在ENCODE提供的一系列质控指标中针对文库复杂度,提出了以下3种指标 NRF PBC1 PBC2 NRF代表的是非冗余reads的比例,与参考基因组比对之后,我们可以得到所有比对上的reads, 其中有一部
在ENCODE提供的一系列质控指标中针对文库复杂度,提出了以下3种指标
NRF代表的是非冗余reads的比例,与参考基因组比对之后,我们可以得到所有比对上的reads, 其中有一部分是unique mapping的reads, 这些reads唯一比对到基因组上的一个位置,NRF就是unique mapping reads除以total mapped reads。
PBC1和PBC2称之为PCR阻塞系数,和NRF不同,这两个系数通过基因组位置的个数来进行计算。将unique mapping reads比对上的基因组位置称之为M, 根据每个位置上比对上的序列数,称之为M1, M2等,示意如下
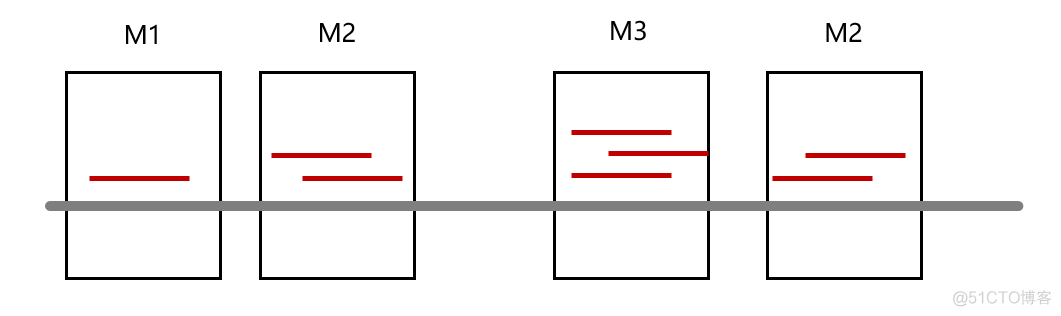
其中,PBC1为M1/M的值,PBC2为M1/M2的值。要计算以上几个指标,有一个很关键的步骤,就是从taotal mapping reads中去除duplicate reads, 得到unique mapping reads,之后就可以根据公式计算以上几个指标了。
针对这这几个指标,ENCODE官方提供的标准如下所示

从计算公式也可以看出,这几个指标的值越大,说明文库中unique mapping reads越多,文库的复杂度越高。通过bedtools可以方便的计算这几个指标,代码如下
bedtools bamtobed -i 10K.nodup.bam | \awk 'BEGIN{OFS="\t"}{print $1,$2,$3,$6}' | \
grep -v 'chrM' | \
sort | \
uniq -c | \
awk 'BEGIN{mt=0;m0=0;m1=0;m2=0} ($1==1){m1=m1+1} ($1==2){m2=m2+1} {m0=m0+1} {mt=mt+$1} END{m1_m2=-1.0; if(m2>0) m1_m2=m1/m2; printf "%d\t%d\t%d\t%d\t%f\t%f\t%f\n",mt,m0,m1,m2,m0/mt,m1/m0,m1_m2}' > pbc.qc
其中m0/mt就是NRF,m1/m0就是PBC1, m1/m2就是PBC2。
·end·

一个只分享干货的
生信公众号