对于web开发而言,缓存必不可少,也是提高性能最常用的方式。无论是浏览器缓存(如果是chrome浏览器,可以通过chrome:://cache查看),还是服务端的缓存(通过memcached或者redis等内存数据库)。缓存不仅可以加速用户的访问,同时也可以降低服务器的负载和压力。那么,了解常见的缓存淘汰算法的策略和原理就显得特别重要。
常见的缓存算法
- LRU (Least recently used) 最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高。
- LFU (Least frequently used) 最不经常使用,如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
- FIFO (Fist in first out) 先进先出, 如果一个数据最先进入缓存中,则应该最早淘汰掉。
Cache置换
Cache工作原理要求它尽量保存最新数据,但是Cache一般大小有限,当Cache容量达到上限时,就会产生Cache替换的问题。最理想的情况是置换出未来短期内不会被再次访问的数据,但是我们无法预知未来,所以只能从数据在过去的访问情况中寻找规律进行置换。
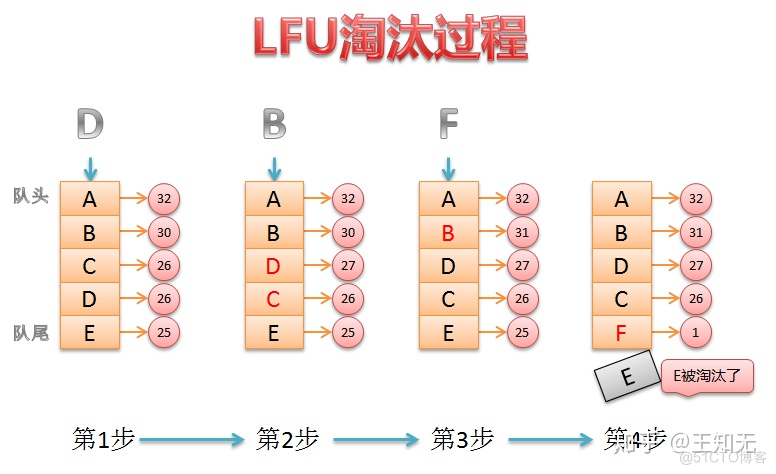
LFU Cache置换算法
Least Frequently Used algorithm LFU是首先淘汰一定时期内被访问次数最少的页!
这种算法选择近期最少访问的页面作为被替换的页面。显然,这是一种合理的算法,因为到目前为止最少使用的页面,很可能也是将来最少访问的页面。
代码如下:
import java.util.*; public class LFUCache { private static final int DEFAULT_MAX_SIZE = 3; private int capacity = DEFAULT_MAX_SIZE; //保存缓存的访问频率和时间 private final Map<Integer, HitRate> cache = new HashMap<Integer, HitRate>(); //保存缓存的KV private final Map<Integer, Integer> KV = new HashMap<Integer, Integer>(); // @param capacity, an integer public LFUCache(int capacity) { this.capacity = capacity; } // @param key, an integer // @param value, an integer // @return nothing public void set(int key, int value) { Integer v = KV.get(key); if (v == null) { if (cache.size() == capacity) { Integer k = getKickedKey(); KV.remove(k); cache.remove(k); } cache.put(key, new HitRate(key, 1, System.nanoTime())); } else { //若是key相同只增加频率,更新时间,并不进行置换 HitRate hitRate = cache.get(key); hitRate.hitCount += 1; hitRate.lastTime = System.nanoTime(); } KV.put(key, value); } public int get(int key) { Integer v = KV.get(key); if (v != null) { HitRate hitRate = cache.get(key); hitRate.hitCount += 1; hitRate.lastTime = System.nanoTime(); return v; } return -1; } // @return 要被置换的key private Integer getKickedKey() { HitRate min = Collections.min(cache.values()); return min.key; } class HitRate implements Comparable<HitRate> { Integer key; Integer hitCount; // 命中次数 Long lastTime; // 上次命中时间 public HitRate(Integer key, Integer hitCount, Long lastTime) { this.key = key; this.hitCount = hitCount; this.lastTime = lastTime; } public int compareTo(HitRate o) { int hr = hitCount.compareTo(o.hitCount); return hr != 0 ? hr : lastTime.compareTo(o.lastTime); } } public static void main(String[] as) throws Exception { LFUCache cache = new LFUCache(3); cache.set(2, 2); cache.set(1, 1); System.out.println(cache.get(2)); System.out.println(cache.get(1)); System.out.println(cache.get(2)); cache.set(3, 3); cache.set(4, 4); System.out.println(cache.get(3)); System.out.println(cache.get(2)); System.out.println(cache.get(1)); System.out.println(cache.get(4)); } }LRU Cache置换算法
Least Recently Used algorithm LRU是首先淘汰最长时间未被使用的页面。
这种算法把近期最久没有被访问过的页面作为被替换的页面。它把LFU算法中要记录数量上的"多"与"少"简化成判断"有"与"无",因此,实现起来比较容易。
像浏览器的缓存策略、memcached的缓存策略都是使用LRU这个算法,LRU算法会将近期最不会访问的数据淘汰掉。LRU如此流行的原因是实现比较简单,而且对于实际问题也很实用,良好的运行时性能,命中率较高。下面谈谈如何实现LRU缓存:
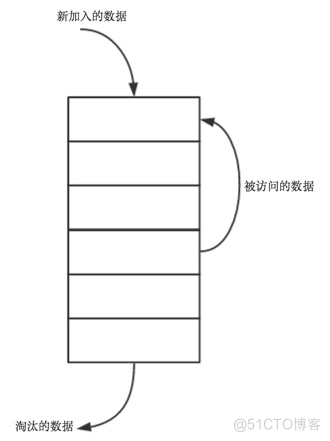
- 新数据插入到链表头部
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部
- 当链表满的时候,将链表尾部的数据丢弃
LRU Cache具备的操作:
-
set(key,value):如果key在hashmap中存在,则先重置对应的value值,然后获取对应的节点cur,将cur节点从链表删除,并移动到链表的头部;若果key在hashmap不存在,则新建一个节点,并将节点放到链表的头部。当Cache存满的时候,将链表最后一个节点删除即可。
-
get(key):如果key在hashmap中存在,则把对应的节点放到链表头部,并返回对应的value值;如果不存在,则返回-1。
代码如下:
//实现起来比较简单. 维护一个链表,每次数据新添加或者有访问时移动到链表尾, //每次淘汰数据则是淘汰链表头部的数据. //也就是最近最少访问的数据在链表头部,最近刚访问的数据在链表尾部 public class LRUCache { private class Node{ Node prev; Node next; int key; int value; public Node(int key, int value) { this.key = key; this.value = value; this.prev = null; this.next = null; } } private int capacity; private HashMap<Integer, Node> hs = new HashMap<Integer, Node>(); private Node head = new Node(-1, -1); private Node tail = new Node(-1, -1); // @param capacity, an integer public LRUCache(int capacity) { // write your code here this.capacity = capacity; tail.prev = head; head.next = tail; } // @return an integer public int get(int key) { // write your code here if( !hs.containsKey(key)) { return -1; } // remove current Node current = hs.get(key); current.prev.next = current.next; current.next.prev = current.prev; // move current to tail move_to_tail(current); return hs.get(key).value; } // @param key, an integer // @param value, an integer // @return nothing public void set(int key, int value) { // write your code here if( get(key) != -1) { hs.get(key).value = value; return; } if (hs.size() == capacity) { hs.remove(head.next.key); head.next = head.next.next; head.next.prev = head; } Node insert = new Node(key, value); hs.put(key, insert); move_to_tail(insert); } private void move_to_tail(Node current) { current.prev = tail.prev; tail.prev = current; current.prev.next = current; current.next = tail; } public static void main(String[] as) throws Exception { LRUCache cache = new LRUCache(3); cache.set(2, 2); cache.set(1, 1); System.out.println(cache.get(2)); System.out.println(cache.get(1)); System.out.println(cache.get(2)); cache.set(3, 3); cache.set(4, 4); System.out.println(cache.get(3)); System.out.println(cache.get(2)); System.out.println(cache.get(1)); System.out.println(cache.get(4)); } }LRU和LFU的区别:
LRU是最近最少使用页面置换算法(Least Recently Used),也就是首先淘汰最长时间未被使用的页面。
LFU是最近最不常用页面置换算法(Least Frequently Used),也就是淘汰一定时期内被访问次数最少的页。
比如,第二种方法的时期T为10分钟,如果每分钟进行一次调页,主存块为3,若所需页面走向为2 1 2 1 2 3 4
注意,当调页面4时会发生缺页中断
若按LRU算法,应换页面1(1页面最久未被使用) 但按LFU算法应换页面3(十分钟内,页面3只使用了一次)
总结
可见LRU关键是看页面最后一次被使用到发生调度的时间长短,而LFU关键是看一定时间段内页面被使用的频率!
参考: https://blog.csdn.net/permike/article/details/92972951
https://zhuanlan.zhihu.com/p/66188820?utm_source=wechat_session