人工神经网络由多层神经元构成,对于单个神经元而言,首先对接收到的输入信号进行线性组合,示意如下
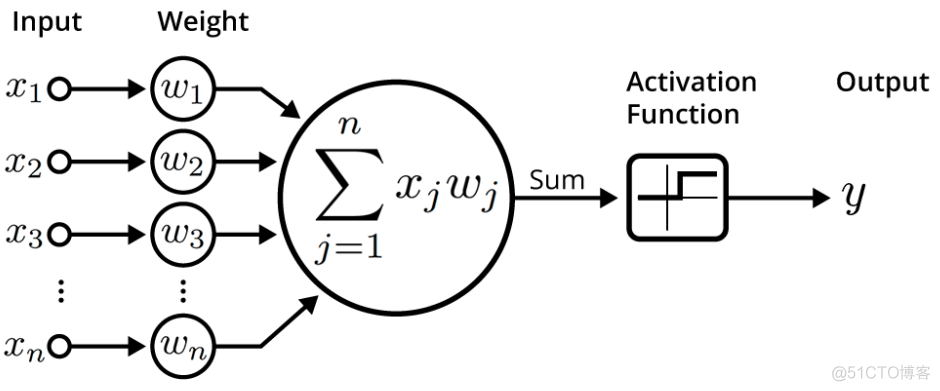
但是在输出信号时,会使用一个称之为激活函数的函数对线性组合的信号进一步处理。激活函数是一种非线性函数,由多种具体的函数表达式。
为何一定需要激活函数呢?如果没有激活函数的话,神经元的信号处理本质上就是一个线性组合,即使叠加再多层的神经元,整个神经网络也还是线性组合,这样就不能解决非线性的问题,所以激活函数的作用,是为神经网络引入非线性组合的能力,使其可以适用于复杂的应用场景。
激活函数由多种,下面介绍几种常用的激活函数
1. Sigmod
就是逻辑回归中的sigmod函数,函数图像如下
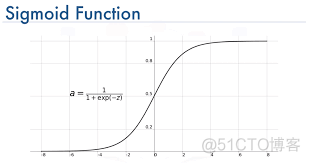
取值范围为0到1,sigmod是最常用的激活函数之一,作为最早使用的激活函数,在神经网络发展的早期最为常用,但是该函数存在着以下两个缺点。
神经网络通过基于梯度下降的反向传播算法来训练参数,在反向的过程中,需要借助链式法则来计算梯度
对于sigmod函数而言,其导函数的取值都很小,导函数的图像如下
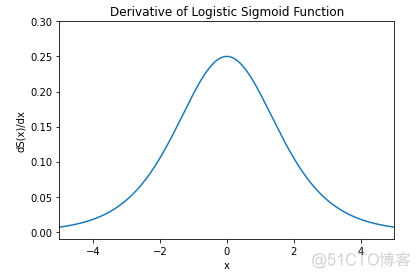
最大值0.25,这样在链式法则的连乘过程中,会使得梯度很快趋近于0,这种现象称之为梯度消失kill gradients。研究表明,对于5层以上的神经网络,特别容易出现梯度消失,所以sigmod函数对于层数很多的深度神经网络效果不太好。
其次,sigmod函数的输出值恒大于0,即not zero-centered, 这样在梯度下降的过程中只能按照下图所示的路径来收敛
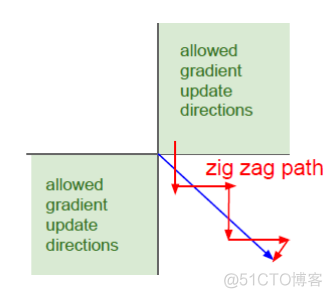
收敛速度较慢,神经网络参数非常多,收敛速度慢会大大增加模型的训练时长。
2. Tanh
Tanh函数的图像如下
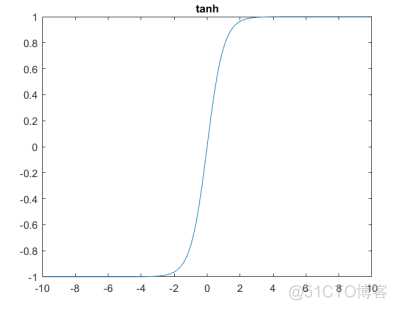
相比sigmod函数,tanh函数输出范围为-1到1,是zero-centered, 所以收敛速度有所提高。
但是本质上该函数其实是sigmod的变体
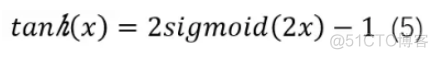
所以与sigmod函数一样,该函数也会出现梯度消失的问题。
3. ReLU
ReLU是Rectified Linear Unit的缩写,简称修正线性单元,函数表达式如下
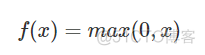
函数图像如下
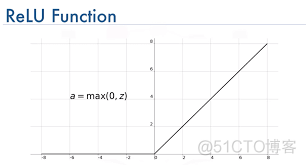
ReLU函数的求导很简单
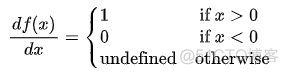
而且在x>0的区间,不会梯度消失的现象,使得其性能比sigmod和tanh好很多,收敛速度更快,但是ReLU函数也有一个缺点。
ReLU函数对于负数,其导数为0,此时会出现神经元的参数永远无法更新的情况,推导过成如下
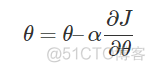
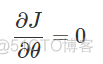
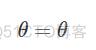
称之为神经元死亡,造成这种现象的原因由两个,第一种是在初始化参数时出现负值,第二种是学习率设置较大,导致参数更新幅度太大,出现负值。
所以在使用ReLU时,对学习率的设置要注意,需要一个合适的较小的学习率。
4. PReLU
全称是Parametric Relu, 是ReLU的改进版,函数表达式如下
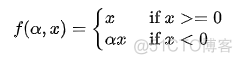
针对ReLU负数为0的情况,在负数部分,设置了斜率α,当α取值为0.01时,激活函数称之为Leaky Relu, 函数图像如下
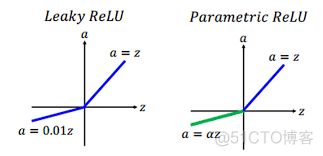
PReLU克服了ReLU会出现的神经元死亡问题,但是超参数α需要根据先验知识人工设置。
5. ELU
ELU是Exponential Linear Unit的缩写, 简称指数线性单元,函数表达式和图像如下
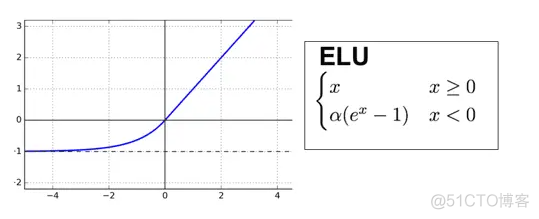
和PReLU类似,也定义了超参数α,对负数部分进行修正,不同的是这里不在是PReLU中的线性关系,而是一个指数关系。
该函数也避免了神经元死亡的问题,同样的超参数α需要根据先验知识人工设置,而且其求导运算比PReLU速度慢。
6. softplus
该函数是ReLU的一种平滑版本,表达式如下
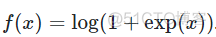
函数图像如下
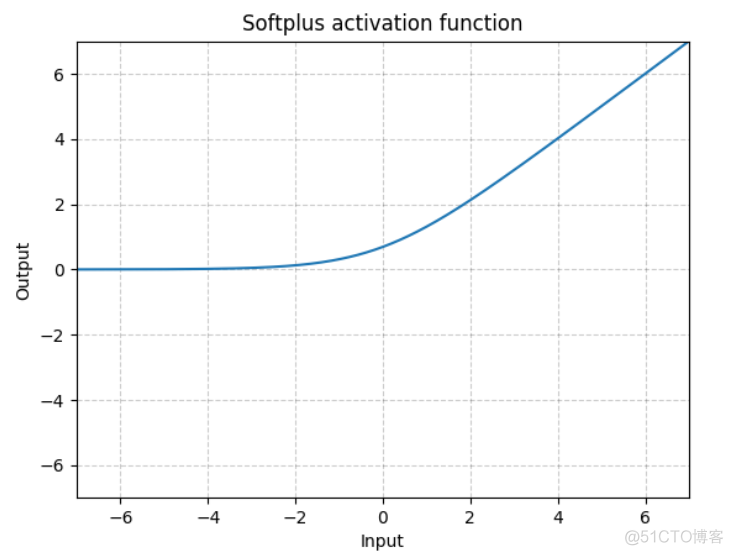
相比ReLU,该函数出现神经元死亡的概率更小。
7. softsign
函数表达式如下
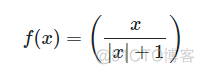
和tanh函数图像非常相似,图像如下
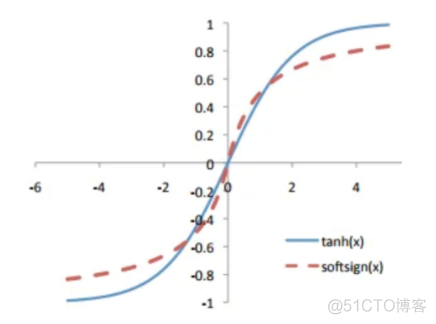
可以看作是tanh的替代品,梯度消失的概率会降低。
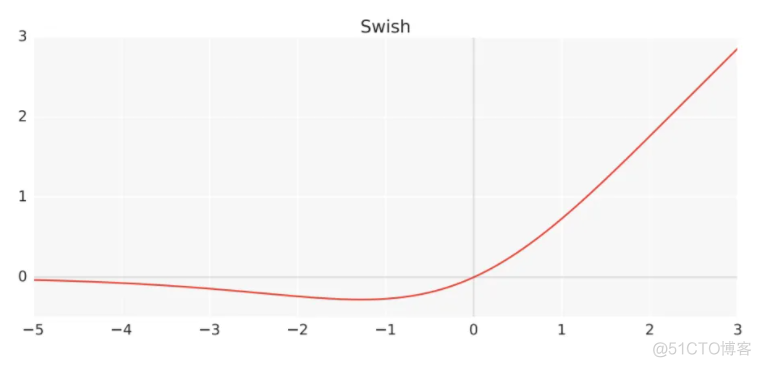
8. swish
同样属于ReLU的改进版,函数表达式如下
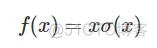
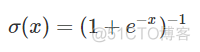
图像如下
上述几种激活函数用于隐含层神经元的输出处理,除此之外,还有两种特殊的激活函数,针对输出层的神经元,简介如下
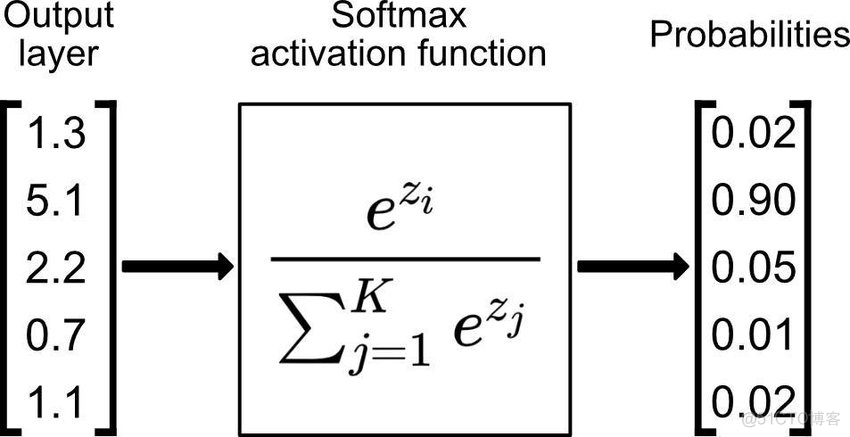
1. softmax
专门用于处理多分类问题,在神经网络的输出层之后,在添加一个softmax层,示意如下
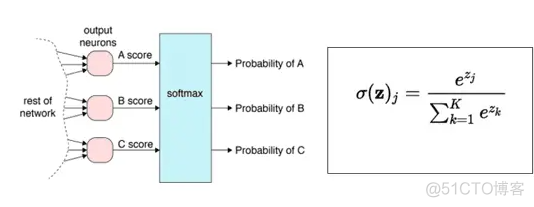
通过softmax函数,将神经元的输出值转换为概率,示意如下
2. MaxOut
maxout是由人为设定的K个神经元构成的一层神经元,示意如下
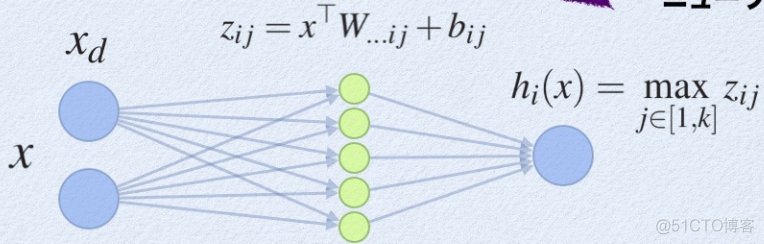
对于maxout层的输出,取k个神经元输出值的最大值作为最终的输出值,这就是maxout的含义。maxout可以看作是分段的线性函数,可以拟合任意的凸函数,提供模型的拟合能力。
引入maxout层,意味着额外增加了一层权重和参数,使得神经网络整体的参数变多,计算量更大。
·end·

一个只分享干货的
生信公众号