BeautifulSoup模块用于解析html和xml文档中的内容,相比正则表达式,其更好的利用了html这种结构性文档的树状结构,解析起来更加方便。 解析的第一步,是构建一个BeautifulSoup对象,基本
BeautifulSoup模块用于解析html和xml文档中的内容,相比正则表达式,其更好的利用了html这种结构性文档的树状结构,解析起来更加方便。
解析的第一步,是构建一个BeautifulSoup对象,基本用法如下
>>> from bs4 import BeautifulSoup>>> soup = BeautifulSoup(html_doc, 'html.parser')
第二个参数表示解析器,BeautifulSoup支持以下多种解释器,图示如下
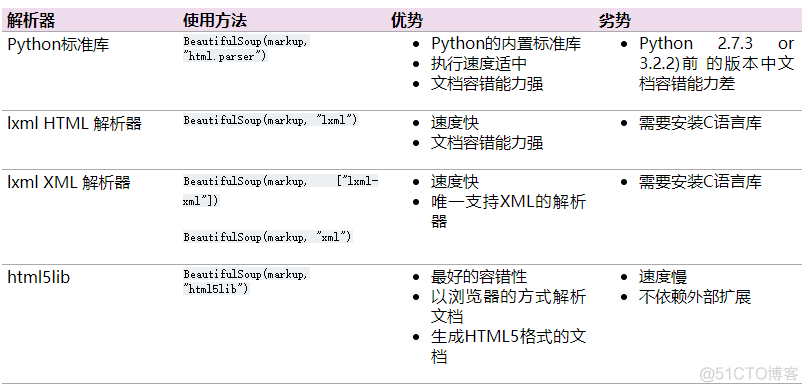
在实际操作中,推荐使用lxm解析器,速度快而且稳定。解析完成后,就得到了一个文档树,我们可以通过这个文档树来快速的查找位点, 其核心就是操作文档树的子节点, 也称之为tag。
1. 访问标签
通过点号操作符,可以直接访问文档中的特定标签,示例如下
>>> soup = BeautifulSoup(html_doc, 'lxml')>>> soup.head
<head><title>The Dormouse's story</title></head>
>>> soup.head.title
<title>The Dormouse's story</title>
>>> soup.a
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
这样的方式每次只会返回文档中的第一个标签,对于多个标签,则通过find_all方法返回多个标签构成的列表,示例如下
>>> soup.find_all('a')[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
>>> soup.find_all('a')[0]
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
还可以在find方法中添加过滤条件,更加精确的定位元素,示例如下
# 通过text进行筛选>>> soup.find_all('a', text='Elsie')
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 通过属性和值来进行筛选
>>> soup.find_all('a', attrs={'id':'link1'})
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
# 上述写法的简便写法,只适合部分属性
>>> soup.find_all('a', id='link1')
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>]
```
# 使用CSS选择器
# 注意class后面加下划线
>>> soup.find_all('p', class_='title')
[<p class="title"><b>The Dormouse's story</b></p>]
2. 访问标签内容和属性
通过name和string可以访问标签的名字和内容,通过get和中括号操作符则可以访问标签中的属性和值
>>> soup.a<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
>>> soup.a['class']
['sister']
>>> soup.a.get('class')
['sister']
>>> soup.a.name
'a'
>>> soup.a.string
'Elsie'
结合定位元素和访问属性的方法,可以方便快捷的提取对应元素,提高解析html的便利性。
·end·

一个只分享干货的
生信公众号