线性判别分析,全称是Linear Discriminant Analysis, 简称LDA, 是一种属于监督学习的降维算法。与PCA这种无监督的降维算法不同,LDA要求输入数据有对应的标签。
LDA降维的基本思想是映射到低维之后,最大化类间均值,最小化类内方差,如下图所示
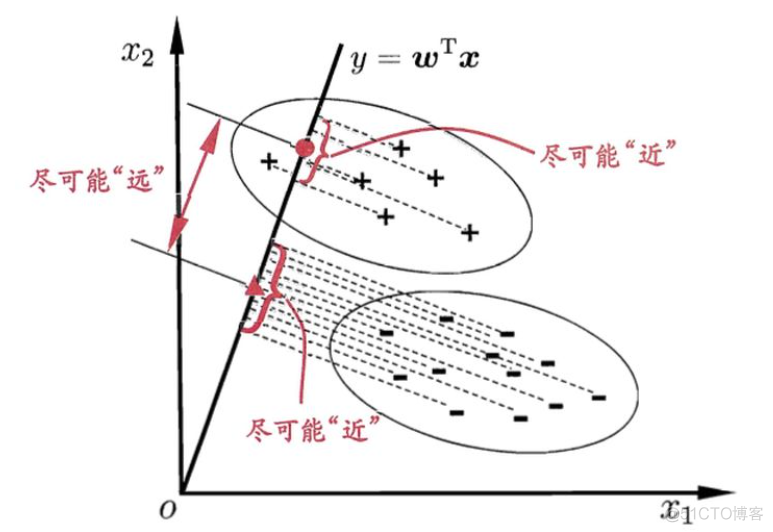
所以在衡量降维效果的好坏时,需要同时考虑以上两个因素。为了定量描述类间均值和类内方差的大小,引入了以下基本概念
1. within-class sctter matrix
称之为类内散度矩阵,用于衡量类内方差,以二分类数据为例,公式如下
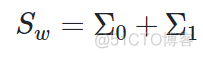
0和1分别表示两个类别数据的协方差,进一步展开,可得如下结果
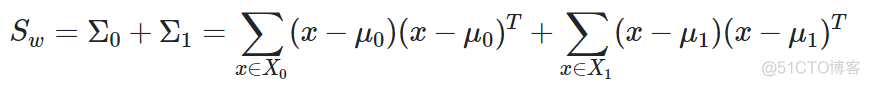
推广到K类数据,公式如下
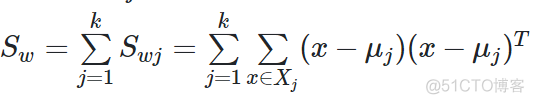
2. between-class scatter matrix
称之为类间散度矩阵,用于衡量类间距离,以二分类数据为例,公式如下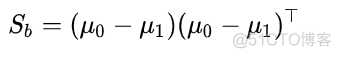
μ表示每类数据的均值向量,推广到K类数据,公式如下
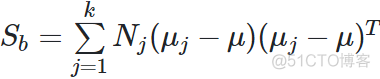
基于以上两个矩阵,提出了LDA算法的目标函数,称之为广义瑞利商。要理解广义瑞丽商,先来看下瑞丽商的定义,公式如下
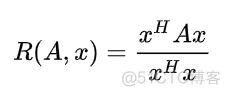
x是非零向量,A为厄米特矩阵,即共轭对称的方阵,A的共轭转置矩阵等于它本身。这样的函数有一个性质,最大值等于矩阵A的最大特征值,最小值等于矩阵A的最小特征值
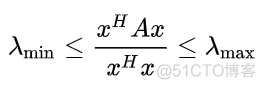
广义瑞丽商公式如下
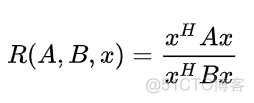
其中x为非零向量,A和B都为厄米特矩阵,将上述函数转化为标准的瑞丽商函数,可以得到如下结果
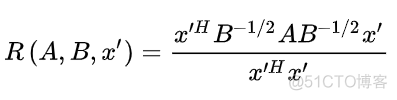
根据瑞丽商函数的性质,我们只需要求以下矩阵的特征值就可以得到函数的最大值和最小值了
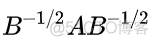
而该矩阵与以下矩阵等价
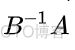
LDA算法也是通过类间散度矩阵和类内散度矩阵这两个矩阵来构建广义瑞丽商形式的优化函数,目标函数如下
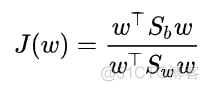
要最大化类间距离,最小化类内方差,就是要求该优化函数的最大值,根据广义瑞丽商的性质,要求该函数的最大值,只需要求以下矩阵的最大特征值即可
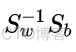
在将数据投影到低纬度k时,只需要提取上述矩阵的前k个特征值对应的特征向量,构成投影矩阵w, 然后将原始的样本点通过该投影矩阵进行投影即可,公式如下
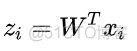
从上述推导可以看出,LDA降维的过程就是先计算类间和类内两个散度矩阵,然后计算特征值和特征向量,构建投影矩阵,最后投影即可。
在scikit-learn中,使用LDA降维的代码如下
>>> from sklearn.discriminant_analysis import LinearDiscriminantAnalysis>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> X = iris.data
>>> y = iris.target
>>> lda = LinearDiscriminantAnalysis(n_components=2)
>>> X_r = lda.fit(X, y).transform(X)
和PCA降维相比,LDA降维是有限制的,最多降低到K-1的维度,K为样本的类别数。
·end·

一个只分享干货的
生信公众号