自然语言处理是神经网络的经典应用领域之一,所谓自然语言处理,就是让机器理解人类的语言,英文为Natural Language Processing, 简称NLP,是人工智能的一个重要方向,目前生活中已经有很多基于NLP的技术应用了,比如苹果手机的siri, 可以从语音中提取关键信息,然后自动化的执行某些操作,再或者百度翻译,可以自动翻译不同类型的语言,这些应用的核心都涉及NLP相关技术。
NLP的应用有多种类型,常见的应用包括以下几种
1. 分词,将一段文本分割成具有语义的最小单位,即单词,不同的语言有不同的基本词汇,不同的语法,所以分词是一项挑战性的任务
2. 词义消歧,在自然语言中,不同的语境中同一个单词会有不同的含义,词义消歧就是在同一个单词的多个含义中选出符合语境的正确的含义
3. 命名实体识别,从给定的文本中提取实体,所谓实体就是诸如人物,地点,公司,组织等名词
4. 词性标记,就是将一个单词划分为名词,动词,形容词,副词等不同词性中的一类
5. 句子分类,理解一段话表达的意思是正面还是反面的,比如电影评论,要区分是好评还是差评,可以看作一个分类任务
6. 语言生成,基于一个文本库,可以生成新的文本,比如通过金庸的武侠小说作为训练,让计算机自动生成金庸风格的武侠小说
7. 问答系统,典型应用就是苹果的siri语音助手,可以直接回答和解决用户的问题
8. 机器翻译,从一种语言翻译成另一种语言,就要求计算机先理解其含义,在用另一种语言进行表示
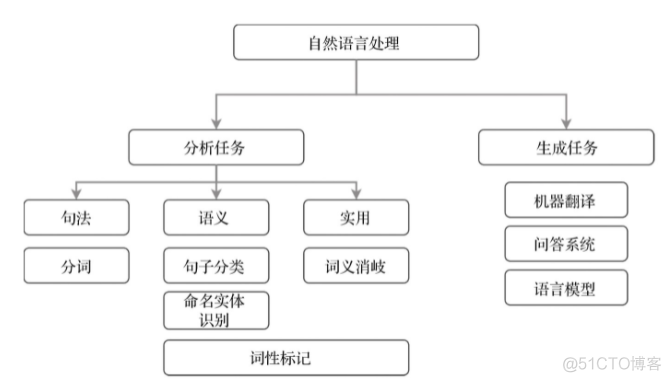
上面这些任务可以分为分析任务和生成任务两大类,图示如下
要计算机处理自然语言,首先要做的就是用合适的数据来表示文本。在早期阶段,自然语言处理通过采用机器学习的方式来训练模型,文本表示的方式也类似机器学习中的特征工程,常用的策略有以下两种
1. bag of words
中文翻译成"词袋", 是一种根据单词出现的频率来表示文本的策略,比如对于以下两段文本

首先提取文本中所有的单词构成一个词汇表

基于词汇表,用每个单词出现的频数来表示对应的文本,结果如下
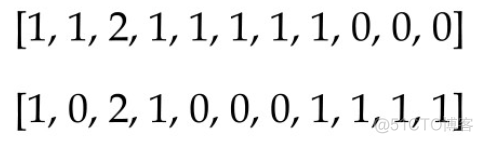
除了单词出现的次数,还可以有其他的编码方式,比如用单词出现与否,0表示未出现,1表示出现,这种方式称之为ont-hot,即独热编码;也可以采用TF-IDF的策略,其中TF称之为词频,IDF称之为逆文档频率,是一种对单词频率进行加权的方法,公式如下

一个单词的重要性与其在当前文本中出现的次数成正比,同时与它在所有文本中出现的次数成反比,这两个概念分别对应了TF和IDF, 具体的公式如下

通过这样的加权方式,可以保证文本中特异性的高频单词的权重值较大,有利于提取关键词。
以上几种编码方式都属于词袋的策略,基于这种策略,有几个问题,首先是维度的问题,文本越多的时候,词汇表会迅速增长,英文单词的总量在千万级别,就会导致维度的大量增加,从而导致维度灾难;其次这样构建的向量大部分为稀疏向量,就是很多部分的值为0,这样向量的相似性不好衡量语句的相似性;最后是这种处理方式,完全不考虑语言的上下文关系,丢失了语义。
2. n-gram
n表示任意的正整数,比如以2为例,下面这段化的2-gram词汇表如下
这种方式在处理大型的词汇表时,可以通过字母的组合减少冗余,构建的词汇表比单词级别的小。后续处理和词袋的策略是一样的。
基于特征工程的机器学习方式,在预处理阶段需要人工设计特征,而且在特征构建的过程中会丢失潜在的有用信息,这不免对模型的效果造成影响。在某些应用领域,还需要人工花费大量时间来构建数据库,比如机器翻译的规则库,这些因素都限制了机器学习在自然语言处理领域发光发热。
随着深度学习的出现,以多层深度神经网络的训练来代替人工的特征工程,不仅解放了人工,而且模型的效果也更好,所以深度学习在自然语言处理等领域大方异彩。
随着不断发展,深度学习在NLP领域渐渐涌现处了多种经典的模型和方法,比如.循环神经网络RNN和长短期记忆网络LSTM,在后面的文章中会进行详细介绍。
·end·

一个只分享干货的
生信公众号