每个Elasticsearch节点内部都维护着多个线程池,如index、search、get、bulk等,用户可以修改线程池的类型和大小,线程池默认大小跟CPU逻辑一致。
一、查看当前线程组状态
curl -XGET 'http://localhost:9200/_nodes/stats?pretty' "thread_pool": { "bulk": { "threads": 32, "queue": 0, "active": 0, "rejected": 0, "largest": 32, "completed": 659997 }, "index": { "threads": 2, "queue": 0, "active": 0, "rejected": 0, "largest": 2, "completed": 2 } }上面截取了部分线程池的配置,其中,最需要关注的是rejected。当某个线程池active==threads时,表示所有线程都在忙,那么后续新的请求就会进入queue中,即queue>0,一旦queue大小超出限制,如bulk的queue默认50,那么elasticsearch进程将拒绝请求(碰到bulk HTTP状态码429),相应的拒绝次数就会累加到rejected中。
当我将数据写入集群时,收到类似于以下内容的错误消息:
error":"elastic: Error 429 (Too Many Requests): rejected execution of org.elasticsearch.transport.TransportService$7@b25fff4 on EsThreadPoolExecutor[bulk, queue capacity = 50, org.elasticsearch.common.util.concurrent.EsThreadPoolExecutor@768d4a66[Running, pool size = 4, active threads = 4, queued tasks = 50, completed tasks = 820898]] [type=es_rejected_execution_exception]"简短描述
当 Elasticsearch 集群收到大量请求且无法再接收任何请求时,通常会发生“es_rejected_execution_exception”异常。每个节点都有一个线程池队列,可以容纳 50 到 200 个请求,具体取决于您使用的 Elasticsearch 版本。队列已满时,将拒绝新请求。
解决方法
**注意:**在大多数ES 版本中,无法增加队列大小。该队列存在的原因是它将请求限制为可管理的数量。有关更多信息,请参阅 Elasticsearch 文档中的“线程池”部分。
通过下列某一种方法解决“es_rejected_execution_exception”错误:
- 添加更多节点:每个节点都有一个批量队列,因此添加更多节点可以为您提供更多的排队容量。要添加节点,请参阅配置 Amazon ES 域(控制台)。
- 切换到更大的实例类型:对于批量请求,每个节点上线程池中的线程数等于可用处理器的数量。切换到具有更多虚拟 CPU (vCPU) 的实例,以获取更多线程来处理批量请求。有关更多信息,请参阅选择实例类型和测试。
- 优化批量请求大小:不是发送许多小批量请求,而是发送一些大批量请求。
- 改善索引性能:当文档编制索引速度更快时,批量队列不太可能达到容量。有关性能优化的更多信息,请参阅 Elasticsearch 文档中的索引性能提示。
实际使用的解决方法是:
- 1、记录失败的请求并重发
- 2、减少并发写的进程个数,同时加大每次bulk请求的size
二、核心线程池
- index:此线程池用于索引和删除操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为300。
- search:此线程池用于搜索和计数请求。它的类型默认为fixed,size默认为可用处理器的数量乘以3,队列的size默认为1000。
- suggest:此线程池用于建议器请求。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000。
- get:此线程池用于实时的GET请求。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000。
- bulk:此线程池用于批量操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为50。
- percolate:此线程池用于预匹配器操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000。
三、线程池类型
- 1、Scaling 类型 可变数量的线程,Elasticsearch会根据工作负载自动调节线程大小(值介于:core 到 max 之间)。
Scaling 类型线程使用示例如下:
thread_pool: warmer: core: 1 max: 8- 2、fixed 类型 有着固定大小的线程池,大小由size属性指定,允许你指定一个队列(使用queue_size属性指定)用来保存请求,直到有一个空闲的线程来执行请求。如果Elasticsearch无法把请求放到队列中(队列满了),该请求将被拒绝。
Fixed 类型线程使用示例如下:
thread_pool: write: size: 30 queue_size: 1000- 3、fixed_autoqueue_size 线程
- 固定数量的线程,队列大小会动态变化以保持目标响应时间。
- 该功能 8.0+ 版本会废弃,这里也不着重讲解。
fixed_autoqueue_size 类型线程使用示例如下: 强调了队列大小可变。
thread_pool: search: size: 30 queue_size: 500 min_queue_size: 10 max_queue_size: 1000 auto_queue_frame_size: 2000 target_response_time: 1s四、修改线程池配置
- 1、elasticsearch.yml
- 2、Rest API
五、bulk异常排查
使用es bulk api时报错如下 EsRejectedExcutionException[rejected execution(queue capacity 50) on.......]
这个错误明显是默认大小为50的队列(queue)处理不过来了,解决方法是增大bulk队列的长度
elasticsearch.yml
threadpool.bulk.queue_size: 1000六、线程池使用举例
若要查看哪些线程 CPU 利用率高或花费的时间最长,可以使用以下查询。
GET /_nodes/hot_threads该 API 有助于排查性能问题。
七、线程池和队列认知
认知 1:必要时设置:processors
值得注意的是,线程池是根据 Elasticsearch 在基础硬件上检测到的线程数(number of processors)设置的。
如果检测失败,则应在 elasticsearch.yml 中显式设置硬件中可用的线程数。
特别是在一台宿主机配置多个 Elasticsearch 节点实例的情况下,若要修改其中一个节点线程池或队列大小,则要考虑配置 processors 参数。
elasticsearch.yml 中设置如下所示:
processors: 4PS:Linux 查看线程数方法:
grep 'processor' /proc/cpuinfo | sort -u | wc -l认知 2:线程池关联队列设置
大多数线程池还具有与之关联的队列,以使 Elasticsearch 可以将请求存储在内存中,同时等待资源变得可用来处理请求。
但是,队列通常具有有限的大小,如果超过该大小,Elasticsearch将拒绝该请求。
认知 3:很糟糕做法——盲目修改队列大小
有时你可能会增加队列的大小以防止请求被拒绝,但要结合资源实际进行修改,千万别盲目修改。
实际上,如果值设置的非常大,甚至可能适得其反。因为通过设置更大的队列大小,该节点将需要使用更多的内存来存储队列,这就意味着将剩下相对较少的内存来响应和管理实际请求。
此外,增加队列大小还会增加将操作响应保留在队列中的时间长度,从而导致客户端应用程序面临超时问题。
认知 4:加强监控
通常,唯一有需要增加队列大小的情况是:在请求数量激增导致无法在客户端管理此过程且资源使用率并未达到峰值。
你可以借助 Kibana Stack Monitoring 可视化监控指标以更好地了解 Elasticsearch 集群的性能。
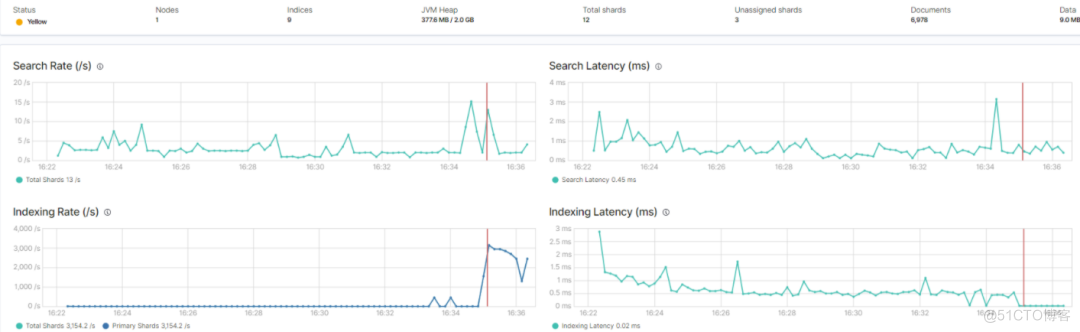
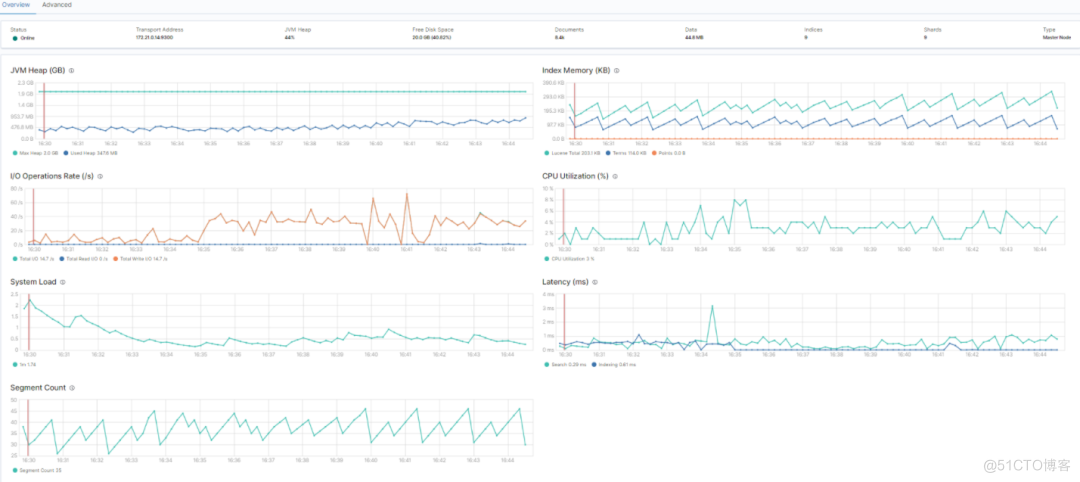
Kibana 监控面板中的总视图、节点视图、索引视图如下所示:
-
总视图监控
-
节点视图监控

- 索引视图监控
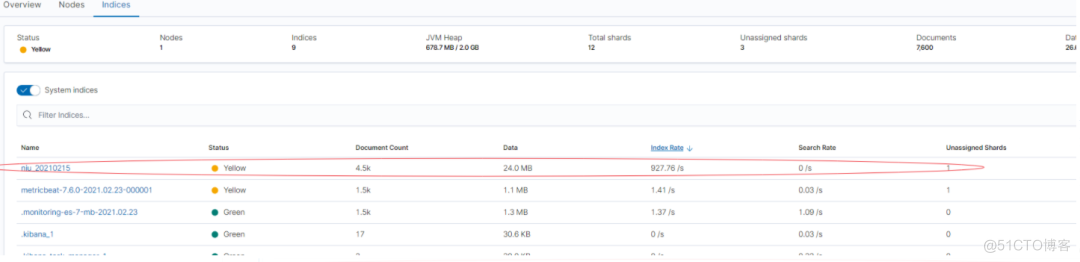
上图是:Kibana 7.6 版本中的监控截图,标红的地方是在批量写入数据。
- search Rate:检索速率
- search Latency:检索延时
- indexing Rate:写入速度
- indexing Latency:写入延时
队列的增加(Growing)表明 Elasticsearch难以满足请求,而拒绝(rejection)则表明队列已经增长到 Elasticsearch 拒绝的程度。
需要检查导致队列增加的根本原因,并尝试通过在客户端减轻相关写入或检索操作来平衡对集群线程池的压力。
八、线程池线上实战问题及注意事项
8.1 线程池和队列修改需要更改配置文件 elasticsearch.yml
- 节点级别配置,而不再支持 5.X 之前的版本动态 setting 修改。
- 重启集群后生效。
8.2 reject 拒绝请求的原因有多种
如果 Elasticsearch 集群开始拒绝索引/写入(index)请求,则可能有多种原因。
通常,这表明一个或多个节点无法跟上索引 / 删除 / 更新 / 批量请求的数量,从而导致在该节点上建立队列且队列逐渐累积。
一旦索引队列超过队列的设置的最大值(如 elasticsearch.yml 定义的值或者默认值),则该节点将开始拒绝索引请求。
排查方法:需要检查线程池的状态,以查明索引拒绝是否总是在同一节点上发生,还是分布在所有节点上。
GET /_cat/thread_pool?v- 如果 reject 仅发生在特定的数据节点上,那么您可能会遇到负载平衡或分片问题。
- 如果 reject 与高 CPU 利用率相关联,那么通常这是 JVM 垃圾回收的结果,而 JVM 垃圾回收又是由配置或查询相关问题引起的。
- 如果集群上有大量分片,则可能存在过度分片的问题。
- 如果观察到节点上的队列拒绝,但监控发现 CPU 未达到饱和,则磁盘写入速度可能存在问题。
8.3 写入 bulk 值要递进步长调优
不要妄图快速提高写入速度,一下调很大,很大势必会写入 reject。
首先尝试一次索引 100 个文档,然后索引 200 个,再索引 400 个,依此类推......
当索引写入速度(indexing rate)开始趋于平稳时,便知道已达到数据批量请求的最佳大小。
九、小结
写入 reject、“429 too many requests” 等都是非常常见的错误,问题多半和线程池和队列大小有关系,需要结合业务场景进行问题排查。
其它参数设置
thread_pool.search.queue_size: 500 thread_pool.search.size: 200 thread_pool.search.min_queue_size: 10 thread_pool.search.max_queue_size: 1000 thread_pool.search.auto_queue_frame_size: 2000 thread_pool.search.target_response_time: 6s thread_pool.bulk.queue_size: 1024 cluster.routing.allocation.disk.include_relocations: false indices.memory.index_buffer_size: 15% indices.breaker.total.limit: 30% indices.breaker.request.limit: 6% indices.breaker.fielddata.limit: 3% indices.query.bool.max_clause_count: 300000 indices.queries.cache.count: 500 indices.queries.cache.size: 5%参考: https://blog.csdn.net/aa5305123/article/details/86542105
https://blog.csdn.net/hyx216/article/details/90179300
https://blog.csdn.net/laoyang360/article/details/114267168
https://www.dovov.com/searchesrejectedexecutionexceptionsearch.html
https://www.bbsmax.com/A/rV57p7oWdP/