Unsplash 是一个免费高质量照片的网站 ,都是真实的摄影照片,照片分辨率也很大,对设计师朋友来说是非常好的素材,对一些插图类文案写作的朋友也非常实用,当壁纸效果也很不错。
Unsplash 是一个免费高质量照片的网站,都是真实的摄影照片,照片分辨率也很大,对设计师朋友来说是非常好的素材,对一些插图类文案写作的朋友也非常实用,当壁纸效果也很不错。相应功能代码封已封装成exe工具,希望对你有所帮助,文末附有代码+工具获取方式。
代码:
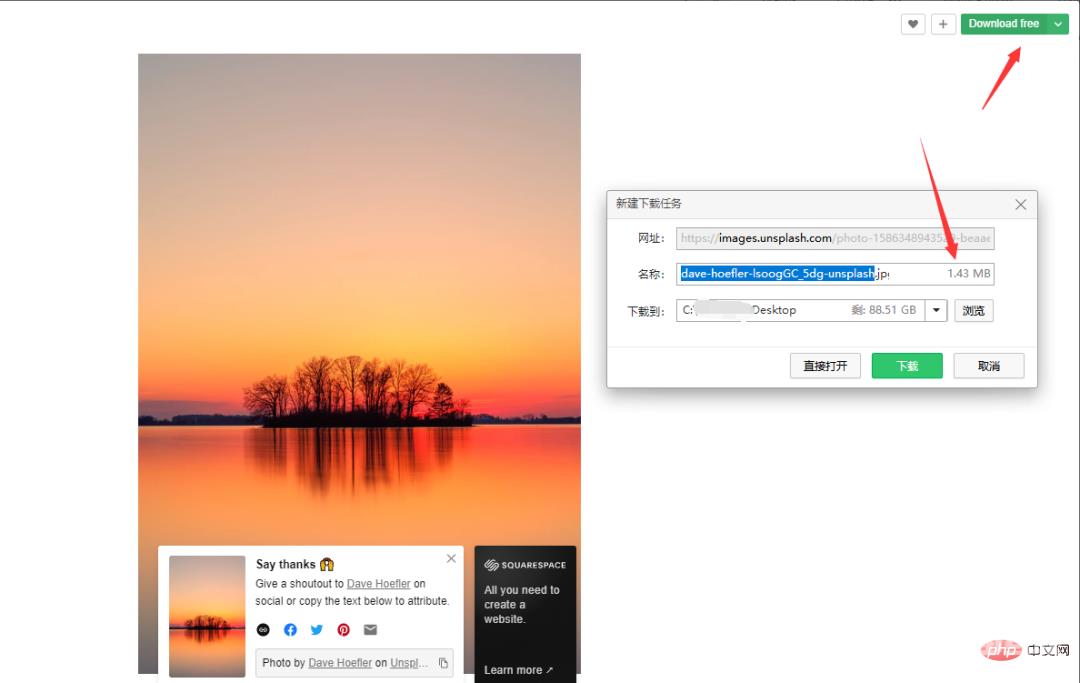
我们先看一下手动下载的过程,注意不是右键图片另存为,右键另存的方式获取的图片是经过一定比例压缩的,清晰度会降低很多。以Nature为例,点击Download free,选择下载路径即可,图片大小1.43M。
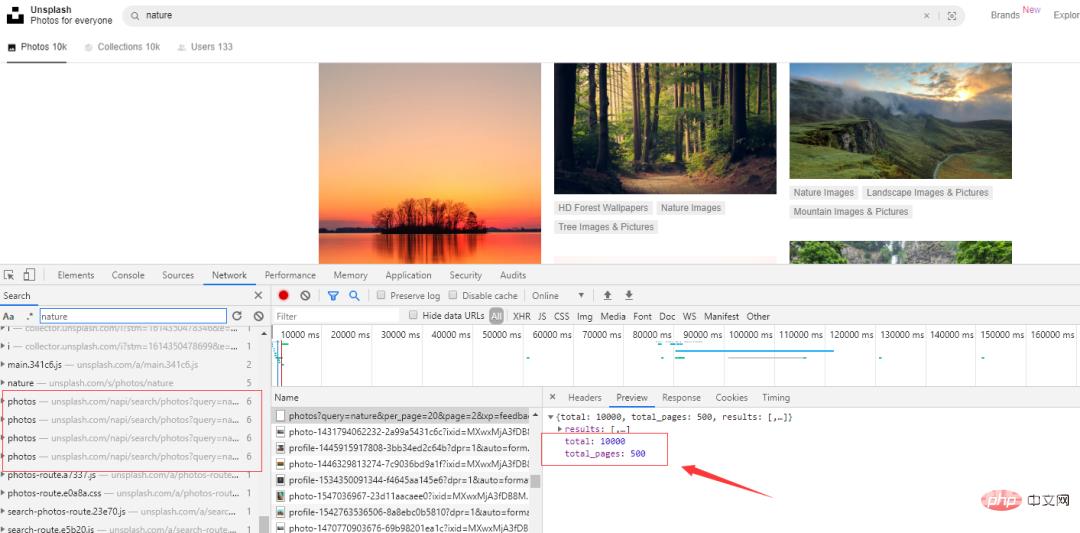
通过几次操作,发现当下拉时,网页会发出如下几个请求,点开其中一个,可以看到图片总数量:10000,总页数:500。
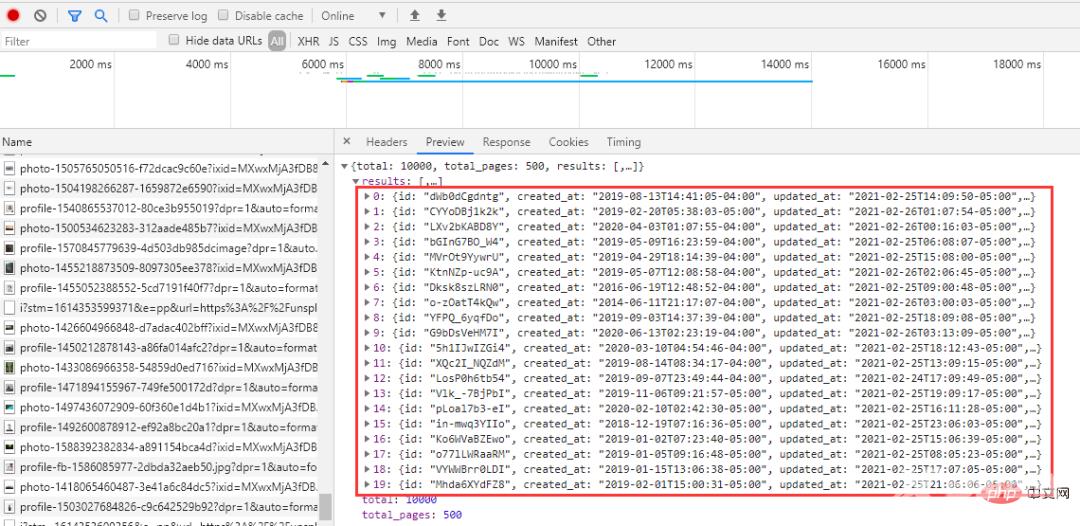
我们把几个url拿出来看一下:

以上链接只有page参数不同,而且是依次递增的,还算是比较友好,请求时依次遍历就可以了。
页码的问题已经解决,接下来分析每张图片的链接:
import time import random import json import requests from fake_useragent import UserAgent
time:定时 random:生成随机数
json:处理json格式数据
requests:网页请求
fake_useragent:代理
ua = UserAgent(verify_ssl=False)
headers = {'User-Agent': ua.random}def getpicurls(i,headers):
picurls = []
url = 'https://unsplash.com/napi/search/photos?query=nature&per_page=20&page={}&xp=feedback-loop-v2%3Aexperiment'.format(i)
r = requests.get(url, headers=headers, timeout=5)
time.sleep(random.uniform(3.1, 4.5))
r.raise_for_status()
r.encoding = r.apparent_encoding
allinfo = json.loads(r.text)
results = allinfo['results']
for result in results:
href = result['urls']['full']
picurls.append(href)
return picurlsdef getpic(count,url):
r = requests.get(url, headers=headers, timeout=5)
with open('pictures/{}.jpg'.format(count), 'wb') as f:
f.write(r.content)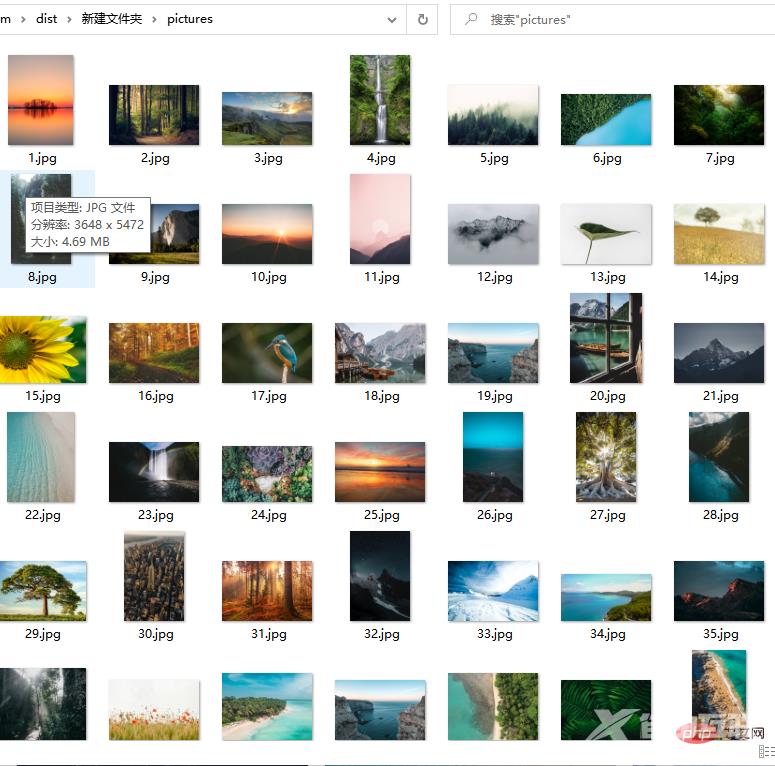
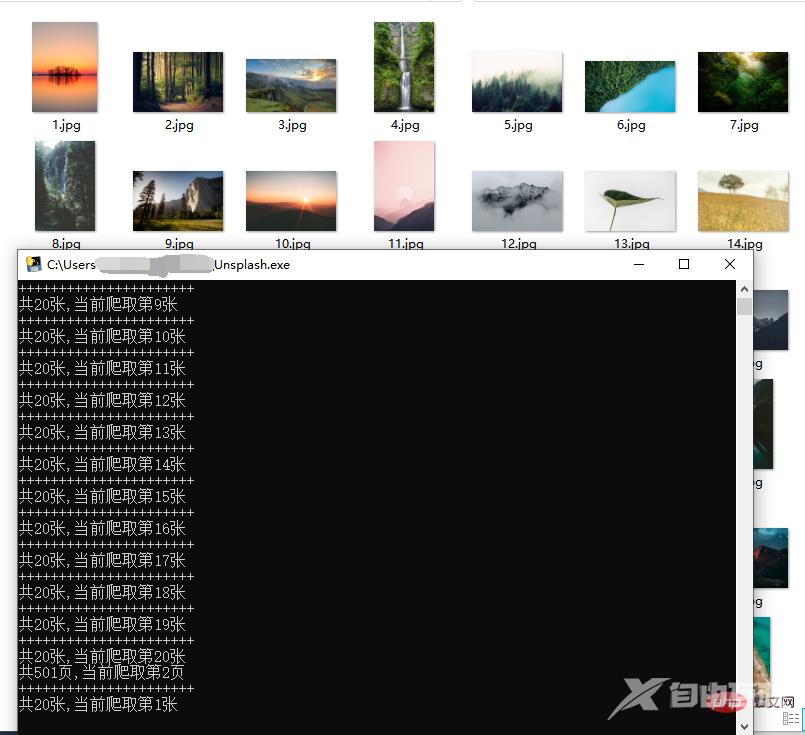
尽量不要频繁的爬取,以免影响网络秩序!
图片为外网高清图片,爬取速度和网络有关,一般不会太快。
可以构建代理池爬取,速度更快。