文库复杂度对应的英文如下 Library Complexity 表示的是文库中unique的分子数目,unique分子数目越多,文库复杂度越高。在数据分析中,重复序列会对下游分析造成影响,在snp calling, peak c
文库复杂度对应的英文如下
Library Complexity
表示的是文库中unique的分子数目,unique分子数目越多,文库复杂度越高。在数据分析中,重复序列会对下游分析造成影响,在snp calling, peak caling等分析前都需要去除文库中的重复序列。
只有一个复杂度高的文库,才能确保挖掘出更多有效的信息,所以在数据分析中,需要对文库的复杂度进行评估。本文主要介绍下通过picard这个工具来评估文库复杂度,用法如下
java -jar picard.jar \EstimateLibraryComplexity \
I=input.bam \
O=lib_complex_metrics.txt
基本用法非常简单,只需要指定输入输出即可,输入文件为比对产生的bam文件,输出文件记录了文库复杂度信息,其内容如下
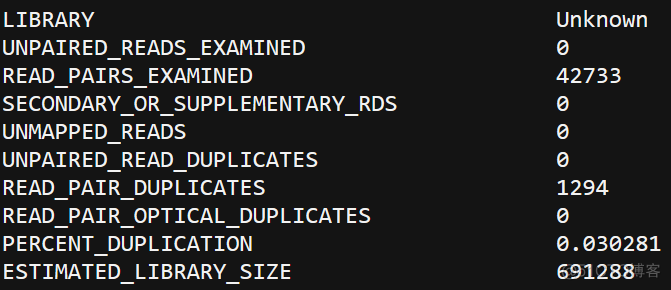
为了方便展示,这里我截取了部分重点内容并进行了转置,其中有3个指标识别需要重点关注
通过序列数和重复序列数,有对应的公式来计算unique分子数目,公式如下

其中N表示bam文件中的序列数,C表示bam文件中的unique序列数,用序列数减去重复序列数即可得到,N就是文库中unique分子数目,即library size。
·end·

一个只分享干货的
生信公众号