一、算法概述 1.1 算法分类 十种常见排序算法可以分为两大类: 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序
一、算法概述
1.1 算法分类
十种常见排序算法可以分为两大类:
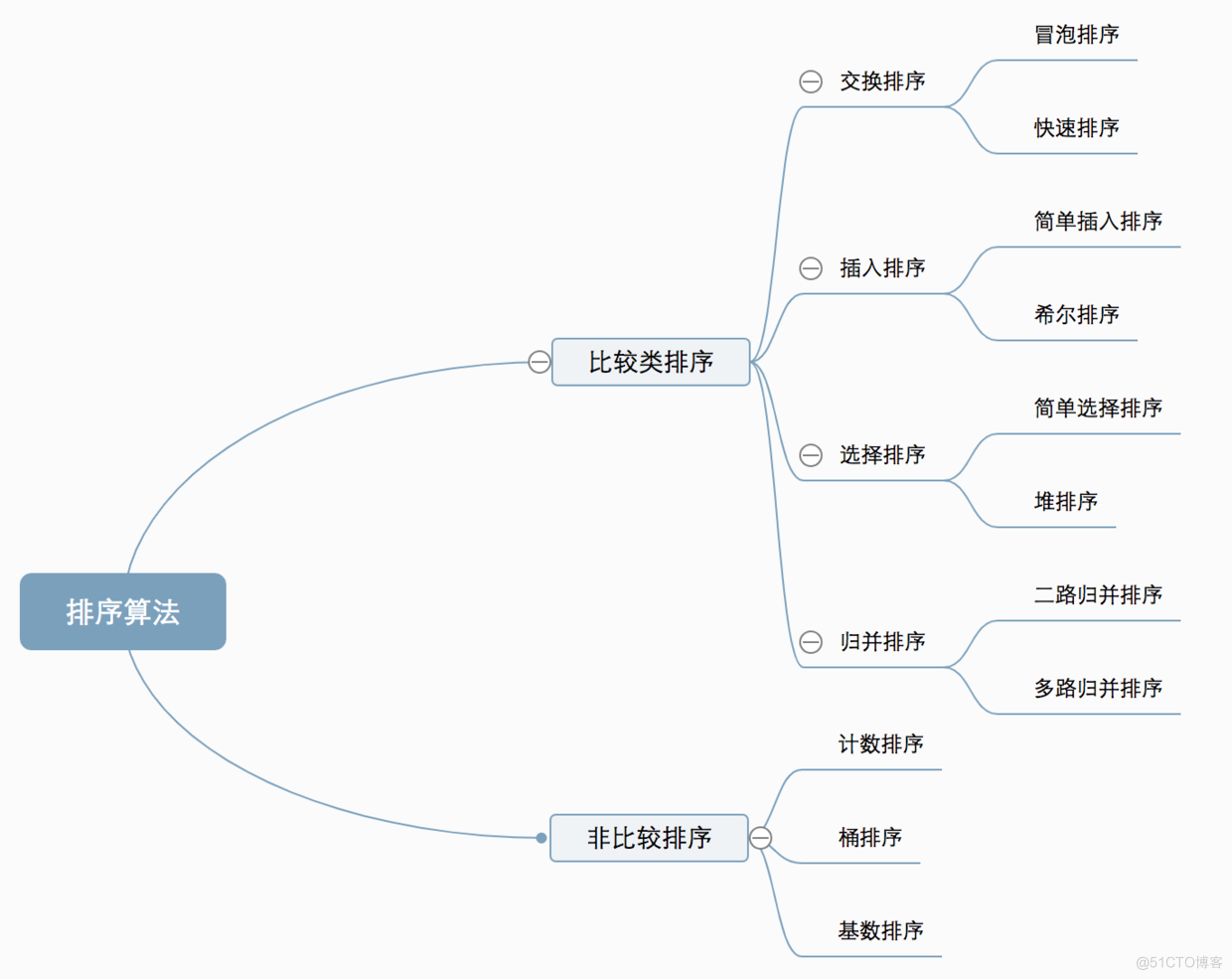
1.2 算法复杂度
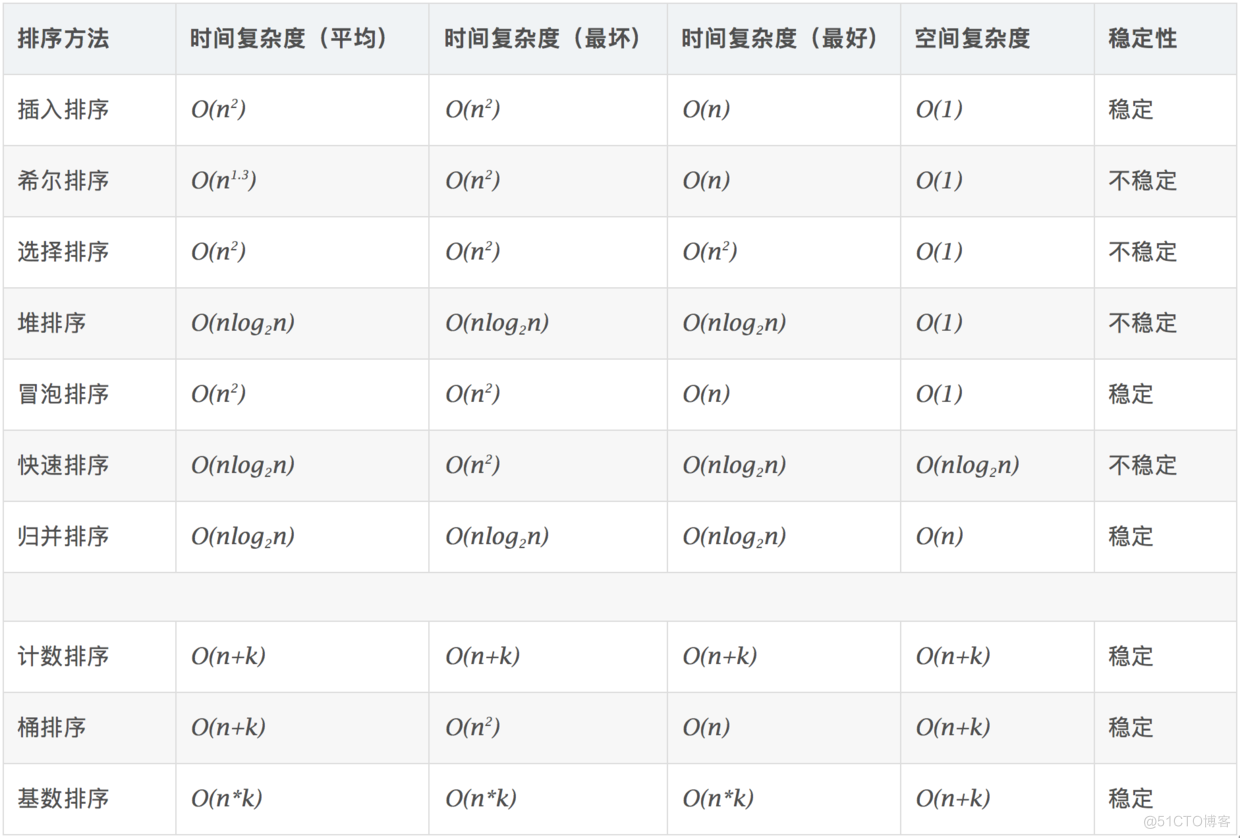
1.3 相关概念
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
二、快速排序(Quick Sort)
快速排序的基本思想:通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
2.1 算法描述
快速排序使用分治法来把一个串(list)分为两个子串(sub-lists)。具体算法描述如下:
- 从数列中挑出一个元素,称为 “基准”(pivot);
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
2.2 动图演示
2.3 排序过程
下面以数列a={30,40,60,10,20,50}为例,演示它的快速排序过程(如下图)。
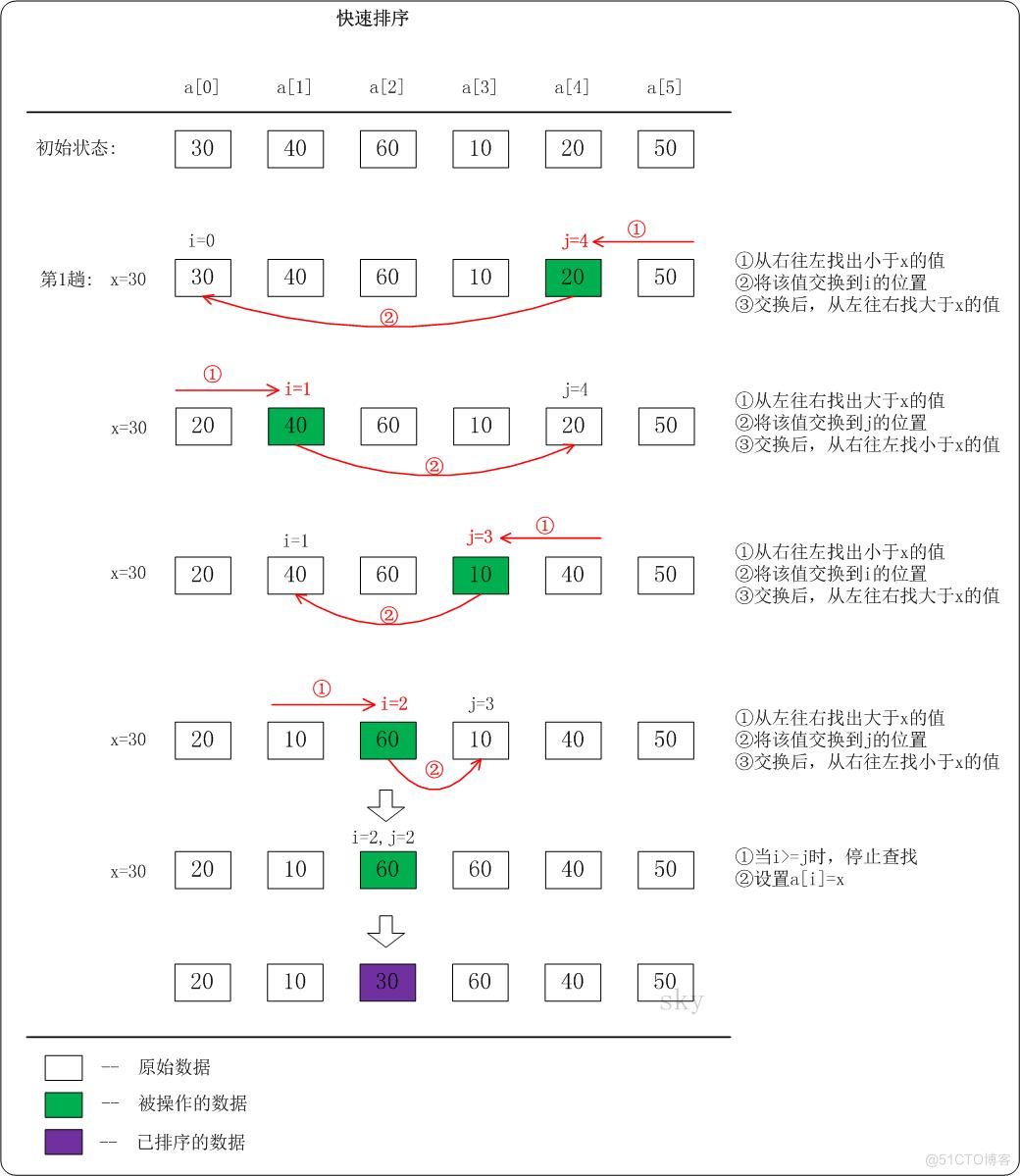
上图只是给出了第1趟快速排序的流程。在第1趟中,设置x=a[i],即x=30。
-
01、从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=20,此时j=4;然后将a[j]赋值a[i],此时i=0;接着从左往右遍历。
-
02、从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=40,此时i=1;然后将a[i]赋值a[j],此时j=4;接着从右往左遍历。
-
03、从"右 --> 左"查找小于x的数:找到满足条件的数a[j]=10,此时j=3;然后将a[j]赋值a[i],此时i=1;接着从左往右遍历。
-
04、从"左 --> 右"查找大于x的数:找到满足条件的数a[i]=60,此时i=2;然后将a[i]赋值a[j],此时j=3;接着从右往左遍历。
-
05、从"右 --> 左"查找小于x的数:没有找到满足条件的数。当i>=j时,停止查找;然后将x赋值给a[i]。此趟遍历结束!
-
按照同样的方法,对子数列进行递归遍历。最后得到有序数组!
三、快速排序分类
快速排序分为:
- 单路快速排序(Lomuto 洛穆托分区方案)
- 双路快速排序(并不完全等价于hoare霍尔分区方案)
- hoare霍尔分区方案
- 三路快速排序
这里介绍单边循环快排(lomuto 洛穆托分区方案)和双边循环快排(并不完全等价于hoare霍尔分区方案)
3.1 单边循环快排(lomuto 洛穆托分区方案)
- 1、选择最右元素作为基准点元素
- 2、j指针负责找到比基准点小的元素,一旦找到则与i进行交换
- 3、i指针维护小于基准点元素的边界,也是每次交换的目标索引
- 4、最后基准点与i元素交换,i即为分区位置
/**
* @Author: huangyibo
* @Date: 2022/1/22 0:09
* @Description: 快速排序——单路快速排序(lomuto 洛穆托分区方案)
* 1、选择最右元素作为基准点元素
* 2、j指针负责找到比基准点小的元素, 一旦找到则与i进行交换
* 3、i指针维护小于基准点元素的边界, 也是每次交换的目标索引
* 4、最后基准点与i元素交换, i即为分区位置
*/
public class QuickSort {
public static <E extends Comparable<E>> void quickSort(E[] arr) {
sort(arr,0,arr.length - 1);
}
public static <E extends Comparable<E>> void sort(E[] arr, int left, int right) {
//当指定区间范围内元素值小于等于1的时候, 停止递归调用
if(left >= right){
return;
}
//pv 基准点的正确索引值
int pv = partition(arr, left, right);
//左边分区的范围确定
sort(arr, left,pv - 1);
//右边分区的范围确定
sort(arr, pv + 1, right);
}
public static <E extends Comparable<E>> int partition(E[] arr, int left, int right) {
//基准点元素
E pivot = arr[right];
int i = left;
for (int j = i; j < right; j++) {
if(arr[j].compareTo(pivot) < 0){
if(i != j){
//i和j不相等的时候才交换元素
swap(arr, i, j);
}
i++;
}
}
if(i != right){
//一轮循环之后,基准点元素和小于基准点元素边界值交换
swap(arr, right, i);
}
//返回值代表了基准点元素所在的正确索引,它确定下一轮分区的边界
return i;
}
public static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {
E temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
注意:
- 此种方案在遇到待排序数组是完全有序或者是同样元素的数组时,性能极速下降,退化为O(n²)
3.2 单路快速排序
随机化快排:使用随机元素作为枢轴
- 1、选择最左元素作为基准点元素
- 2、i指针负责找到比基准点小的元素,一旦找到则与i进行交换
- 3、j指针维护小于基准点元素的边界,也是每次交换的目标索引
- 4、最后基准点与j元素交换,j即为分区位置
/**
* @Author: huangyibo
* @Date: 2022/1/22 0:09
* @Description: 单路快速排序:选择排序区间最左边元素作为基准点元素
*/
public class QuickSort {
public static <E extends Comparable<E>> void quickSort(E[] arr){
Random random = new Random();
sort(arr,0, arr.length - 1, random);
}
/**
* 以基准点元素索引,对数组进行递归调用
* @param arr 待排序数组
* @param left 待排序数组的左边界
* @param right 待排序数组的右边界
* @param random 随机数生成 partition方法使用
* @param <E> 泛型
*/
private static <E extends Comparable<E>> void sort(E[] arr, int left, int right, Random random){
//当指定区间范围内元素值小于等于1的时候, 停止递归调用
if(left >= right){
return;
}
//基准点的正确索引值
int pv = partition(arr, left, right, random);
//左边分区的范围确定
sort(arr,left,pv - 1, random);
//右边分区的范围确定
sort(arr,pv + 1, right, random);
}
/**
* 以左边元素为基准点元素进行分区排序
* 生成[left, right]区间之间的随机数索引pv
* 将left与pv之间的元素交换位置
* 防止在有序数组前提下,
* 快速排序使用最左元素为基准点元素排序,导致排序性能下降的问题
* @param arr 排序数组
* @param left 左边界索引
* @param right 右边界索引
* @param random 随机数生成
* @param <E> 泛型
* @return 返回值代表基准点元素所在的正确索引,用以确定下轮分区的边界
*/
private static <E extends Comparable<E>> int partition(E[] arr, int left, int right, Random random){
//生成[left, right]区间之间的随机数索引
//区间范围的计算方式是: ((最大值 - 最小值 + 1) + 最小值)
int pv = random.nextInt(right - left + 1) + left;
// 这里交换位置的原因在于,在有序数组前提下,
// 快速排序使用最左元素为基准点元素排序,导致排序性能下降
swap(arr, left, pv);
//定义小于基准点元素的边界索引j, 区间即为arr[left+1, j]
int j = left;
//定义当前访问的元素索引i
//大于基准点元素数组区间即为arr[j+1, i]
for (int i = left + 1; i <= right; i++) {
//以左边元素为基准点元素进行分区排序
if(arr[i].compareTo(arr[left]) < 0){
//小于基准点元素的边界索引j先自增
j++;
//然后交换j和i的元素
swap(arr, i, j);
}
}
//一轮循环之后,基准点元素和小于基准点元素边界值元素交换
if(left != j){
//基准点交换
swap(arr, left, j);
}
//返回值代表基准点元素所在的正确索引,用以确定下轮分区的边界
return j;
}
public static <E> void swap(E[] arr, int i, int j) {
E temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
注意:
- 此种方案在遇到待排序是同样元素的数组时,性能极速下降,退化为O(n²)
3.3 双路快速排序(并不完全等价于hoare霍尔分区方案)
- 1、选择最左元素作为基准点元素
- 2、j指针负责从右向左找比基准点小的元素,i指针负责从左向右找比基准点大的元素,一旦找到二者交换,直到i、j相交
- 3、最后基准点与i(此时i与j相等)交换,j即为分区位置
下图为Hoare划分的示意图:

/**
* @Author: huangyibo
* @Date: 2022/1/22 0:09
* @Description: 快速排序——双路快速排序(并不完全等价于hoare霍尔分区方案)
* 1、选择最左元素作为基准点元素
* 2、j指针负责从右向左找比基准点小的元素,i指针负责从左向右找比基准点大的元素, 一旦找到二者交换, 直到i、j相交
* 3、最后基准点与i(此时i与j相等)交换,j即为分区位置
*
* 特点:
* 1、平均时间复杂度是O(n ㏒₂n), 最坏时间内复杂度为O(n²)
* 2、数据量较大时,优势非常明显
* 3、属于不稳定排序算法
*/
public class QuickSort {
public static <E extends Comparable<E>> void quickSort(E[] arr){
sort(arr,0, arr.length - 1);
}
public static <E extends Comparable<E>> void sort(E[] arr, int left, int right) {
//当指定区间范围内元素值小于等于1的时候, 停止递归调用
if(left >= right){
return;
}
//pv 基准点的正确索引值
int pv = partition(arr, left, right);
//左边分区的范围确定
sort(arr, left,pv - 1);
//右边分区的范围确定
sort(arr, pv + 1, right);
}
public static <E extends Comparable<E>> int partition(E[] arr, int left, int right) {
//基准点元素
E pivot = arr[left];
int i = left;
int j = right;
while (i < j){
//j指针负责从右向左找比基准点小的元素, 必须先从右向左找,先执行j指针
while(i < j && arr[j].compareTo(pivot) > 0){
j--;
}
//i指针负责从左向右找比基准点大的元素
while(i < j && arr[i].compareTo(pivot) <= 0){
i++;
}
if(i != j){
//i和j不相等的时候才交换元素
swap(arr, i, j);
}
}
//一轮循环之后, i指针和j指针相交, 基准点元素和j指针(i、j指针相等)元素交换
if(j != left){
swap(arr, left, j);
}
//返回值代表了基准点元素所在的正确索引,它确定下一轮分区的边界
return j;
}
public static <E extends Comparable<E>> void swap(E[] arr, int i, int j) {
E temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
注意:
- 此种方案在遇到待排序数组是完全有序或者是同样元素的数组时,性能极速下降,退化为O(n²)
3.4 双路快速排序——推荐
随机化快排:使用随机元素作为枢轴,并且基于Hoare划分的快速排序算法
- 1、选择最左元素作为基准点元素
- 2、j指针负责从右向左找比基准点小的元素,i指针负责从左向右找比基准点大的元素,一旦找到二者交换, 直到i、j相交
- 3、最后基准点与j(此时i与j相等)交换,j即为分区位置
下图为Hoare划分的示意图:

/**
* @Author: huangyibo
* @Date: 2022/1/22 0:09
* @Description: 双路快速排序:选择排序区间最左边元素作为基准点元素
*/
public class QuickSort {
public static <E extends Comparable<E>> void quickSort(E[] arr){
Random random = new Random();
sort(arr,0, arr.length - 1, random);
}
/**
* 以基准点元素索引,对数组进行递归调用
* @param arr 待排序数组
* @param left 待排序数组的左边界
* @param right 待排序数组的右边界
* @param random 随机数生成 partition方法使用
* @param <E> 泛型
*/
private static <E extends Comparable<E>> void sort(E[] arr, int left, int right, Random random){
//当指定区间范围内元素值小于等于1的时候, 停止递归调用
if(left >= right){
return;
}
//基准点的正确索引值
int pv = partition(arr, left, right, random);
//左边分区的范围确定
sort(arr,left,pv - 1, random);
//右边分区的范围确定
sort(arr,pv + 1, right, random);
}
/**
* 以左边元素为基准点元素进行分区排序
* 生成[left, right]区间之间的随机数索引pv
* 将left与pv之间的元素交换位置
* 防止在有序数组前提下,
* 快速排序使用最左元素为基准点元素排序,导致排序性能下降的问题
* @param arr 排序数组
* @param left 左边界索引
* @param right 右边界索引
* @param random 随机数生成
* @param <E> 泛型
* @return 返回值代表基准点元素所在的正确索引,用以确定下轮分区的边界
*/
private static <E extends Comparable<E>> int partition(E[] arr, int left, int right, Random random){
//生成[left, right]区间之间的随机数索引
//区间范围的计算方式是: ((最大值 - 最小值 + 1) + 最小值)
int pv = random.nextInt(right - left + 1) + left;
// 这里交换位置的原因在于,在有序数组前提下,
// 快速排序使用最左元素为基准点元素排序,导致排序性能下降
swap(arr, left, pv);
int i = left + 1;
int j = right;
while (true){
//i指针负责从左向右找比基准点大的元素
//i <= j 表示区间内还有元素
while(i <= j && arr[i].compareTo(arr[left]) < 0){
i++;
}
//j指针负责从右向左找比基准点小的元素
//i <= j 表示区间内还有元素
while(i <= j && arr[j].compareTo(arr[left]) > 0){
j--;
}
//循环退出条件
if(i >= j){
break;
}
if(i != j){
//i和j不相等的时候才交换元素
swap(arr, i, j);
}
//一轮循环完成之后, i指针--和 j指针++ 作用于循环条件的退出
i++;
j--;
}
//一轮循环之后, i指针和j指针相交(或者j指向小于基准点元素的边界元素), 基准点元素和j指针(i、j指针相等)元素交换
if(j != left){
swap(arr, left, j);
}
//返回值代表了基准点元素所在的正确索引,它确定下一轮分区的边界
return j;
}
public static <E> void swap(E[] arr, int i, int j) {
E temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
3.5 三路快速排序
三平均划分法快排:以最左元素、最右元素、最中间元素的中位数为枢轴
排序的步骤和示意图如下:
- 1、lt指向L的位置,i指向L+1的位置,gt指向r+1的位置
- 2、如果i指向的元素等于V,则i++考察下一个元素
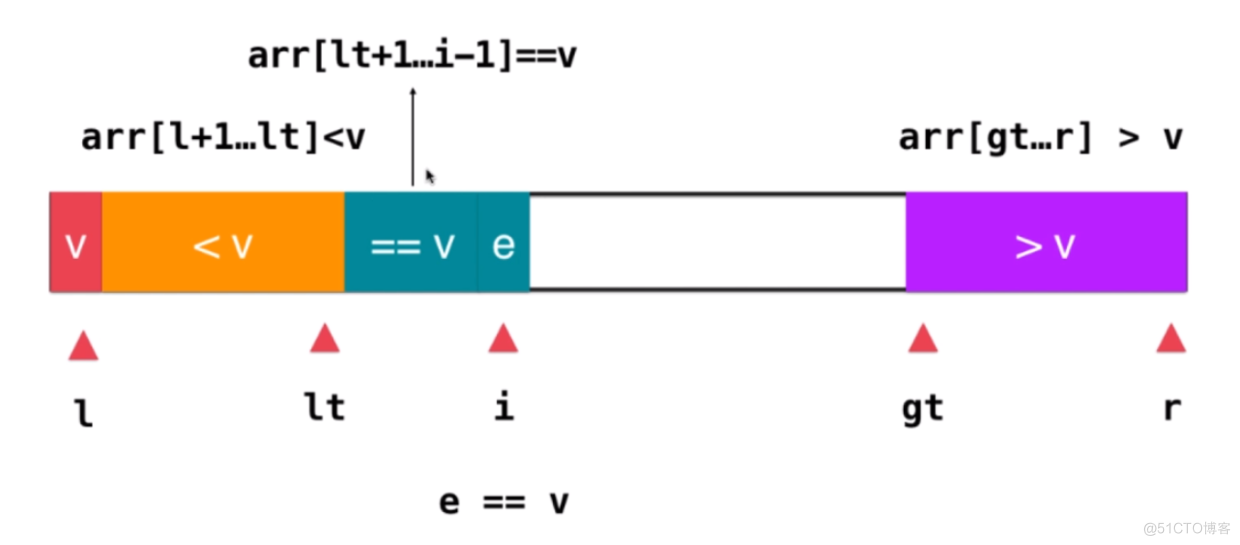
- 3、如果i指向的元素小于V,则交换lt+1与i指向的元素,,然后lt++,并且i++考察下一个元素
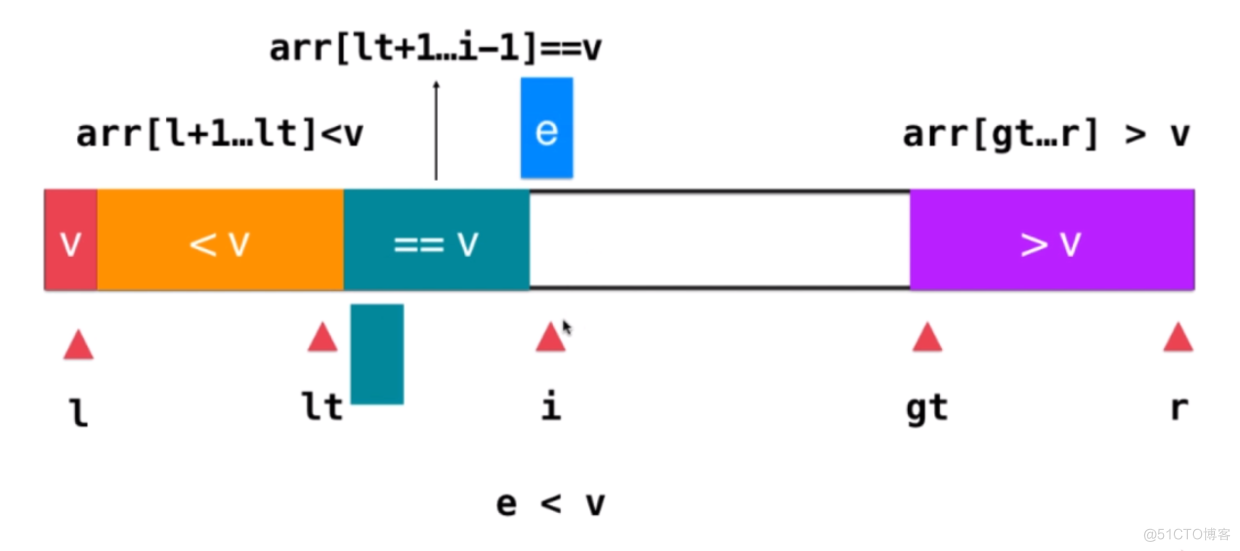
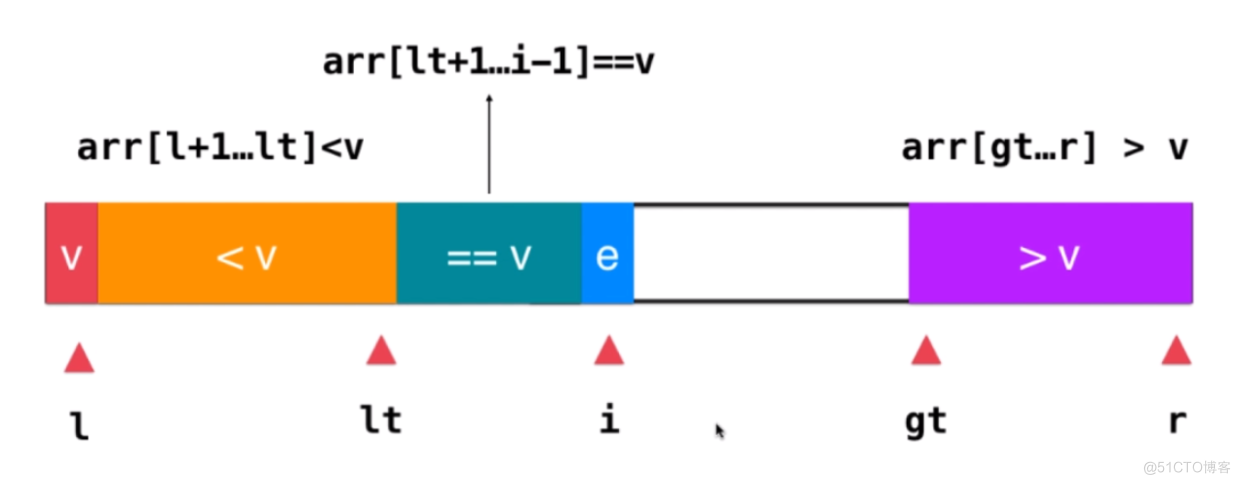
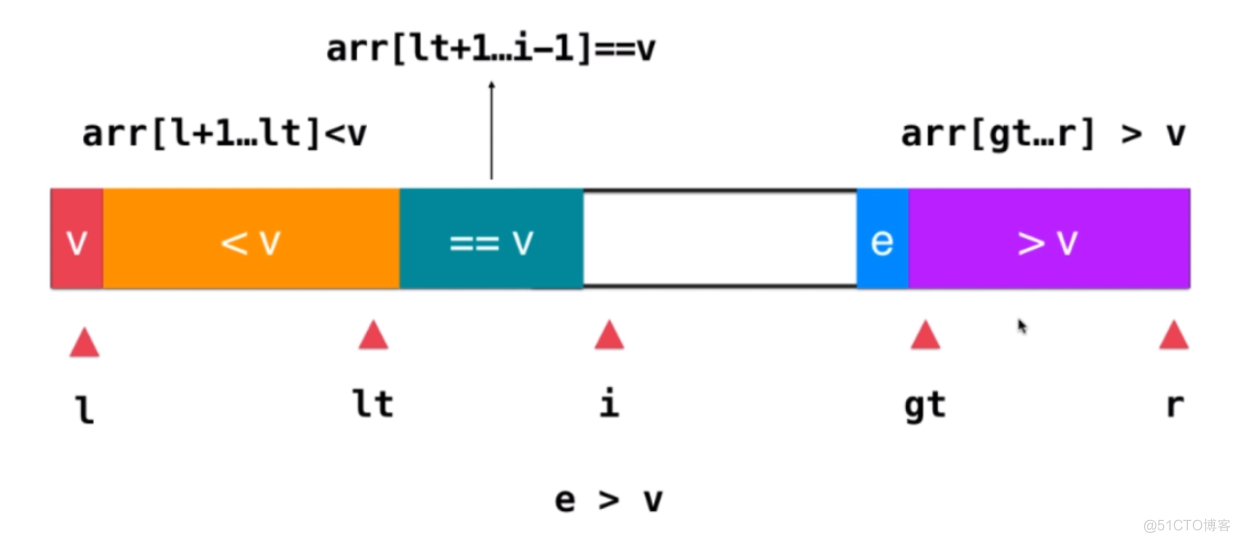
- 4、如果i指向的元素大于V,则交换gt-1与i指向的元素,然后gt--,注意此时i无需自增,因为i指向的是未被处理的元素

- 6、交换L与lt指向的元素,注意交换后lt指向的元素等于V

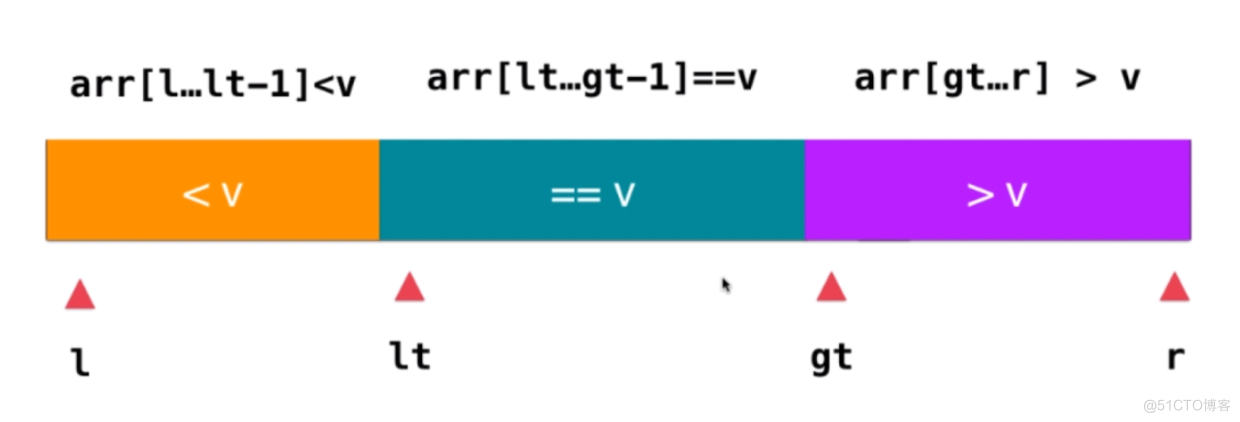
- 7、逐层递归,直到所有的元素有序,注意下次迭代秩序排序[l, lt-1]和[gt, r]两部分,等于V的部分无需再次排序
/**
* @Author: huangyibo
* @Date: 2022/1/22 0:09
* @Description: 三路快速排序
*/
public class QuickSort {
public static <E extends Comparable<E>> void quickSort(E[] arr){
Random random = new Random();
sort(arr,0, arr.length - 1, random);
}
/**
* 以基准点元素索引,对数组进行递归调用
* 三平均划分法快排:以最左元素、最右元素、最中间元素的中位数为枢轴
* @param arr 待排序数组
* @param left 待排序数组的左边界
* @param right 待排序数组的右边界
* @param random 随机数生成 partition方法使用
* @param <E> 泛型
*/
private static <E extends Comparable<E>> void sort(E[] arr, int left, int right, Random random){
//当指定区间范围内元素值小于等于1的时候, 停止递归调用
if(left >= right){
return;
}
//生成[left, right]区间之间的随机数索引
//区间范围的计算方式是: ((最大值 - 最小值 + 1) + 最小值)
int pv = random.nextInt(right - left + 1) + left;
// 这里交换位置的原因在于,在有序数组前提下,
// 快速排序使用最左元素为基准点元素排序,导致排序性能下降
swap(arr, left, pv);
//arr[left + 1, lt] < v, arr[lt + 1, i - 1] == v, arr[gt, right] < v
//定义变量lt, arr[left + 1, lt]区间为小于基准点元素的值
int lt = left;
//定义变量i, arr[lt + 1, i - 1]区间为等于基准点元素的值
int i = left + 1;
//定义变量gt, arr[gt, right]区间为大于基准点元素的值
int gt = right + 1;
//i < gt表示有元素可以遍历比较
while (i < gt){
//arr[left + 1, lt]区间, 小于基准点元素的值区间新增元素
if (arr[i].compareTo(arr[left]) < 0){
lt++;
swap(arr, i, lt);
i++;
}else if (arr[i].compareTo(arr[left]) > 0){
//arr[gt, right]区间, 大于基准点元素的值区间新增元素
gt--;
swap(arr, i, gt);
//注意这里i不++, 因为i的值从数组的gt位置交换而来,gt的值尚未进行比较
}else{
//arr[lt + 1, i - 1]区间为等于基准点元素的值,不用交换位置,i++即可
i++;
}
}
//循环完一轮后,将基准点元素的值归入等于基准点元素值的区间
swap(arr, left, lt);
//循环完一轮后现在的区间值范围
//arr[left, lt - 1] < v, arr[lt, gt - 1] == v, arr[gt, right] < v
//左边分区的范围确定
sort(arr,left,lt - 1, random);
//右边分区的范围确定
sort(arr,gt, right, random);
}
public static <E> void swap(E[] arr, int i, int j) {
E temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
3.3 快速排序特点
- 1、平均时间复杂度是O(n ㏒₂n), 最坏时间内复杂度为O(n²)
- 2、数据量较大时,优势非常明显
- 3、属于不稳定排序算法
参考:
https://www.cnblogs.com/onepixel/articles/7674659.html
https://www.cnblogs.com/skywang12345/p/3596746.html