问题描述 假定采用带头结点的单链表保存单词,当两个单词有相同的后缀,则可共享相同的后缀存储空间,例如,“loaging”和“being”, 如下图所示。 设str1和str2分别指向两个单词所在
问题描述
假定采用带头结点的单链表保存单词,当两个单词有相同的后缀,则可共享相同的后缀存储空间,例如,“loaging”和“being”, 如下图所示。
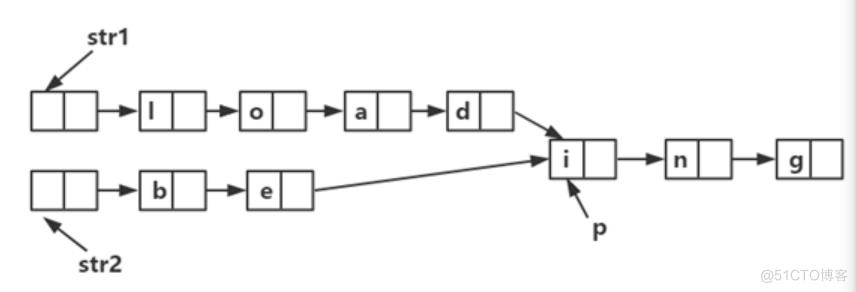
设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为

请设计一个时间上尽可能高效的算法,找出由str1和str2所指向两个链表共同后缀的起始位置(如图中字符i所在结点的位置p)。
解决方法
(1)算法的基本思想
顺序遍历两个链表到尾结点时,并不能保证两个链表同时到达尾结点。这是因为两个链表的长度不同。假设一个链表比另外一个链表长k个结点,之后同步遍历两个链表。这样我们就能够保证它们同时到达最后一个结点。由于两个链表从第一个公共结点到链表的尾结点都是重合的。所以它们肯定同时到达第一个公共结点。于是得到算法思路:
①求它们的长度len1,len2;
②遍历两个链表,使p,q指向的链表等长;
③同步遍历两个链表,直至找到相同结点或链表结束。
(2)代码实现
#include<stdio.h>
#include<stdlib.h>
typedef char ElemType;
typedef struct Node
{
ElemType data;
struct Node *next;
}Node,*LinkList;
int LinkLength(LinkList L)
{
int k=0;
while(L)
{
k++;
L=L->next;
}
return k;
}
LinkList CreateList(int n)
{
LinkList h=(LinkList)malloc(sizeof(Node));
Node *r,*s;
r=h;
char ch;
int i;
for(i=0;i<=n;i++)
{
s=(LinkList)malloc(sizeof(Node));
scanf("%c",&ch);
s->data=ch;
r->next=s;
r=s;
}
r->next=NULL;
h=h->next;
return h;
}
void Print(LinkList L)
{
while(L!=NULL)
{
printf("%c",L->data);
L=L->next;
}
printf("\n");
}
LinkList find(LinkList str1,LinkList str2)
{
LinkList p=str1;
LinkList q=str2;
int len1=LinkLength(str1),len2=LinkLength(str2);
for(p=str1;len1>len2;len1--)//使p指向的链表与q指向的链表等长
p=p->next;
for(q=str2;len1<len2;len2--)//使q指向的链表与p指向的链表等长
q=q->next;
while(p->next!=NULL&&p->data!=q->data)//查找共同后缀起始点
{
p=p->next;
q=q->next;
}
return p;
}
int main()
{
LinkList L1;
int n1;
printf("请输入L1链表的长度,以回车结束,然后输入结点的值:");
scanf("%d",&n1);
L1=CreateList(n1);
printf("L1链表为:");
Print(L1);
LinkList L2;
int n2;
printf("请输入L2链表的长度,以回车结束,然后输入结点的值:");
scanf("%d",&n2);
L2=CreateList(n2);
printf("L2链表为:");
Print(L2);
printf("\n");
LinkList L3;
printf("L1和L2公共后缀的起始结点(即相交结点)为:");
L3=find(L1,L2);
printf("%c",L3->data);
return 0;
}(3)运行结果
