一、什么是栈
栈是一种特殊的线性表,它只允许在固定的一端进行插入和删除的操作。
对数据进行插入和删除的一端叫做栈顶,另一端是栈底。
对栈的两项操作分别叫做入栈、出栈。
入栈就是对栈进行插入操作,除此之外,入栈也叫做进栈、压栈。
出栈就是对栈进行删除的操作。
不管是入栈的数据还是出栈的数据都在栈顶。
栈的元素数据遵循后进先出(Last In First Out)的原则,即后进入的数据先出来。
以下是栈以及栈的操作的一张示意图:
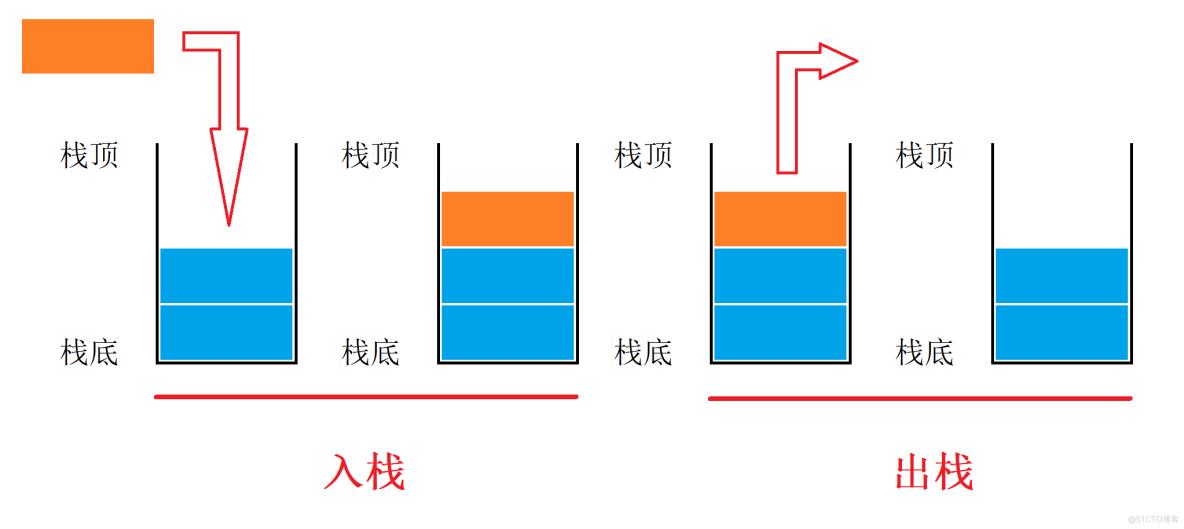
如果一组数据的入栈顺序为1234
那么它的出栈顺序可能为
4321
1234
2134
······
二、缓存利用率
栈可以用顺序表实现,也可以用链表来实现。
但是,顺序表的缓存利用率更高,链表的缓存利用率低于顺序表。
结构上来说顺序表物理上是连续的,链表是一个一个的节点。
众所周知计算机的存储体系是分级的,CPU的速度远远大于RAM的速度,所以在CPU和RAM之间会有三级的缓存和寄存器。
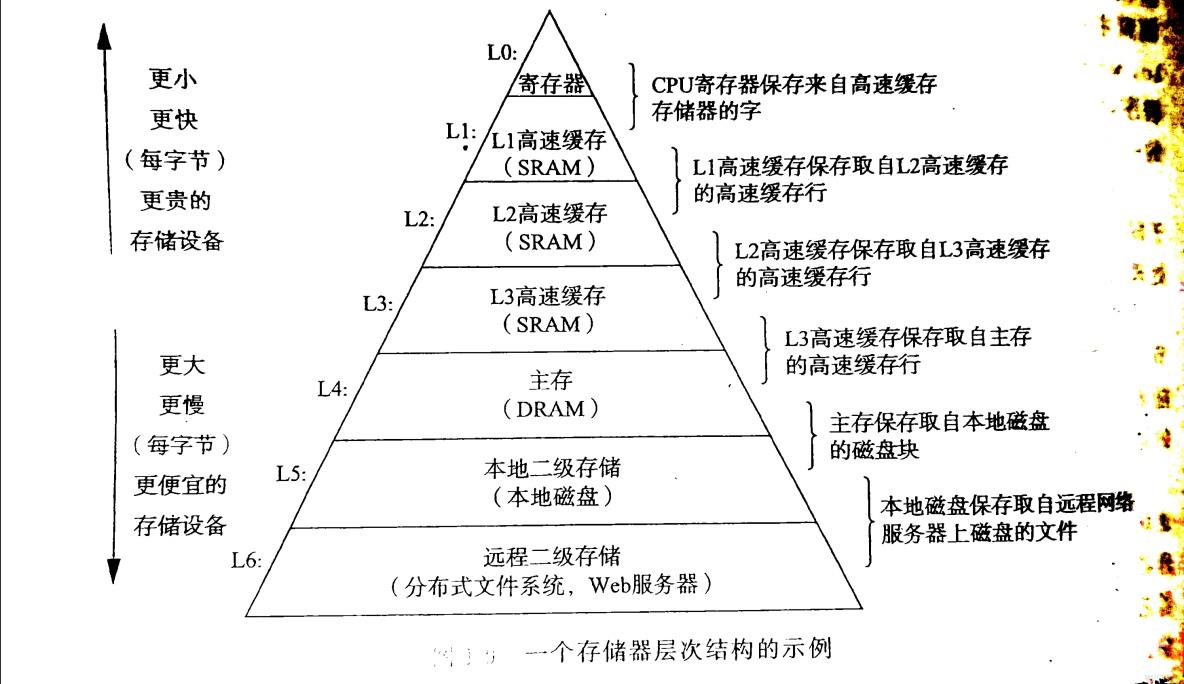
如果现在分别对顺序表和链表进行遍历访问或是修改数据,这时是CPU对这些数据进行访问,也就是说CPU要访问内存。
CPU要想对内存进行访问,会先去访问缓存,如果数据在缓存中就访问了数据。如果数据不在缓存中,那么内存中的数据会先进入缓存再供CPU访问。由于缓存大小有限,当数据量很大时,大概率不会一下将内存中的数据放入缓存。
那为什么这两种数据结构的缓存利用率不同呢?
就是因为,内存的数据在进入缓存时,不会只传递将要访问的数据,而是,会加载更多的数据。
假如现在最开始的数据都不在缓存,那么内存中的数据在加载到缓存中时,如图所示:
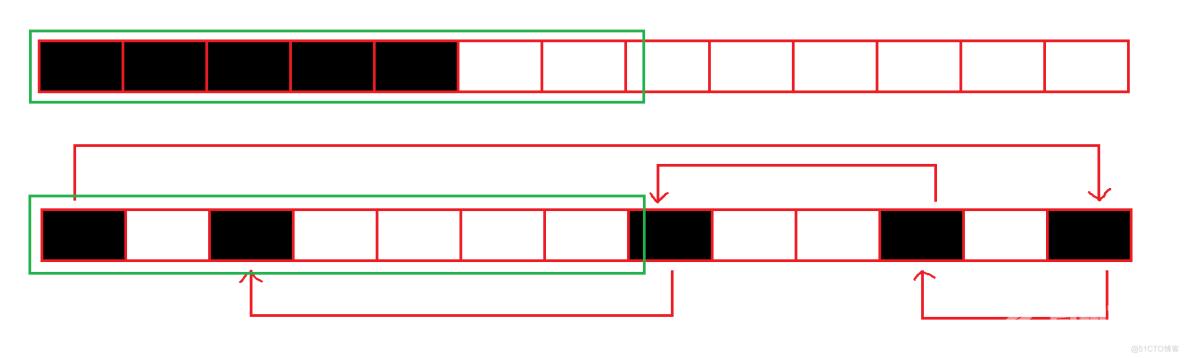
绿色的方框代表能被一次加载的数据可以看到,顺序表中的数据都成功加载到了缓存,而链表中的数据没有被完全加载到缓存中,要将链表中的数据完全加入到缓存中,还要再来。
因为顺序表的数据是物理连续存储的,而链表的数据是一个一个节点的存储的,它们不连续。
所以说顺序表的缓存利用率比链表的缓存利用率高。
三、栈的实现
那么,要实现栈是用顺序表好还是链表好?
可以用顺序表实现,但是要考虑扩容。也可以用链表来实现。
但是,在了解了顺序表和链表的缓存利用率后,我们也许会优先选择使用顺序表。
这里选择用顺序表实现栈。
定义栈以及栈的数据类型:
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;栈的初始化:
void STInit(ST* ps)
{
assert(ps);
ps->a = (STDataType*)malloc(sizeof(STDataType) * 4);
if (ps->a == NULL)
{
perror("malloc fail");
return;
}
ps->capacity = 4;
ps->top = 0; // top是栈顶元素的下一个位置
//ps->top = -1; // top是栈顶元素位置
}注意这里top可自定义,注释有说明。
入栈:
void STPush(ST* ps, STDataType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
STDataType* tmp = (STDataType*)realloc(ps->a,
sizeof(STDataType) * ps->capacity*2);
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity *= 2;
}
ps->a[ps->top] = x;
ps->top++;
}出栈:
void STPop(ST* ps)
{
assert(ps);
assert(!STEmpty(ps));
ps->top--;
}栈的销毁:
void STDestroy(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = 0;
ps->capacity = 0;
}栈的大小:
int STSize(ST* ps)
{
assert(ps);
return ps->top;
}取栈顶元素:
STDataType STTop(ST* ps)
{
assert(ps);
assert(!STEmpty(ps));
return ps->a[ps->top - 1];
}判断栈是否为空:
bool STEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}如果是C语言实现要引用stdbool头文件。