在 1994 年 Rakesh Agrawal 提出了 Apriori 算法之后,关联规则挖掘技术的可用性得到了很大的提高。而且因为关联规则挖掘与生俱来的商业意义,使得它迅速成为了一个非常热门的研究领域,新的算法也不断地涌现出来。这其中,实用性比较强的一个算法,是由韩家玮教授提出的 FP-Growth 算法。FP-Growth 算法在 2000 年发表的这个 paper 《Mining Frequent Patterns without Candidate Generation》里有详细的介绍。读这篇 paper,我个人建议一定要同时把引文也都看一看,2000 年之前与关联规则挖掘相关的重要 paper,基本上都在里面了。
FP-Growth 算法的核心是 FP-Tree(Frequent Pattern Tree,频繁模式树)的构建,这个特殊的数据结构,是 FP-Growth 算法与 Apriori 算法相比,性能显著提高的原因所在。不过,仔细分析一下 FP-Tree 的实现,可以发现它与字符串处理算法中常用的 Prefix Tree 算法,有着异曲同工之妙。FP-Tree 通过合并一些重复路径,实现了数据的压缩,从而使得将频繁项集加载到内存中成为可能。之后以树遍历的操作,替代了 Apriori 算法中最耗费时间的事务记录遍历,从而大大提高了运算效率。详细的理论讲解可以阅读上面的论文,我这里还是把其中的例子翻译一下。
某数据库 DB 里有 5 条事务记录,取最小支持度(min support threshold)为 3,则生成 FP-Tree 的过程如下:
1、扫描一遍数据库,获取所有频繁项,删除频率小于最小支持度的项。在此操作的过程中,还可以得到每个项的出现频率,供后续步骤使用。这一步完成之后,我们得到以下频繁项, { (c:4), (f:4), (a:3), (b:3), (m:3), (p:3) },“:”之后的数字表示对应项的出现频率。这个结果是排好顺序的,首先按照频率从达到小排序,再按照字母顺序排序。需要注意的是这里的排序非常重要,之后每个事务中的项都要按照这个顺序进行排列,这个是有效合并重复路径的前提。
处理之后的数据库记录为:
TID
原始事务数据
处理后数据
100
f, a, c, d, g, i, m, p
c, f, a, m, p
200
a, b, c, f, l, m, o
c, f, a, b, m
300
b, f, h, j, o
f, b
400
b, c, k, s, p
c, b, p
500
a, f, c, e, l, p, m, n
c, f, a, m, p
2、第二次扫描数据库,在第一次处理完成的结果基础上,构建 FP-Tree。
1) 取出第一条事务数据,构建 FP-Tree 的第一条路径,{ c, f, a, m, p }。注意其中项的排序与第一步中得到的频繁项集合的排序是一致的。
2) 取出第二条事务数据,{ c, f, a, b, m },不难发现,它与第一条路径共享了部分数据{ c, f, a }。因此,可以重复利用已有的路径,只需要将其计数加 1,即{ (c:2), (f:2), (a:2) }。而对于后面不同的部分,我们创建新的路径,{ (b:1), (m:1) },其中,b 为 a 的子节点,m 为 b 的子节点。
3) 取出第三条事务数据,{ f, b },发现没有重复路径存在。但 f 点是存在的,因此,可以重复利用 f 点,新建一个 b 节点,作为 f 的子节点,得到路径{ {f:3}, (b:1) }。注意,之前已经存在的 b 节点无法重复使用,因为其父节点为 a。
4) 取出第四条事务数据,{ c, b, p },发现没有重复路径存在。因此,从现有 c 点出发,构建一条新路径{ (c:3), (b:1), (p:1) }。
5) 取出第五条事务数据,{ c, f, a, m, p },同上原理构建路径,{ (c:4), (f:4), (a:3), (m:2), (p:2) }。
经过两遍数据库扫描,完成了 FP-Tree 的构建。在此例中,c 点为整个 FP-Tree 的唯一根节点,但其实多数情况下,根节点并不是唯一的,即有多棵子树。因此,为了方便树结构的遍历,可以人为添加一个超级根节点,通常标记为 root<null>。参照下图,可以更清楚的理解整个过程。
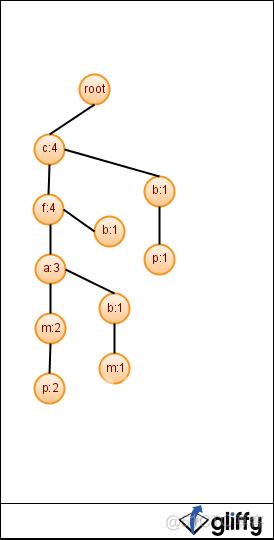
得到了 FP-Tree 树之后,再遍历整棵树获取满足一定置信度的关联规则,就比较简单了。具体的理论证明,以及与 Apriori 算法的 performance 对比,论文里讲得非常清楚,有兴趣的朋友可以看一下。