目录
- okio库的类结构
- okio 主要的接口和类
- okio接口和类的说明
- okio读取文件
- Okio.source 方法
- Okio.buffer 方法
- readUtf8() 方法
- 总结
- Okio双流操作
- Segment类的设计
- Segment的特点
- Segment成员变量
- Segment成员方法
- Segment的回收与复用
- Buffer类的设计
- Buffer成员变量
- Buffer成员方法
okio库的类结构
okio 主要的接口和类
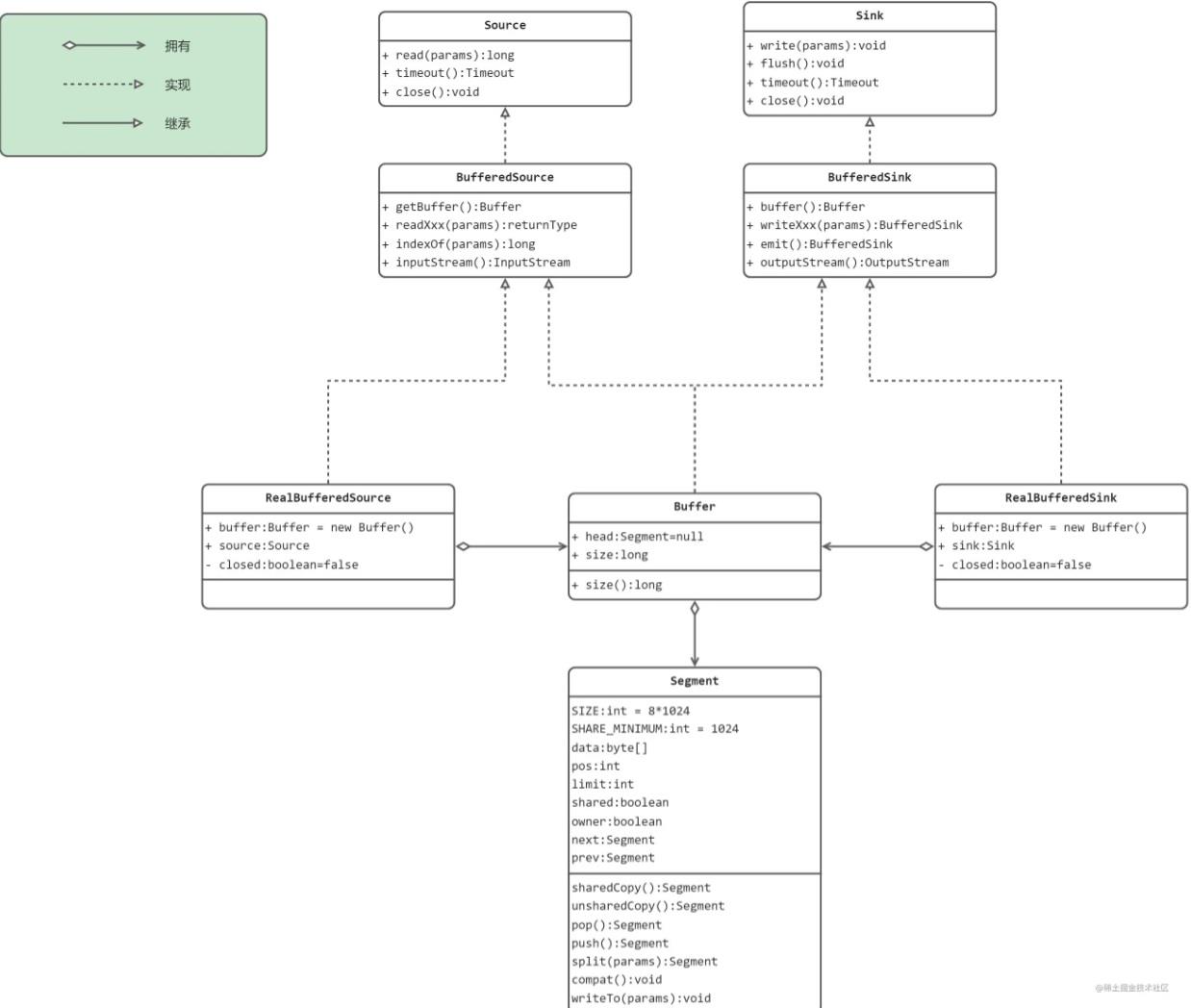
okio接口和类的说明
readXxx系列方法是从缓冲区读出数据的方法。writeXxx系列方法是向缓冲区写入数据的方法。
okio读取文件
使用 okio 来读取文件非常的简单,只需要简单的几步。
- 调用
Okio.source方法获得Source对象 - 调用
Okio.buffer方法获得BufferedSource对象。因为BufferedSource是个接口,它里面定义了一系列的readXxx方法,可以用来方便的读取输入流的内容。
public void readFile() {
try {
FileInputStream fis = new FileInputStream("test.txt");
okio.Source source = Okio.source(fis);
BufferedSource bs = Okio.buffer(source);
String res = bs.readUtf8();
System.out.println(res);
} catch (Exception e){
e.printStackTrace();
}
}
Okio.source 方法
Okio.source重写了read方法,并返回一个Source对象。所以当我们调用**Source**对象的**read(Buffer sink, long byteCount)**方法时,其实是在调用该处重写的方法。read方法会从输入流进行一次读取操作,将数据读取到尾部的Segment中。
private static Source source(final InputStream in, final Timeout timeout) {
if (in == null) throw new IllegalArgumentException("in == null");
if (timeout == null) throw new IllegalArgumentException("timeout == null");
return new Source() {
@Override public long read(Buffer sink, long byteCount) throws IOException {
if (byteCount < 0) throw new IllegalArgumentException("byteCount < 0: " + byteCount);
if (byteCount == 0) return 0;
try {
// 判断是否中断这次的读取操作
timeout.throwIfReached();
// 获取双链表尾部的 Segment
Segment tail = sink.writableSegment(1);
// 从输入流最多读取 maxToCopy 个字节
int maxToCopy = (int) Math.min(byteCount, Segment.SIZE - tail.limit);
// 从输入流读取数据到 Segment
int bytesRead = in.read(tail.data, tail.limit, maxToCopy);
// 到达输入流尾部
if (bytesRead == -1) return -1;
// 更新 tail 的 limit
tail.limit += bytesRead;
// 更新 sink 的 size 值
sink.size += bytesRead;
return bytesRead;
} catch (AssertionError e) {
if (isAndroidGetsocknameError(e)) throw new IOException(e);
throw e;
}
}
@Override public void close() throws IOException {
in.close();
}
@Override public Timeout timeout() {
return timeout;
}
@Override public String toString() {
return "source(" + in + ")";
}
};
}
read 方法首先会调用timeout.throwIfReached(),这个方法是Okio中的同步超时检测。它的作用有两个,一是检查当前线程是否中断,二是判断即将开始的读取操作是否在已经到达了截止时间,以上有任何一个条件不满足,将会抛出异常中断此次操作。比如我们将上面读取文件的代码设置一下读取操作需要在未来的1ms内完成。这意味着接下来的readUtf8操作,必须要在未来的1ms内完成,否则抛出异常。
public void readFile() {
try {
FileInputStream fis = new FileInputStream("test.txt");
okio.Source source = Okio.source(fis);
BufferedSource bs = Okio.buffer(source);
// 设置超时时间为 1ms
source.timeout().deadline(1, TimeUnit.MILLISECONDS);
String res = bs.readUtf8();
System.out.println(res);
} catch (Exception e){
e.printStackTrace();
}
}
上面代码将会抛出如下异常。由于throwIfReached是在每次读取数据之前调用并且与数据读取在同一个线程,所以如果读取操作阻塞,则无法及时抛出异常。
java.io.InterruptedIOException: deadline reached at okio.Timeout.throwIfReached(Timeout.kt:102) at okio.InputStreamSource.read(JvmOkio.kt:87) at okio.Buffer.writeAll(Buffer.kt:1642) at okio.RealBufferedSource.readUtf8(RealBufferedSource.kt:297)
又或者在读取操作之前中断了线程,也会抛出同样的异常,如下代码。
public void readFile() {
Thread thread = new Thread(){
@Override
public void run() {
try {
FileInputStream fis = new FileInputStream("test.txt");
okio.Source source = Okio.source(fis);
BufferedSource bs = Okio.buffer(source);
// 中断当前线程
interrupt();
String res = bs.readUtf8();
System.out.println(res);
} catch (Exception e){
e.printStackTrace();
}
}
};
thread.start();
try {
thread.join();
} catch (Exception e) {
e.printStackTrace();
}
}
这里简单介绍了Okio的同步超时机制,而异步超时机制,这里就不做介绍了。
read方法接着会将数据读取到双链表最尾部的Segment中,关于Segment是啥,这里暂时理解成它是一个存放数据的容器就行了。后面会详细介绍。
Okio.buffer 方法
Okio.buffer方法的看起来就简单多了,直接实例化了一个RealBufferedSource对象返回。 RealBufferedSource实现了BufferedSource接口,所以会有一系列的readXxx方法。注意此处传入了**Source**对象,所以在**RealBufferedSource**中调用**source**对象的**read**方法,是在调用上面重写过的**read**方法!
public static BufferedSource buffer(Source source) {
return new RealBufferedSource(source);
}
readUtf8() 方法
RealBufferedSource实现了BufferedSource接口,所以调用readUtf8()方法来读取字符串时候,其实调用的是RealBufferedSource的readUtf8()方法。下面是readUtf8()方法的源码。
@Override public String readUtf8() throws IOException {
buffer.writeAll(source);
return buffer.readUtf8();
}
1.buffer.writeAll(source)会将数据写入Buffer的Segment中,来看看这个方法的实现。我们发现,这里会循环的调用**source.read**方法,上面我们说过,调用**source**对象的**read**方法,是在调用上面重写过的**read**方法!所以writeAll方法的任务就是将所有的数据写入到一个或多个Segment中(一个Segment的最大容量是8kb,如果数据量大,一个Segment可能读取不了这么多)。
@Override public long writeAll(Source source) throws IOException {
if (source == null) throw new IllegalArgumentException("source == null");
long totalBytesRead = 0;
for (long readCount; (readCount = source.read(this, Segment.SIZE)) != -1; ) {
totalBytesRead += readCount;
}
return totalBytesRead;
}
- 2.
buffer.readUtf8()会将存储在Segment中的数据读出,转化为字符串。若一个Segment的数据被读完且它是非共享的,那么这个Segment将会被回收。
总结
使用Okio来读取输入流的数据,Okio首先会将所有的数据读取到**Buffer**类的一个或多个**Segment**中,当我们想要获取这些数据的时候,再从**Segment**中读出来。Buffer这个类是整个Okio框架的灵魂所在,它实现了BufferedSource, BufferedSink接口,最终的读写操作都会交给它来完成。而RealBufferedSource和RealBufferedSink更像是中间人,负责把读写任务交给Buffer。
有读者到这就会问了,使用Okio来读取数据并没有看到明显的优势,就是在API调用上精简了一些。其实不然,Okio天然的设计了Segment作为数据的缓冲区。同时Segment是可以回收和复用的,这就减少了内存的消耗,提高了内存的利用率。考虑一种双流操作,先读取输入流的内容再写入到输出流。传统的操作首先要将输入流缓冲区的数据拷贝到一个字节数组中,然后再将字节数组的内容拷贝到输出流缓冲区,这中间存在不同缓冲区的数据拷贝操作。而对于Okio来说,在不同缓冲区移动数据,只需移动**Segment**的引用,而非拷贝字节数组。
Okio双流操作
Okio的优点在于设计了Segment,而双流操作最能体现出这种天然的优势。下面代码首先从test.txt中读取文件内容,然后写入test2.txt中。
public void readAndWrite() {
try {
FileInputStream fis = new FileInputStream("test.txt");
Source source = Okio.source(fis);
BufferedSource bSource = Okio.buffer(source);
FileOutputStream fos = new FileOutputStream("test2.txt");
Sink sink = Okio.sink(fos);
BufferedSink bSink = Okio.buffer(sink);
while (!bSource.exhausted()){
// 不停的从 test.txt 中读取数据并写入到 test2.txt
bSource.read(bSink.buffer(), 8*1024);
// 将输出流缓冲区的数据完全写入到文件中
bSink.emit();
}
bSource.close();
bSink.close();
} catch (Exception e) {
e.printStackTrace();
}
}
特别注意上面read最终会调用到Buffer类的write(Buffer source, long byteCount)方法,这个方法可以说是Buffer类最重要的方法。当将一个Buffer缓冲区的数据写入到另一个Buffer缓冲区**,并不会拷贝字节,而是移动****Segment****的引用。**除此之外,该方法还使用了Segment的分割与合并操作,将内存利用最大化。正如该方法的注释所言“while balancing two conflicting goals: don't waste CPU and don't waste memory.”(同时平衡两个相互冲突的目标:不浪费CPU和不浪费内存。)
在下文分析Buffer类的设计时,会详细介绍这个方法的源码。
Segment类的设计
Okio将Java类库中的输入输出流做了封装,让我们能很方便的使用这些API来完成文件的读写操作,这是Okio的一个优点。但是仅仅从API封装调用的角度,不能体现出一个框架的优势所在。Okio最精妙的地方是它设计了数据缓冲区**Segment**。
Segment的特点
- Segment是一个循环双链表,有前驱(prev)和后继节点(next)
- 一个Segment可以存储的最大数据量是8kb(8192=8*1024)
- Segment有两种状态,分别是可共享和不可共享,由shared字段来区分(本质上是data字节数组是否共享)。
- 一个Segment如果是共享的,那么只有data字节数组的宿主Segment能对它进行修改。由owner字段来区分当前Segment是不是data字节数组的宿主。
- 一个Segment如果是共享的,那么这个Segment将不可以被回收,data字节数组也不可以被非宿主的Segment所修改。
Segment成员变量
/** 一个Segment的容量 8kb */ static final int SIZE = 8192; /** data可共享阈值,小于这个值则使用 System.arraycopy 拷贝,不共享*/ static final int SHARE_MINIMUM = 1024; final byte[] data; /** 读数据的起始位 */ int pos; /** 写数据的起始位 */ int limit; /** data字节数组是否共享. */ boolean shared; /** 当前Segment是否为data字节数组的宿主Segment,与shared互斥 */ boolean owner; /** 后继节点 */ Segment next; /** 前驱节点 */ Segment prev;
Segment成员方法
Segment sharedCopy() Segment unsharedCopy() Segment pop() Segment push(Segment segment) Segment split(int byteCount) void compact() void writeTo(Segment sink, int byteCount)
sharedCopy 共享拷贝
sharedCopy是共享拷贝的意思,该方法会将shared字段改为true,然后实例化一个新的Segment返回。新的Segment会与当前Segment共享data字节数组(本质上是都持有data数组的引用),新返回的Segment并不是data字节数组的宿主Segment,所以它不能对data数组进行修改操作。同样,当一个Segment被标记为共享状态的时候,不能够被回收。
final Segment sharedCopy() {
shared = true;
return new Segment(data, pos, limit, true, false);
}
unsharedCopy 非共享拷贝
unsharedCopy非共享拷贝,该方法对data字节数组进行深拷贝,返回的Segment完完全全是一个新的对象。
final Segment unsharedCopy() {
return new Segment(data.clone(), pos, limit, false, true);
}
pop 将当前 Segment 从双链表中移除
pop方法可以将当前的Segment从它所在的双链表中移除,并返回它的后继节点(下一个节点)。若链表中只有一个节点(只有当前节点),则将当前节点移除后返回null。
public final @Nullable Segment pop() {
Segment result = next != this ? next : null;
prev.next = next;
next.prev = prev;
next = null;
prev = null;
return result;
}
pop方法涉及到循环双链表删除节点的操作,这里详细介绍下。 当链表中只有当前Segment,调用pop方法后,结构会发生如下变化,当前Segment不再会有指向它的引用,会在某个时刻被垃圾回收掉。

其实不论链表中有多少个节点,要删除哪一个节点。循环双链表中删除节点的操作都是一样的,只需将当前要删除节点的前一个节点的next引用指向到要删除节点的下一个节点,将当前要删除节点的后一个节点的pre引用指向到要删除节点的前一个节点。对应如下两行代码。
prev.next = next; next.prev = prev;
然后将待删除节点的prev和next引用指向null,这样需要删除的节点就脱离了这个链表,等待垃圾回收。
next = null; prev = null;
push 将一个 Segment 添加到当前 Segment 后面
push方法可以将一个Segment添加到当前Segment的后面,与上述链表节点的删除操作类似,也是改变prev和next引用的指向来实现的,这里就不再详细说明了。
public final Segment push(Segment segment) {
segment.prev = this;
segment.next = next;
next.prev = segment;
next = segment;
return segment;
}
split 字节数组数据分割
split方法可以将当前Segment分割成两个Segment(实际上是将data字节数组的数据分成两部分)。传入的byteCount参数决定了分割后的第一个Segment含有多少个字节的数据。第一个Segment会有[pos+byteCount, limit)区间的数据,第二个Segment含有[pos, pos+byteCount)区间的数据,都是左闭右开区间。
public final Segment split(int byteCount) {
// byteCount 参数合法性校验,若要分割的字节数量 <=0 或 > 已有的数据量,则抛出异常
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
// 从当前Segment分割出一个新的Segment(prefix)
//1. 若要分割的字节数 >= SHARE_MINIMUM(1kb),则采用共享拷贝(拷贝引用)的方式
//2. 若分割的字节数 < 1kb,则采用拷贝的方式(完全复制,新开辟内存空间)
if (byteCount >= SHARE_MINIMUM) {
prefix = sharedCopy();
} else {
prefix = SegmentPool.take();
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
// 更新刚分割出来的Segment(prefix)的limit值, [pos, limit = (pos+byteCount))
prefix.limit = prefix.pos + byteCount;
// 更新当前Segment的pos值, [pos = (pos+byteCount), limit)
pos += byteCount;
// 将新分割出来的Segment(prefix)添加到当前Segment的后面
prev.push(prefix);
// 返回新分割出来的 Segment(prefix)
return prefix;
}
假设当前有一个Segment存储了2kb的数据,现在要分割出512b的数据(byteCount = 512),使用split方法分割的流程如下。
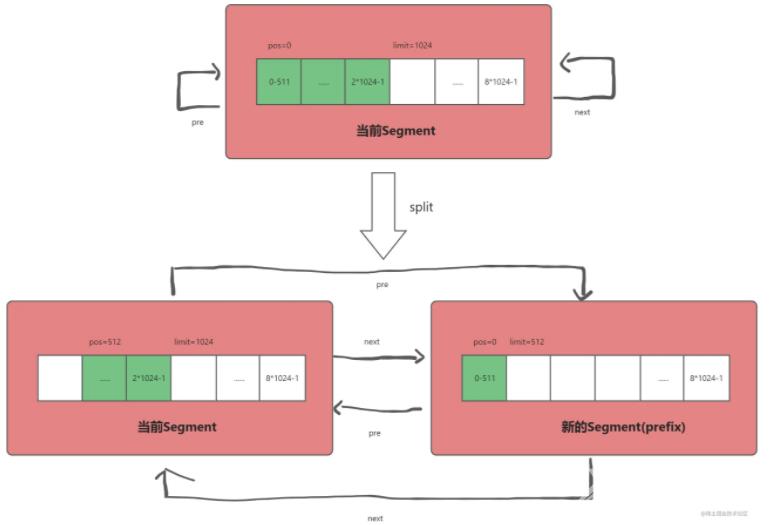
需要注意的是,若采用共享拷贝的方式,那当前Segment和分割出来的Segment共享同一个data字节数组(data数组内存空间一样),区别是pos和limit的值会不同。若采用完全拷贝的方式,那么两个Segment就是完全独立的,即各自的data字节数组在不同的内存空间,不共享。split方法遵循了**"大块数据移动引用,小块数据进行拷贝"**的思想,平衡了CPU与内存的消耗。
writeTo Segment之间字节数组数据的移动
writeTo 方法可以将byteCount个字节数据从当前Segment移动到sink中去。
public final void writeTo(Segment sink, int byteCount) {
// sink 参数合法性校验,若sink非data的宿主Segemnt,则抛出异常。
// 这说明获得数据的Segment必须是data的宿主,只有宿主Segment才能对data进行修改
if (!sink.owner) throw new IllegalArgumentException();
// 若 sink 从 limit 开始写数据,剩余的容量不足以容纳 byteCount 个字节
if (sink.limit + byteCount > SIZE) {
// We can't fit byteCount bytes at the sink's current position. Shift sink first.
if (sink.shared) throw new IllegalArgumentException();
// (byteCount > SIZE - (sink.limit-sink.pos))
// 即 sink 剩余的容量不能容纳 byteCount 个字节数据,抛出异常
if (sink.limit + byteCount - sink.pos > SIZE) throw new IllegalArgumentException();
// 移动 sink 的数据,从 pos = 0 开始
System.arraycopy(sink.data, sink.pos, sink.data, 0, sink.limit - sink.pos);
sink.limit -= sink.pos;
sink.pos = 0;
}
// 拷贝数据到 sink
System.arraycopy(data, pos, sink.data, sink.limit, byteCount);
// 更新 sink 的 limit 值
sink.limit += byteCount;
// 更新当前 Segment 的 pos 值
pos += byteCount;
}
从上面代码可以看出,writeTo方法可以将当前Segment的一部分数据移动到sink中。需要注意的是,若sink从limit位置开始写入数据,sink剩余的容量不足以容纳byteCount个字节,那么首先会将sink原有的数据移动到数组pos=0的位置,再从新的limit位置写。若足以容纳,则从直接从最初的limit位置开始写。
compact 字节数组数据的合并
compact方法可以将当前Segment与它的前驱Segment合并成一个Segment。
public final void compact() {
// 若链表中只有一个Segment,无法合并。抛出异常
if (prev == this) throw new IllegalStateException();
// 若待合并的 prev 节点非宿主,无法进行合并操作
if (!prev.owner) return; // Cannot compact: prev isn't writable.
// 当前 Segment 存储的字节数
int byteCount = limit - pos;
// prev 剩余的容量,SIZE - (prev.limit- prev.pos)
int availableByteCount = SIZE - prev.limit + (prev.shared ? 0 : prev.pos);
// 若 prev 剩余的容量不足以容纳当前 Segment 的数据,无法合并
if (byteCount > availableByteCount) return; // Cannot compact: not enough writable space.
// 将当前 Segment 的数据移动到 prev
writeTo(prev, byteCount);
// 将当前 Segment 从链表中移除
pop();
// 回收当前的 Segment
SegmentPool.recycle(this);
}
Segment的回收与复用
前面我们多次提到,Okio为了节约内存资源,Segment可以回收和复用。当一个Segment中不再有数据的时候(数据被读过或被写入到输出流),会被回收。而当要使用Segment来保存数据的时候,就可以从“池子”中取出一个Segment来使用,而不是直接new。SegmentPool这个类提供了recycle和take两个方法,分别对应于Segment的回收与复用。在SegmentPool中使用单链表结构来保存已回收的Segment。下面是该类的源码。
final class SegmentPool {
// 池子里最多有 8 个 Segment
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
// 单链表的头结点
static @Nullable Segment next;
// 池子中所有Segment的字节总数
static long byteCount;
private SegmentPool() {
}
// Segment 复用,取单链表头结点
static Segment take() {
synchronized (SegmentPool.class) {
if (next != null) {
Segment result = next;
next = result.next;
result.next = null;
byteCount -= Segment.SIZE;
return result;
}
}
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
// Segment 回收,将其放到单链表头部
static void recycle(Segment segment) {
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
if (segment.shared) return; // This segment cannot be recycled.
synchronized (SegmentPool.class) {
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
byteCount += Segment.SIZE;
segment.next = next;
segment.pos = segment.limit = 0;
next = segment;
}
}
}
本质上take和recycle方法涉及单链表节点的删除和添加操作,若需要Segment,则调用take。若要回收某个Segment,则调用recycle。
Buffer类的设计
Buffer类实现了BufferedSource和BufferedSink接口,最终数据的读取和写入操作都会交给这个类。
Buffer成员变量
head是循环双链表的头结点,每次读数据的时候,从这个头结点开始读。因为是循环双链表,尾结点就是head.prev,每次写数据,从尾结点开始写。size是Segment链表中保存的字节总数。当size==0时,表明该Buffer缓冲区已经没有数据。
@Nullable Segment head; long size;
Buffer成员方法
write 缓冲区之间的数据移动
回顾下Okio的双流操作。在两个缓冲区之间移动数据,是不会拷贝字节的,而是移动Segment的引用。write(Buffer source, long byteCount)方法可以将source缓冲区byteCount个字节移动到当前缓冲区。现在详细分析下write(Buffer source, long byteCount)方法的源码,它到底是如果做到的。
@Override public void write(Buffer source, long byteCount) {
// 参数合法性校验
if (source == null) throw new IllegalArgumentException("source == null");
if (source == this) throw new IllegalArgumentException("source == this");
checkOffsetAndCount(source.size, 0, byteCount);
// 当 byteCount > 0
while (byteCount > 0) {
// Is a prefix of the source's head segment all that we need to move?
// 若 byteCount 个字节数据存在于 source 的头部 Segment
if (byteCount < (source.head.limit - source.head.pos)) {
Segment tail = head != null ? head.prev : null;
// 若当前缓冲区尾部的 Segment 不为 null && 是宿主 Segment && 能容纳 byteCount 个字节
if (tail != null && tail.owner
&& (byteCount + tail.limit - (tail.shared ? 0 : tail.pos) <= Segment.SIZE)) {
// Our existing segments are sufficient. Move bytes from source's head to our tail.
// 直接将 source缓冲区 头部 Segment 的数据移动到当前缓冲区尾部的 Segment
source.head.writeTo(tail, (int) byteCount);
// 更新 source 缓冲区的 size
source.size -= byteCount;
// 更新当前缓冲区的 size
size += byteCount;
// 结束程序
return;
} else {
// We're going to need another segment. Split the source's head
// segment in two, then move the first of those two to this buffer.
// 若当前缓冲区尾部的 Segment 为 null || 无法容纳 byteCount 个字节
// 将 source 缓冲区头部的 Segment 的 byteCount 个字节分割出来
source.head = source.head.split((int) byteCount);
}
}
// Remove the source's head segment and append it to our tail.
// source 缓冲区头部节点
Segment segmentToMove = source.head;
// source 缓冲区头部节点的字节数
long movedByteCount = segmentToMove.limit - segmentToMove.pos;
// 将 source 缓冲区头部节点从双链表中移除,并返回它的下一个节点
source.head = segmentToMove.pop();
// 若当前缓冲区头部节点为 null
if (head == null) {
head = segmentToMove;
head.next = head.prev = head;
} else {
// 若当前缓冲区头部节点不为 null,将 source 缓冲区头部节点添加到当前缓冲区尾部
Segment tail = head.prev;
tail = tail.push(segmentToMove);
// 尝试合并
tail.compact();
}
// 更新 source 缓冲区的 size
source.size -= movedByteCount;
// 更新当前缓冲区的 size
size += movedByteCount;
// 更新 byteCount
byteCount -= movedByteCount;
}
}
从上面源码可以看出,将数据从一个缓冲区移动到另一个缓冲区,根据不同的情况会采取不同的移动策略。
若要移动的byteCount个字节存在于源缓冲区的头部Segment
- 若目的缓冲区的尾部
Segment能容纳byteCount个字节,则直接将源缓冲区头部Segment的byteCount字节移动到目的缓冲区的尾部Segment,程序就结束了。这里采用的策略是拷贝字节,而非移动引用。 - 若目的缓冲区的尾部
Segment不能容纳byteCount个字节,则将源缓冲区头部 Segment 的 byteCount 个字节分割(分割操作使用共享拷贝或者非共享拷贝)出来,生成一个新的Segment将其添加到目的缓冲区的尾部,之后尝试Segment合并操作。
上述代码进行第一次循环运行后,可能已经结束,可能进行下一次循环。简单来说,上述代码并不复杂。有两种数据移动的策略。
- 直接将源缓冲区头部
Segment的byteCount字节移动到目的缓冲区的尾部Segment。这种情况发生一次程序就结束了。这里是在拷贝字节数组。 - 将源缓冲区头部的
Segment添加到目的缓冲的尾部。因为在循环内,这种情况可能进行多次。这里是在移动**Segment**的引用。
经过上述源码的讲解,想必大家对Okio有了更进一步的认识。Okio中最精妙的设计当Segment所属。在缓冲区之间移动大块数据,是在移动**Segment**的引用。而移动小块数据,是在拷贝字节。“不浪费CPU和不浪费内存”。
到此这篇关于源码剖析Android中Okio的使用的文章就介绍到这了,更多相关Android Okio内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!