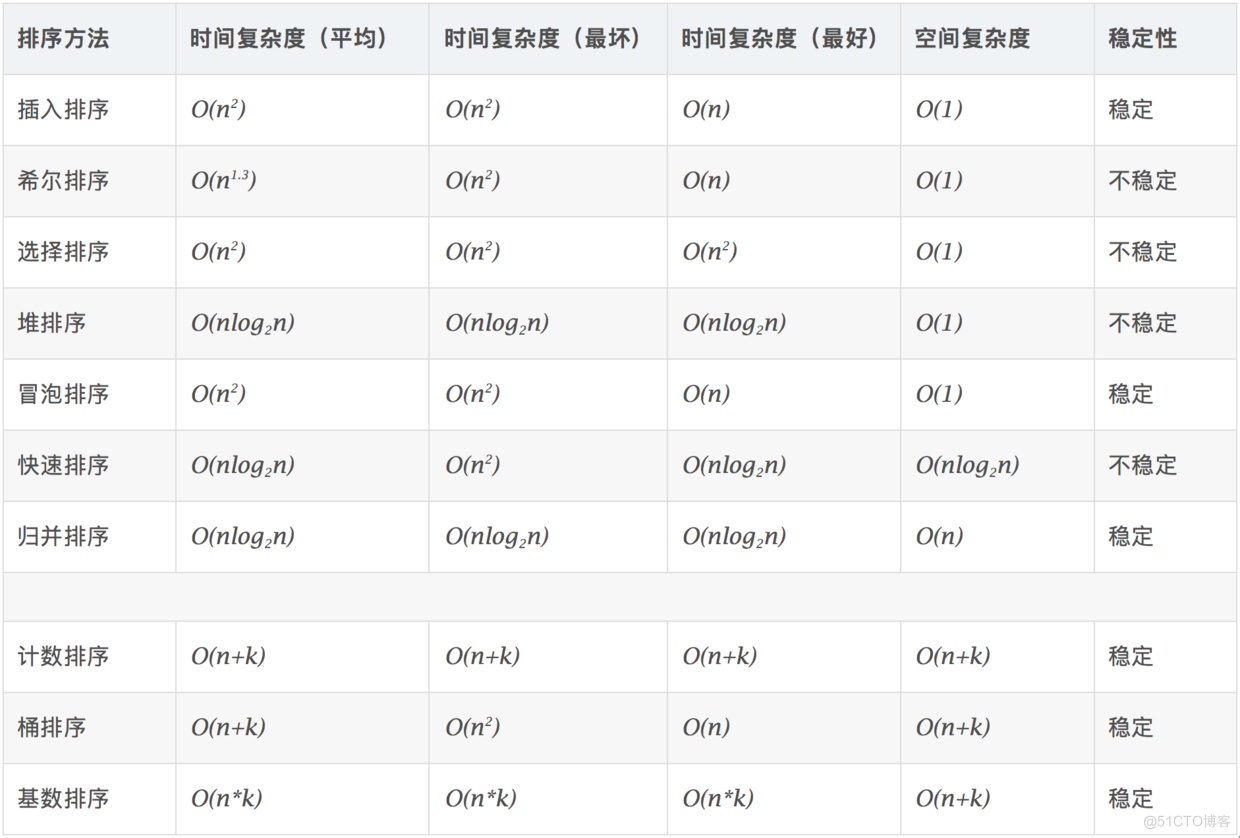
1.2 算法复杂度
1.3 相关概念
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
二、堆排序(Heap Sort)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆分为"最大堆"和"最小堆"。最大堆通常被用来进行"升序"排序,而最小堆通常被用来进行"降序"排序。
鉴于最大堆和最小堆是对称关系,理解其中一种即可。本文将对最大堆实现的升序排序进行详细说明。
2.1 算法描述
-
将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
-
将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
-
由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
最大堆进行升序排序的基本思想:
- ① 初始化堆:将数列a[1...n]构造成最大堆。
- ② 交换数据:将a[1]和a[n]交换,使a[n]是a[1...n]中的最大值;然后将a[1...n-1]重新调整为最大堆。 接着,将a[1]和a[n-1]交换,使a[n-1]是a[1...n-1]中的最大值;然后将a[1...n-2]重新调整为最大值。 依次类推,直到整个数列都是有序的。
下面,通过图文来解析堆排序的实现过程。注意实现中用到了"数组实现的二叉堆的性质"。 在第一个元素的索引为 0 的情形中: 性质一:索引为i的左孩子的索引是 (2i+1); 性质二:索引为i的左孩子的索引是 (2i+2); 性质三:索引为i的父结点的索引是 floor((i-1)/2);

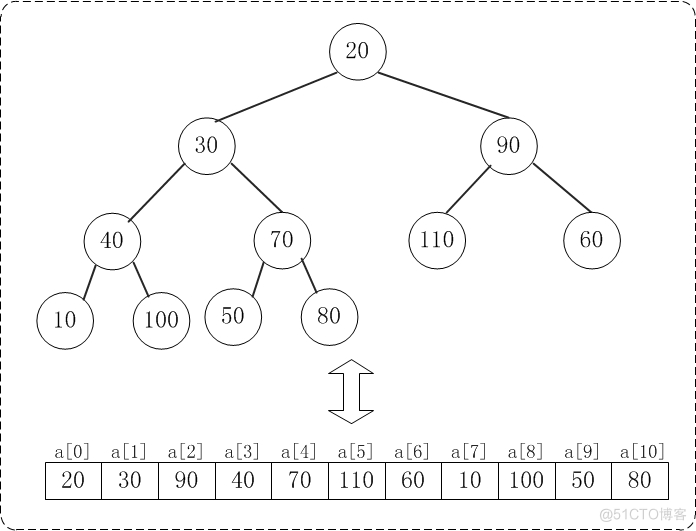
例如,对于最大堆{110,100,90,40,80,20,60,10,30,50,70}而言:索引为0的左孩子的所有是1;索引为0的右孩子是2;索引为8的父节点是3。
2.2 动图演示

2.3 堆排序图文说明
堆排序代码
/** * @Author: huangyibo * @Date: 2022/2/19 0:42 * @Description: 堆排序:原地排序, * 1、先将待排序数组整理成最大堆的形状 * 2、然后将堆的最开始索引的值即最大值和最后面的索引值交换,不断循完成排序 * 3、每交换一轮后,将0索引元素和其左右孩子节点元素进行比较,如果比左右孩子小,则交换位置,不断循环 */ public class HeapSort2 { public static <E extends Comparable<E>> void heapSort(E[] arr){ //如果arr元素个数小于等于1,直接返回 if(arr.length <= 1){ return; } //从最后一个叶子节点的父节点开始进行siftDown操作,不断循环 //(arr.length - 1) / 2 最后一个叶子节点的父节点的索引 //for循环完成,则将数组整理成堆的形状 for(int i = (arr.length - 1) / 2; i >= 0; i --){ siftDown(arr, i, arr.length); } //进行排序操作,将堆的最开始索引的值即最大值和最后面的索引值交换,不断循完成排序 for (int i = arr.length - 1; i >= 0; i--) { //将堆的最开始索引的值即最大值和最后面的索引值交换 swap(arr,0, i); //将0索引元素比左右孩子节点元素小,则交换位置,不断循环 //由于数组最末尾的值已经排好序,索引排好序的元素不包含在内 siftDown(arr, 0, i); } } /** * 对arr[0, n] 所形成的最大堆中,索引k的元素,执行siftDown操作 * k索引元素比左右孩子节点元素小,则交换位置,不断循环 * @param arr * @param k * @param n * @param <E> */ private static <E extends Comparable<E>> void siftDown(E[] arr, int k, int n){ //(k * 2 + 1) 完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引 while ((k * 2 + 1) < n){ //获取k索引的左孩子的索引 int j = k * 2 + 1; //j + 1 < data.getSize() if(j + 1 < n && //如果右孩子比左孩子大 arr[j + 1].compareTo(arr[j]) > 0){ //k * 2 + 2 完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引 //最大孩子的索引赋值给j j = k * 2 + 2; } //此时data[j]是leftChild和rightChild中的最大值 if(arr[k].compareTo(arr[j]) >= 0){ //如果父亲节点大于等于左右孩子节点,跳出循环 break; } //如果父亲节点小于左右孩子节点(中的最大值),交换索引的值 swap(arr, k, j); //交换完成之后,将j赋值给K,重新进入循环 k = j; } } /** * 数组索引元素交换 * @param arr * @param i * @param j * @param <E> */ private static <E> void swap(E[] arr, int i, int j){ if(i < 0 || i >= arr.length || j < 0 || j >= arr.length){ throw new IllegalArgumentException("Index is illegal."); } E temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } }下面是数组a对应的初始化结构
2.3.1 初始化堆
在堆排序算法中,首先要将待排序的数组转化成二叉堆。 下面演示将数组{20,30,90,40,70,110,60,10,100,50,80}转换为最大堆{110,100,90,40,80,20,60,10,30,50,70}的步骤。
2.3.1.1 i=11/2-1,即i=4
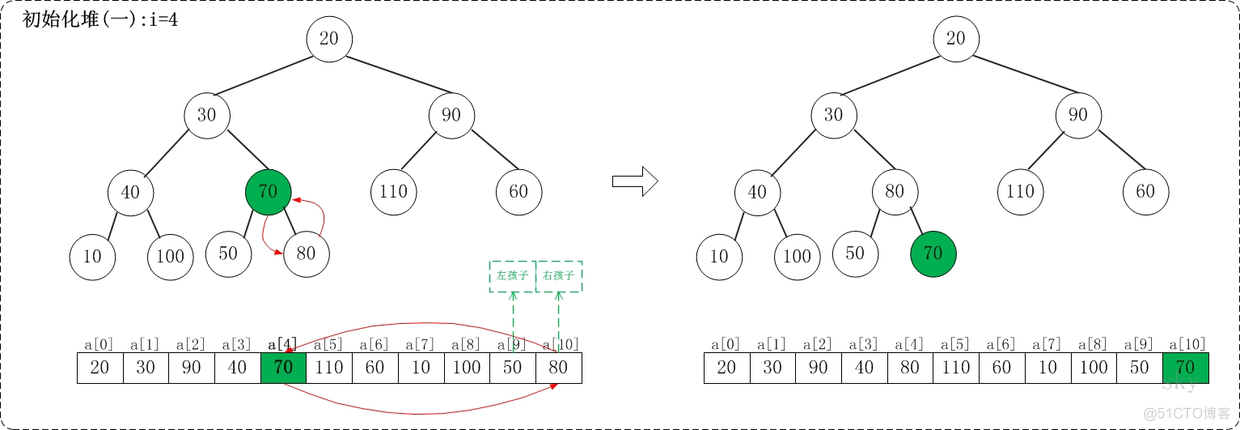
上面是siftDown(a, 4, 9)调整过程。siftDown(a, 4, 9)的作用是将a[4...9]进行下调;a[4]的左孩子是a[9],右孩子是a[10]。调整时,选择左右孩子中较大的一个(即a[10])和a[4]交换。
2.3.1.2 i=3
上面是siftDown(a, 3, 9)调整过程。siftDown(a, 3, 9)的作用是将a[3...9]进行下调;a[3]的左孩子是a[7],右孩子是a[8]。调整时,选择左右孩子中较大的一个(即a[8])和a[4]交换。
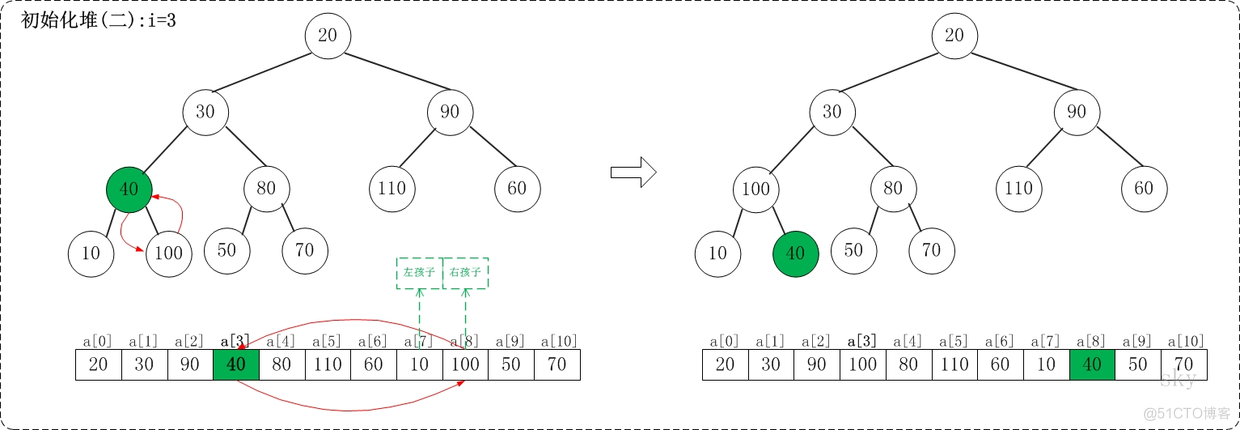
2.3.1.3 i=2
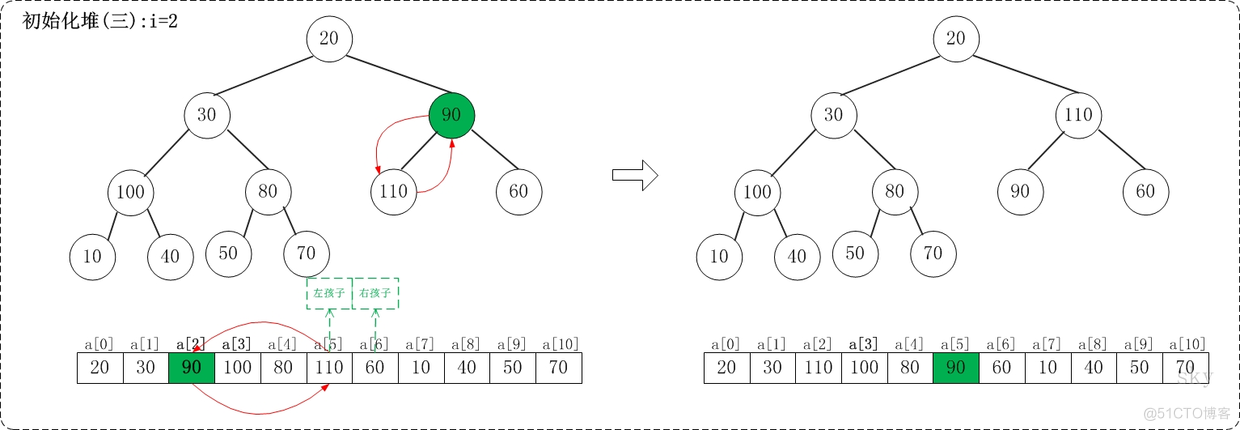
上面是siftDown(a, 2, 9)调整过程。siftDown(a, 2, 9)的作用是将a[2...9]进行下调;a[2]的左孩子是a[5],右孩子是a[6]。调整时,选择左右孩子中较大的一个(即a[5])和a[2]交换。
2.3.1.4 i=1

上面是siftDown(a, 1, 9)调整过程。siftDown(a, 1, 9)的作用是将a[1...9]进行下调;a[1]的左孩子是a[3],右孩子是a[4]。调整时,选择左右孩子中较大的一个(即a[3])和a[1]交换。交换之后,a[3]为30,它比它的右孩子a[8]要大,接着,再将它们交换。
2.3.1.5 i=0
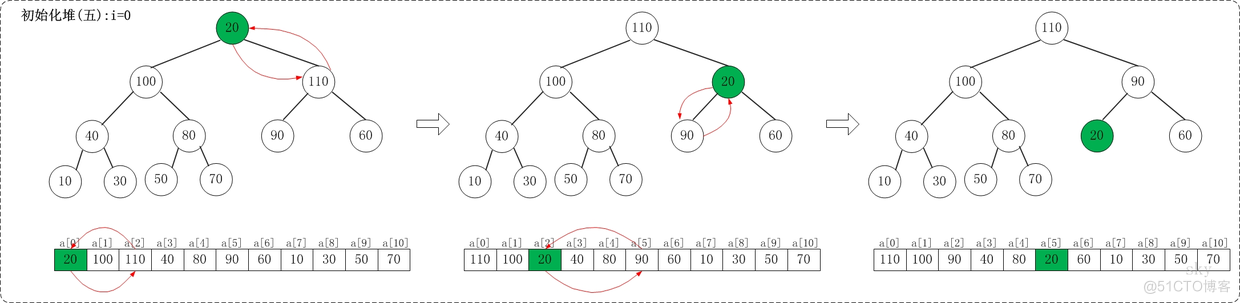
上面是siftDown(a, 0, 9)调整过程。siftDown(a, 0, 9)的作用是将a[0...9]进行下调;a[0]的左孩子是a[1],右孩子是a[2]。调整时,选择左右孩子中较大的一个(即a[2])和a[0]交换。交换之后,a[2]为20,它比它的左右孩子要大,选择较大的孩子(即左孩子)和a[2]交换。
调整完毕,就得到了最大堆。此时,数组{20,30,90,40,70,110,60,10,100,50,80}也就变成了{110,100,90,40,80,20,60,10,30,50,70}。
2.3.2 第2部分 交换数据
在将数组转换成最大堆之后,接着要进行交换数据,从而使数组成为一个真正的有序数组。
交换数据部分相对比较简单,下面仅仅给出将最大值放在数组末尾的示意图。

上面是当n=10时,交换数据的示意图。 当n=10时,首先交换a[0]和a[10],使得a[10]是a[0...10]之间的最大值;然后,调整a[0...9]使它称为最大堆。交换之后:a[10]是有序的! 当n=9时, 首先交换a[0]和a[9],使得a[9]是a[0...9]之间的最大值;然后,调整a[0...8]使它称为最大堆。交换之后:a[9...10]是有序的! ... 依此类推,直到a[0...10]是有序的。
2.4 堆排序的时间复杂度和稳定性
2.4.1 堆排序时间复杂度
堆排序的时间复杂度是O(NlogN)。 假设被排序的数列中有N个数。遍历一趟的时间复杂度是O(N),需要遍历多少次呢? 堆排序是采用的二叉堆进行排序的,二叉堆就是一棵二叉树,它需要遍历的次数就是二叉树的深度,而根据完全二叉树的定义,它的深度至少是lg(N+1)。最多是多少呢?由于二叉堆是完全二叉树,因此,它的深度最多也不会超过lg(2N)。因此,遍历一趟的时间复杂度是O(N),而遍历次数介于lg(N+1)和lg(2N)之间;因此得出它的时间复杂度是O(NlogN)。
2.4.2 堆排序稳定性
堆排序是不稳定的算法,它不满足稳定算法的定义。它在交换数据的时候,是比较父结点和子节点之间的数据,所以,即便是存在两个数值相等的兄弟节点,它们的相对顺序在排序也可能发生变化。 算法稳定性 -- 假设在数列中存在a[i]=a[j],若在排序之前,a[i]在a[j]前面;并且排序之后,a[i]仍然在a[j]前面。则这个排序算法是稳定的!
2.5 堆排序实现——原地排序
/** * @Author: huangyibo * @Date: 2022/2/19 0:42 * @Description: 堆排序:原地排序 * 1、先将待排序数组整理成最大堆的形状 * 2、然后将堆的最开始索引的值即最大值和最后面的索引值交换,不断循完成排序 * 3、每交换一轮后,将0索引元素和其左右孩子节点元素进行比较,如果比左右孩子小,则交换位置,不断循环 */ public class HeapSort2 { public static <E extends Comparable<E>> void heapSort(E[] arr){ //如果arr元素个数小于等于1,直接返回 if(arr.length <= 1){ return; } //从最后一个叶子节点的父节点开始进行siftDown操作,不断循环 //(arr.length - 1) / 2 最后一个叶子节点的父节点的索引 //for循环完成,则将数组整理成堆的形状 for(int i = (arr.length - 1) / 2; i >= 0; i --){ siftDown(arr, i, arr.length); } //进行排序操作,将堆的最开始索引的值即最大值和最后面的索引值交换,不断循完成排序 for (int i = arr.length - 1; i >= 0; i--) { //将堆的最开始索引的值即最大值和最后面的索引值交换 swap(arr,0, i); //将0索引元素比左右孩子节点元素小,则交换位置,不断循环 //由于数组最末尾的值已经排好序,索引排好序的元素不包含在内 siftDown(arr, 0, i); } } /** * 对arr[0, n] 所形成的最大堆中,索引k的元素,执行siftDown操作 * k索引元素比左右孩子节点元素小,则交换位置,不断循环 * @param arr * @param k * @param n * @param <E> */ private static <E extends Comparable<E>> void siftDown(E[] arr, int k, int n){ //(k * 2 + 1) 完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引 while ((k * 2 + 1) < n){ //获取k索引的左孩子的索引 int j = k * 2 + 1; //j + 1 < data.getSize() if(j + 1 < n && //如果右孩子比左孩子大 arr[j + 1].compareTo(arr[j]) > 0){ //k * 2 + 2 完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引 //最大孩子的索引赋值给j j = k * 2 + 2; } //此时data[j]是leftChild和rightChild中的最大值 if(arr[k].compareTo(arr[j]) >= 0){ //如果父亲节点大于等于左右孩子节点,跳出循环 break; } //如果父亲节点小于左右孩子节点(中的最大值),交换索引的值 swap(arr, k, j); //交换完成之后,将j赋值给K,重新进入循环 k = j; } } /** * 数组索引元素交换 * @param arr * @param i * @param j * @param <E> */ private static <E> void swap(E[] arr, int i, int j){ if(i < 0 || i >= arr.length || j < 0 || j >= arr.length){ throw new IllegalArgumentException("Index is illegal."); } E temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } }2.6 堆排序实现——非原地排序
- 该实现需要借助于最大堆(MaxHeap)数据结构
2.6.1 动态数组底层实现
public class Array<E> { private E[] data; private int size; public Array(){ this(10); } public Array(int capacity){ this.data = (E[]) new Object[capacity]; this.size = 0; } public Array(E[] arr){ this.data = (E[]) new Object[arr.length]; for (int i = 0; i < arr.length; i++) { data[i] = arr[i]; } this.size = arr.length; } /** * 获取数组中元素个数 * @return */ public int getSize(){ return size; } /** * 获取数组容量 * @return */ public int getCapacity(){ return data.length; } /** * 返回数组是否为空 * @return */ public boolean isEmpty(){ return size == 0; } /** * 数组尾部新增元素 * @param e */ public void addLast(E e){ add(size, e); } /** * 数组头部新增元素 * @param e */ public void addFirst(E e){ add(0, e); } /** * 在指定位置插入元素 * @param index * @param e */ public void add(int index, E e){ if(index < 0 || index > size){ throw new IllegalArgumentException("AddLast failed. require index >=0 and index <= size"); } if(size == data.length){ //扩容 resize(2 * data.length); } for(int i = size - 1; i >= index; i --){ data[i + 1] = data[i]; } data[index] = e; size ++; } /** * 数组扩容 * @param newCapacity */ private void resize(int newCapacity){ E[] newData = (E[])new Object[newCapacity]; for (int i = 0; i < size; i++) { newData[i] = data[i]; } data = newData; } /** * 获取指定索引位置的值 * @param index * @return */ public E get(int index){ if(index < 0 || index >= size){ throw new IllegalArgumentException("Get failed. index is illegal."); } return data[index]; } /** * 替换指定索引位置的值 * @param index * @param e */ public void set(int index, E e){ if(index < 0 || index >= size){ throw new IllegalArgumentException("Set failed. index is illegal."); } data[index] = e; } /** * 数组是否包含元素e * @param e * @return */ public boolean contains(E e){ for (int i = 0; i < size; i++) { if(data[i].equals(e)){ return true; } } return false; } /** * 查找数组中元素e所在的索引,不存在元素e,返回-1 * @param e * @return */ public int find(E e){ for (int i = 0; i < size; i++) { if(data[i].equals(e)){ return i; } } return -1; } /** * 删除数组中index位置的元素, 并返回删除的元素 * @param index * @return */ public E remove(int index){ if(index < 0 || index >= size){ throw new IllegalArgumentException("Remove failed. index is illegal."); } E ret = data[index]; for (int i = index; i < size - 1; i++) { data[i] = data[i + 1]; } size --; data[size] = null; if(size == data.length / 4 && data.length / 2 != 0){ //当数组长度缩小为原数组的4分之一的时候才进行数组的缩容, //缩小为原数组的2分之一,预留空间,防止有数据添加导致扩容浪费性能 resize(data.length / 2); } return ret; } /** * 删除数组中第一个元素 * @return */ public E removeFirst(){ return remove(0); } /** * 删除数组中最后一个元素 * @return */ public E removeLast(){ return remove(size - 1); } /** * 从数组中删除元素e * @param e */ public void removeElement(E e){ int index = find(e); if(index != -1){ remove(index); } } /** * 数组索引元素交换 * @param i * @param j */ public void swap(int i, int j){ if(i < 0 || i >= size || j < 0 || j >= size){ throw new IllegalArgumentException("Index is illegal."); } E temp = data[i]; data[i] = data[j]; data[j] = temp; } @Override public String toString(){ StringBuilder sb = new StringBuilder(); sb.append(String.format("Array: size = %d, capacity = %d\n",size,data.length)); sb.append("["); for (int i = 0; i < size; i++) { sb.append(data[i]); if(i != size - 1){ sb.append(", "); } } sb.append("]"); return sb.toString(); } }2.6.2 基于动态数组底层实现的最大堆实现
/** * @Author: huangyibo * @Date: 2022/2/17 22:54 * @Description: 最大堆 完全二叉树,父亲节点大于等于孩子节点,采用数组表示 */ public class MaxHeap<E extends Comparable<E>> { //这里使用数组作为底层实现 private Array<E> data; public MaxHeap(){ data = new Array<>(); } public MaxHeap(int capacity){ data = new Array<>(capacity); } /** * 将任意数组整理成堆的形状 * @param arr */ public MaxHeap(E[] arr){ data = new Array<>(arr); //从最后一个叶子节点的父节点开始进行siftDown操作,不断循环 for(int i = parent(arr.length - 1); i >= 0; i --){ siftDown(i); } } /** * 返回堆中的元素个数 * @return */ public int getSize(){ return data.getSize(); } /** *堆是否为空 * @return */ public boolean isEmpty(){ return data.isEmpty(); } /** * 返回完全二叉树的数组表示中,一个索引所表示的元素的父亲节点的索引 * @param index * @return */ private int parent(int index){ if(index == 0){ throw new IllegalArgumentException("index-0 doesn't have parent."); } return (index - 1) / 2; } /** * 返回完全二叉树的数组表示中,一个索引所表示的元素的左孩子节点的索引 * @return */ private int leftChild(int index){ return index * 2 + 1; } /** * 返回完全二叉树的数组表示中,一个索引所表示的元素的右孩子节点的索引 * @param index * @return */ private int rightChild(int index){ return index * 2 + 2; } /** * 向堆中添加元素 * @param e */ public void add(E e){ data.addLast(e); //当前元素在数组中的索引为 data.getSize() - 1 //比较当前元素和其父亲节点的元素,大于父亲节点元素则交换位置 siftUp(data.getSize() - 1); } /** * k索引元素比父节点元素大,则交换位置,不断循环 * @param k */ private void siftUp(int k){ //k > 0 并且k索引元素比父节点元素大,则交换位置,不断循环 while (k > 0 && data.get(parent(k)).compareTo(data.get(k)) < 0){ data.swap(parent(k), k); k = parent(k); } } /** * 查看堆中最大元素 * @return */ public E findMax(){ if(data.getSize() == 0){ throw new IllegalArgumentException("Can not findMax when heap is empty."); } return data.get(0); } /** * 取出堆中最大元素 * @return */ public E extractMax(){ //获取堆中最大元素 E ret = findMax(); //堆中最开始的元素和最后元素交换位置 data.swap(0,data.getSize() - 1); //删除堆中最后一个元素 data.removeLast(); //0索引元素比左右孩子节点元素小,则交换位置,不断循环 siftDown(0); return ret; } /** * k索引元素比其左右孩子节点元素小,则交换位置,不断循环 * @param k */ private void siftDown(int k){ while (leftChild(k) < data.getSize()){ //获取k索引的左孩子的索引 int j = leftChild(k); //j + 1 < data.getSize() if(j + 1 < data.getSize() && //如果右孩子比左孩子大 data.get(j + 1).compareTo(data.get(j)) > 0){ //最大孩子的索引赋值给j j = rightChild(k); } //此时data[j]是leftChild和rightChild中的最大值 if(data.get(k).compareTo(data.get(j)) >= 0){ //如果父亲节点大于等于左右孩子节点,跳出循环 break; } //如果父亲节点小于左右孩子节点(中的最大值),交换索引的值 data.swap(k, j); //交换完成之后,将j赋值给K,重新进入循环 k = j; } } /** * 取出堆中最大元素,并且替换成元素e * @param e * @return */ public E replace(E e){ //获取堆中的最大值 E ret = findMax(); //用新添加的元素替换最大的元素 data.set(0, e); //0索引元素比左右孩子节点元素小,则交换位置,不断循环 siftDown(0); return ret; } }2.6.3 堆排序:非原地排序
/** * @Author: huangyibo * @Date: 2022/2/18 21:42 * @Description: 堆排序:非原地排序 */ public class HeapSort { public static <E extends Comparable<E>> void heapSort(E[] arr){ //建立一个最大堆 MaxHeap<E> maxHeap = new MaxHeap<>(); for (E e : arr) { //将数组元素放入最大堆 maxHeap.add(e); } //循环遍历,取出最大堆的最大元素倒序放入数组中,完成堆排序 for (int i = arr.length - 1; i >= 0; i--) { arr[i] = maxHeap.extractMax(); } } }参考: https://www.cnblogs.com/onepixel/articles/7674659.html
https://www.cnblogs.com/skywang12345/p/3602162.html